推荐
专栏
教程
课程
飞鹅
本次共找到3965条
spark源码分析
相关的信息
个推技术实践
•
4年前
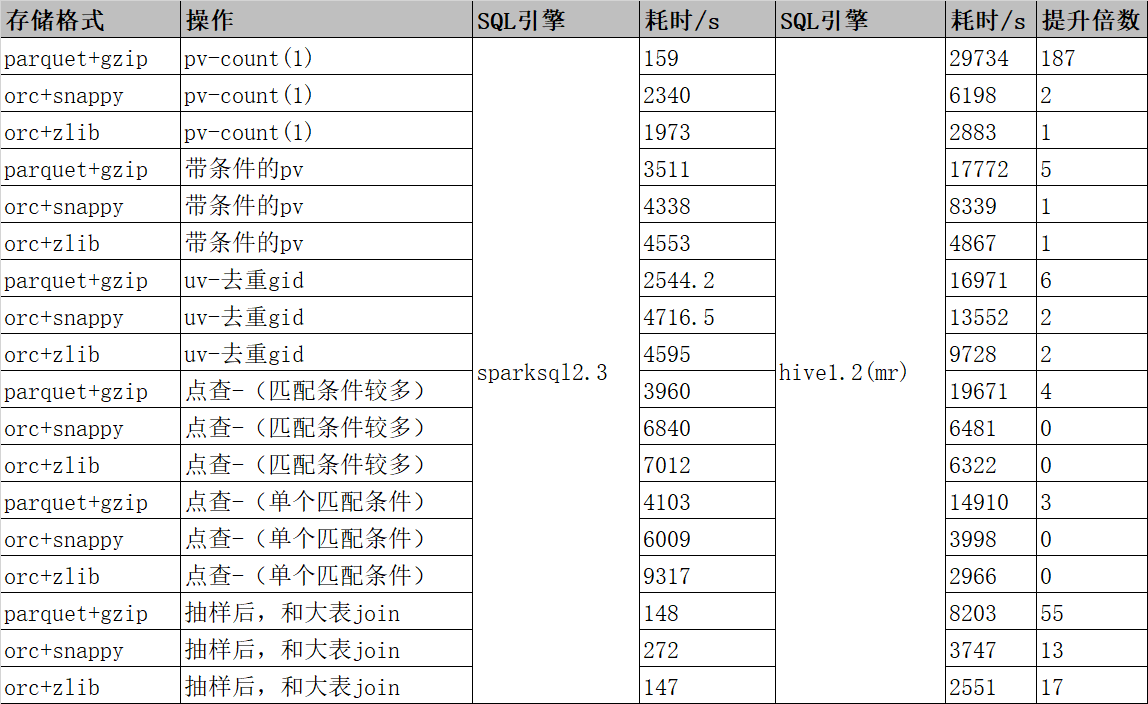
个推分享Spark性能调优指南:性能提升60%↑ 成本降低50%↓
前言Spark是目前主流的大数据计算引擎,功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,应用范围与前景非常广泛。作为一种内存计算框架,Spark运算速度快,并能够满足UDF、大小表Join、多路输出等多样化的数据计算和处理需求。作为国内专业的数据智能服务商,个推从早期的1.3版本便引入Spark,
cpp加油站
•
4年前
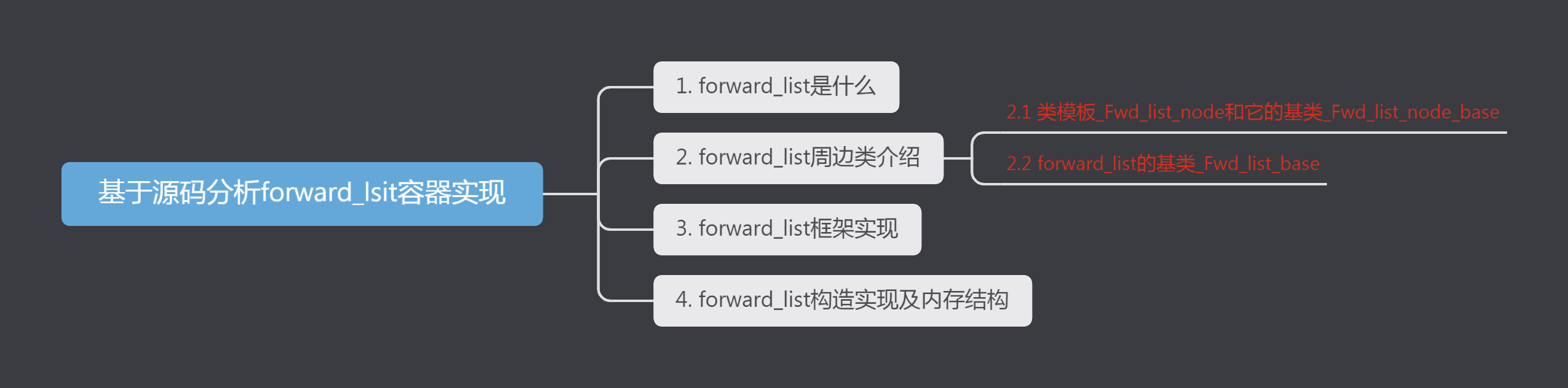
【STL源码拆解】基于源码分析forward_lsit容器实现(详细!)
