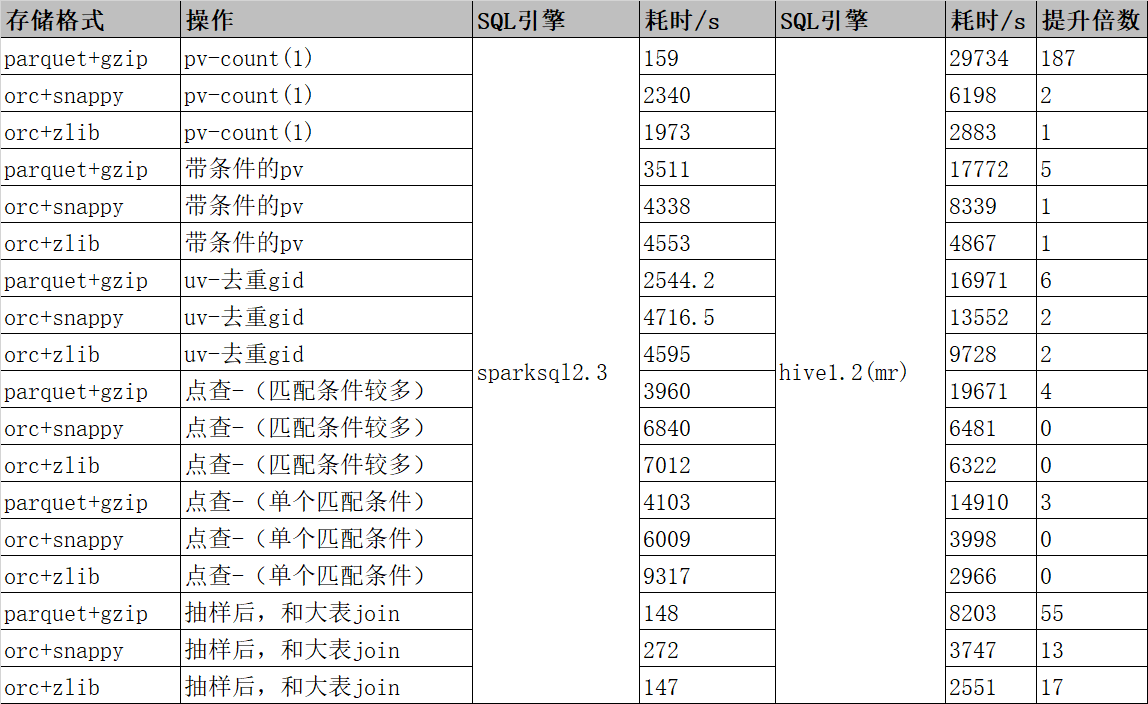
作为一家数据智能企业,个推在服务垂直行业客户的过程中,会涉及到很多数据实时计算和分析的场景,比如在服务开发者时,需要对App消息推送的下发数、到达数、打开率等后效数据进行实时统计;在服务政府单位时,需要对区域内实时人口进行统计和画像分析。为了更好地支撑大数据业务发展,个推也建设了自己的实时数仓。相比Storm、Spark等实时处理框架,Flink不仅具有高吞吐、低延迟等特性,同时还支持精确一次语义(exactly once)、状态存储等特性,拥有很好的容错机制,且使用门槛低、易上手、开发难度小。因此,个推主要基于Flink SQL来解决大部分的实时作业需求。

目前个推主要使用3种方式进行Flink作业:Zeppelin模式、Jar模式和SQL模式。相比另外两种模式,使用SQL模式进行Flink作业,虽然更为简单、通用性也更强,但是在性能调优方面,却存在较大难度。本文将个推Flink SQL使用和调优经验进行了总结,旨在帮助大家在基于Flink SQL进行实时计算作业时少走弯路、提升效率。
个推Flink SQL使用现状
在SQL模式下,个推通过jar+SQL文件+配置参数的方式使用Flink。其中jar是基于Flink封装的执行SQL文件的执行jar,提交命令示例如下:
-c ${mainClassName} \
${jarPath} \
--flink.parallelism 40 \
--mode stream \
--sql.file.path ${sqlFile}SQL文件内容示例如下:
ts bigint,
username string,
num bigint
) with (
'connector' = 'kafka',
'topic' = 'test',
'properties.bootstrap.servers' = '',
'properties.group.id' = 'test-consumer001',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv'
)
create table sink_table(
ts bigint,
username string,
num bigint
) with (
'connector' = 'kafka',
'topic' = 'test2',
'properties.bootstrap.servers' = '',
'format' = 'json'
)
insert into sink_table select * from kafka_table在将原有的Spark Streaming实时计算任务改造成SQL的过程中,我们发现了许多原生Flink SQL无法支持的需求,比如:
写hbase指定时间戳:原生Flink SQL写hbase的时间戳无法由数据时间指定。
写hbase支持数据字段指定qualifier:原生Flink SQL注册hbase表时就需要指定qualifier,无法使用数据字段的值作为qualifier。
中间表注册:目前注册表只能调用table api实现。
kafka source数据预截断:由于业务原因,部分数据源写入kafka的数据默认增加指定前缀,解析前需要预截断。
kafka schema不匹配:由于业务原因,上游写入csv格式数据前会追加字段,导致和schema不匹配,数据无法解析。
针对以上大部分场景,我们均结合业务特色需求,对Flink SQL进行了拓展适配。本文从中间表注册入手,分享Flink SQL正确使用姿势。
Flink中SQL的处理流程
为了帮助大家更好地理解中间表注册问题,我们先整体梳理下Flink中SQL的执行逻辑,如下图:
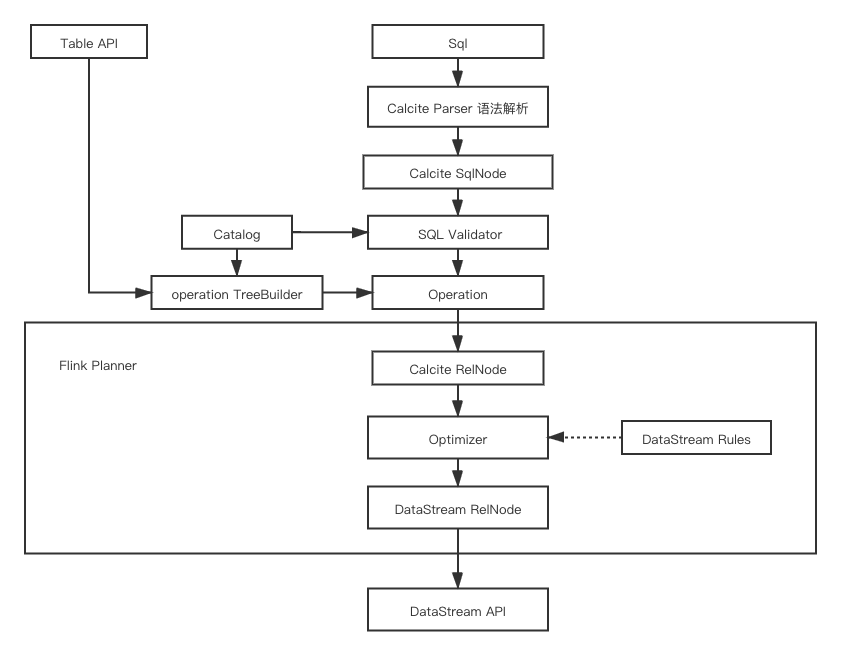
整个流程可以大致拆解为以下几个步骤:
1、SqlParser解析阶段(SQL -> SqlNode)
Flink的Calcite使用JavaCC,根据Parser.jj生成SqlParser(实际类名为SqlParserImpl)。SqlParser负责将SQL解析为AST语法树,数据类型为SqlNode。
2、Validator验证阶段
第一阶段后生成的AST树中,对字段、函数等并没有进行验证。第二阶段会进行校验,校验内容包括表名、字段名、函数名、数据类型等。
3、逻辑计划(SqlNode -> RelNode/RexNode)
经过语法校验的AST树经过SqlToRelConverter.convertQuery调用,将SQL转换为RelNode,即生成逻辑计划LogicalPlan。需要注意的是,Flink为了统一“table api”和“sql执行”两种方式,会在这个阶段将RelNode封装成Operation。
4、优化器(RelNode -> LogicalNode -> ExecNode)
优化器的作用是将关系代数表达式(RelNode)转换为执行计划,用于执行引擎执行。优化器会使用过滤条件的下压、列裁剪等常见的优化规则进行优化,以生成更高效的执行计划。
Flink主要使用Calcite的优化器,采用HepPlanner和VolcanoPlanner这两种优化方式进行优化。
HepPlanner: 是基于规则优化(RBO)的实现,它是一个启发式的优化器,按照规则进行匹配,直到达到次数限制(match 次数限制)或者遍历一遍后不再出现rule match的情况才算完成。
VolcanoPlanner: 是基于成本优化(CBO)的实现,它会一直迭代rules,直到找到cost最小的plan。
需要注意的是,在调用规则优化前,Flink会有一个内部的CommonSubGraphBasedOptimizer优化器用于提取多个执行计划的共用逻辑。CommonSubGraphBasedOptimizer是Flink对于多流场景(常见为多个insert)的优化器,主要作用是提取共用的逻辑,生成有向无环图,避免对共用逻辑进行重复计算。
根据运行环境不同(批和流式),CommonSubGraphBasedOptimizer优化器有BatchCommonSubGraphBasedOptimizer和 StreamCommonSubGraphBasedOptimizer两种实现方式。从执行结果来看,CommonSubGraphBasedOptimizer优化类似于 Spark表的物化,最终目的都是避免数据重复计算。