本篇文章介绍一下c11中新增的顺序容器forwardlist,基于stl的源码分析一下该容器的整体实现及数据结构。说明一下,我用的是gcc7.1.0编译器,标准库源代码也是这个版本的。按照惯例,还是先看一下本文大纲,如下:1.forwardlist是什么forwardlist是c11为STL新增加的一种顺序容器,使用的时候包含头文件forwar
Stella981
•
4年前
Spark Graphx
Graphx 概述 SparkGraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求。 众所周知·,社交网络中人与人之间有很多关系链,例如Twitter、Facebook、微博和微信等,这些都是大数据产生的地方都需要图计算,现
Stella981
•
4年前
Kafka 自定义指定消息partition策略规则及DefaultPartitioner源码分析
Kafka自定义指定消息partition策略规则及DefaultPartitioner源码分析一.概述kafka默认使用DefaultPartitioner类作为默认的partition策略规则,具体默认设置是在ProducerConfi
Stella981
•
4年前
Selenium3源码之初识篇
点击上方蓝字“开源优测”一起玩耍!(https://oscimg.oschina.net/oscnet/6bd8fbaffbc748ff92911e10bb4253fd.jpg)Selenium3Python3源码分析系列以短文方式进行分享阅读源码是掌握Selenium的最好方式我的公众号:开
Stella981
•
4年前
Spring5.0源码深度解析之SpringBean的Aop源码分析
!(https://gss1.bdstatic.com/vo3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign0c730b84bd19ebc4c078719fba1da8c1/37d12f2eb9389b503a80d4b38b35e5dde6116ed7.jpg)SpringAop源码分析
Stella981
•
4年前
Spark Streaming(5):Spark Window function in Java
首先,看下window函数的图解:!(https://static.oschina.net/uploads/space/2017/0810/172732_McZi_1386672.png)下面这个代码是计算一分钟之内的单词数量统计,每两秒获取一次数据,同时处理数据时间也是两秒,窗口大小为1分钟1.数据源packagecom.ss
Stella981
•
4年前
Spark OneHotEncoder
1、概念独热编码(OneHotEncoding) 将表示为标签索引的分类特征映射到二进制向量,该向量最多具有一个单一的单值,该单值表示所有特征值集合中特定特征值的存在。此编码允许期望连续特征(例如逻辑回归)的算法使用分类特征。对于字符串类型的输入数据,通常首先使用StringIndexer
个推技术实践
•
3年前
个推基于Flink SQL建设实时数仓实践
作为一家数据智能企业,个推在服务垂直行业客户的过程中,会涉及到很多数据实时计算和分析的场景,比如在服务开发者时,需要对App消息推送的下发数、到达数、打开率等后效数据进行实时统计;在服务政府单位时,需要对区域内实时人口进行统计和画像分析。为了更好地支撑大数据业务发展,个推也建设了自己的实时数仓。相比Storm、Spark等实时处理框架,Flink不仅具有高吞
京东云开发者
•
2年前
如何正确使用 ThreadLocal,你真的用对了吗? | 京东云技术团队
本文主要从源码的角度解析了ThreadLocal,并分析了发生内存泄漏的原因及正确用法,最后对它的应用场景进行了简单介绍。
1
•••
18
19
20
•••
397