源码中RelNodeBlock类注释很形象地描述了优化效果:
* val sourceTable = tEnv.scan("test_table").select('a, 'b, 'c)
* val leftTable = sourceTable.filter('a > 0).select('a as 'a1, 'b as 'b1)
* val rightTable = sourceTable.filter('c.isNotNull).select('b as 'b2, 'c as 'c2)
* val joinTable = leftTable.join(rightTable, 'a1 === 'b2)
* joinTable.where('a1 >= 70).select('a1, 'b1).writeToSink(sink1)
* joinTable.where('a1 < 70 ).select('a1, 'c2).writeToSink(sink2)
* }}}
*
* the RelNode DAG is:
*
* {{{-
* Sink(sink1) Sink(sink2)
* | |
* Project(a1,b1) Project(a1,c2)
* | |
* Filter(a1>=70) Filter(a1<70)
* \ /
* Join(a1=b2)
* / \
* Project(a1,b1) Project(b2,c2)
* | |
* Filter(a>0) Filter(c is not null)
* \ /
* Project(a,b,c)
* |
* TableScan
* }}}
* This [[RelNode]] DAG will be decomposed into three [[RelNodeBlock]]s, the break-point
* is the [[RelNode]](`Join(a1=b2)`) which data outputs to multiple [[LegacySink]]s.
* <p>Notes: Although `Project(a,b,c)` has two parents (outputs),
* they eventually merged at `Join(a1=b2)`. So `Project(a,b,c)` is not a break-point.
* <p>the first [[RelNodeBlock]] includes TableScan, Project(a,b,c), Filter(a>0),
* Filter(c is not null), Project(a1,b1), Project(b2,c2) and Join(a1=b2)
* <p>the second one includes Filter(a1>=70), Project(a1,b1) and Sink(sink1)
* <p>the third one includes Filter(a1<70), Project(a1,c2) and Sink(sink2)
* <p>And the first [[RelNodeBlock]] is the child of another two.
*
* The [[RelNodeBlock]] plan is:
* {{{-
* RelNodeBlock2 RelNodeBlock3
* \ /
* RelNodeBlock1
* }}}可以看到,在这段注释中,sink1和sink2这两个sink流有一段逻辑是共用的,即Join(a1=b2)。那么,优化器在优化阶段会将这段逻辑切分成3个block,其中共用的逻辑为单独的RelNodeBlock1,优化器将把这部分共用逻辑提取出来,避免重复计算。
中间表注册语法扩展
问题描述
值得注意的是,原生的Flink SQL只能通过调用table api来提取共用逻辑。在非table api的场景下,比如,数据经过计算后将根据字段条件被写入不同的kafka topic,SQL示例如下:
data string,
topic string,
) with (
'connector' = 'kafka',
'topic' = 'topic',
'properties.bootstrap.servers' = '',
'format' = 'csv'
)
create table sink_table1(
data string,
) with (
'connector' = 'kafka',
'topic' = 'topic2',
'properties.bootstrap.servers' = '',
'format' = 'csv'
)
create table sink_table2(
data string,
) with (
'connector' = 'kafka',
'topic' = 'topic2',
'properties.bootstrap.servers' = '',
'format' = 'csv'
)
insert into sink_table1 select * from (select SBSTR(data, 0, 6) data,topic from source_table) where topic='topic1'
insert into sink_table2 select * from (select SBSTR(data, 0, 6) data,topic from source_table) where topic='topic2'如果使用 StreamTableEnviroment.executeSql()去分别执行这两条insert sql,最终会异步生成两个任务,因此需要使用Flink提供的statementset先缓存多条insert sql,最后调用执行,在一个任务中完成多条数据流的处理。
可以发现,在这两条insert sql中存在复用逻辑,即select SBSTR(data, 0, 6) data、topic from source_table。预期的结果是Flink能够识别到这段共用逻辑并复用,但是实际情况并非预期中的,如下图:
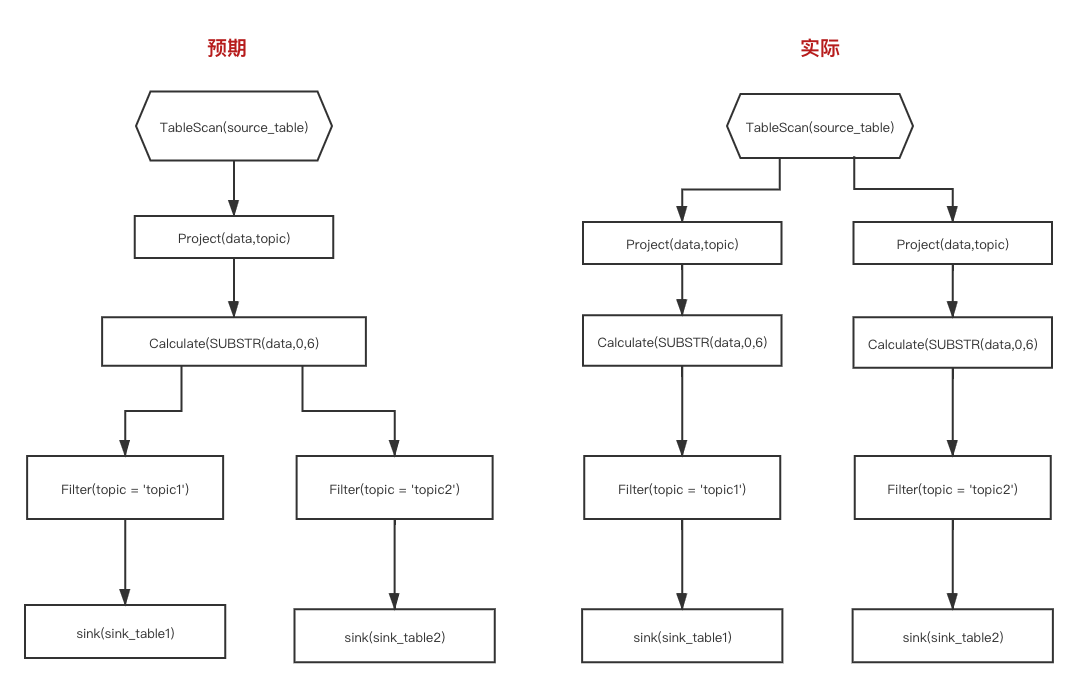
问题分析
分析出现该问题的原因是:Flink在解析阶段将select SBSTR(data, 0, 6) data、topic from source_table解析成SqlNode(SqlSelect)并生成相应的RelNode。由于即便是相同逻辑的SQL,其解析为RelNode的摘要也是不同的。而Flink正是通过摘要来寻找复用的RelNode。因此,Flink也就不能识别到这段逻辑是可以共用的。
判断逻辑共用的源码如下:
/**
* Reuse common sub-plan in different RelNode tree, generate a RelNode dag
*
* @param relNodes RelNode trees
* @return RelNode dag which reuse common subPlan in each tree
*/
private def reuseRelNodes(relNodes: Seq[RelNode], tableConfig: TableConfig): Seq[RelNode] = {
val findOpBlockWithDigest = tableConfig.getConfiguration.getBoolean(
RelNodeBlockPlanBuilder.TABLE_OPTIMIZER_REUSE_OPTIMIZE_BLOCK_WITH_DIGEST_ENABLED)
if (!findOpBlockWithDigest) {
return relNodes
}
// reuse sub-plan with same digest in input RelNode trees.
val context = new SubplanReuseContext(true, relNodes: _*)
val reuseShuttle = new SubplanReuseShuttle(context)
relNodes.map(_.accept(reuseShuttle))
}解决思路
那么如何解决呢?首先想到的思路就是将这段共用逻辑注册成表,这样Flink就能知道这段逻辑是共用的。
目前有“注册视图”(create view as query)和“注册表”(registerTable)两种方式能够将共用逻辑注册成表。在Flink中,当执行‘create view as query' 创建视图或者调用registerTable注册表时,底层都会在catalog中创建临时表,区别在于create view创建表的实现类为CatalogViewImpl,而registerTable创建表的实现类为QueryOperationCatalogView。
前者CatalogViewImpl的查询逻辑使用字符串表示,而后者 QueryOperationCatalogView的查询逻辑已经被解析为QueryOperation。也就是说,执行创建视图的语句时,最终创建的临时表仅仅是缓存了查询部分的SQL语句,当其他命令使用这个临时表时还需要重新解析临时表中的查询语句,而重新解析带来的问题就是创建新的RelNode,产生不同的摘要,这样Flink仍然不能够识别到这段共用逻辑并复用。
相反,regiterTable这样的方式就不需要对临时表中的查询语句进行重新解析。因此可以采用regiterTable将共用逻辑注册成表。示例代码如下:
StreamTableEnvironment.executeSql("create view as select SBSTR(data, 0, 6) data,topic from source_table);
// 注册表
Table table = StreamTableEnvironment.executeSql("select SBSTR(data, 0, 6) data,topic from source_table");
StreamTableEnvironment.registerTable("tmp", table);但是,为了SQL化,就需要有语法去支持中间表注册,以屏蔽底层的api调用,实现用户无感知。新语法预期如下:
// 示例
register table tmp as select SBSTR(data, 0, 6) data,topic from source_table
实现语法支持
如何实现新的语法,来支持中间表注册呢?目前有2种解决方案:
方案1:框架先使用正则匹配判断SQL类型,之后提取出临时表名和查询逻辑,比如上面的SQL经过正则匹配提取组之后可以得到表名为tmp,查询逻辑为'select SBSTR(data, 0, 6) data,topic from source_table',之后框架去调用table api进行注册。
方案2:修改flink-table模块源码扩展语法,实现对register table语法的支持。
从实现难度上来说,方案1的改动少,难度也较小,而方案2虽然改动较大,但是通用性更好。下面主要围绕方案2的实现展开。
register table语法扩展大致分为以下3个步骤:
Step1 SQL解析与校验
即修改Java CC相关文件,使得 SqlParser可以识别新的语法并解析为AST。
✦1.1 增加关键字“REGISTER”
首先需要让解析器识别新的关键字“REGISTER”,因此修改Parser.tdd,在keywords和nonReservedKeywords中分别增加“REGISTER”关键字。
✦1.2 创建SqlNode (SqlRegisterTable)
由于SqlParser解析SQL生成的AST数据类型为SqlNode,因此需要增加相应的SqlNode。在org.apache.flink.sql.parser.ddl下创建SqlRegisterTable:
import org.apache.calcite.sql.*;
import org.apache.calcite.sql.parser.SqlParserPos;
import javax.annotation.Nonnull;
import java.util.Collections;
import java.util.List;
public class SqlRegisterTable extends SqlCall {
public static final SqlSpecialOperator OPERATOR = new SqlSpecialOperator("REGISTER TABLE", SqlKind.OTHER_DDL);
private SqlIdentifier tableName;
private SqlNode query;
// 部分代码省略
}
修改Parser.tdd,在imports增加org.apache.flink.sql.parser.ddl.SqlRegisterTable,即刚才新建的 SqlRegisterTable的全类名路径。
✦1.3 增加语法解析模版
除了关键字和SqlNode,还需要相应的语法模版,让解析器能够把SQL解析为SqlRegisterTable。
修改parserImpls.ftl,增加语法解析模版:
{
SqlIdentifier tableName = null;
SqlNode query = null;
SqlParserPos pos;
}
{
<REGISTER> <TABLE> { pos = getPos();}
tableName = CompoundIdentifier()
<AS>
query = OrderedQueryOrExpr(ExprContext.ACCEPT_QUERY)
{
return new SqlRegisterTable(pos, tableName, query);
}
}Step2:SqlNode转为Operation
根据calcite在Flink中的执行流程,Flink会将SqlNode封装为Operation,因此需要创建相应的RegisterTableOperation,并修改相关的转换逻辑。
✦2.1 新建 RegisterTableOperation
import org.apache.flink.table.catalog.ObjectIdentifier;
import org.apache.flink.table.operations.Operation;
import org.apache.flink.table.operations.QueryOperation;
public class RegisterTableOperation implements Operation{
private final ObjectIdentifier tableIdentifier;
private final QueryOperation query;
// 省略部分代码
}✦2.2 增加解析逻辑
生成RegisterTableOperation之后,还需要让Flink能将 SqlNode转换成对应的Operation,因此我们要修改 SqlToOperationConverter.convert内部代码,增加解析逻辑,代码如下:
private Operation convertRegisterTable(SqlRegisterTable sqlRegisterTable) {
UnresolvedIdentifier unresolvedIdentifier = UnresolvedIdentifier.of(sqlRegisterTable.fullTableName());
ObjectIdentifier identifier = catalogManager.qualifyIdentifier(unresolvedIdentifier);
PlannerQueryOperation operation = toQueryOperation(flinkPlanner, validateQuery);
return new RegisterTableOperation(identifier, operation);
}Step3 Operation执行
即底层调用RegisterTable实现注册。由于流处理底层使用TableEnvironmentImpl进行相关SQL操作,比如常见的 executeSql(String statement) 操作 :
@Override
public TableResult executeSql(String statement) {
List<Operation> operations = parser.parse(statement);
if (operations.size() != 1) {
throw new TableException(UNSUPPORTED_QUERY_IN_EXECUTE_SQL_MSG);
}
return executeOperation(operations.get(0));
}因此在executeOperation()方法中,需要识别 RegisterTableOperation进行额外操作,因此增加operation执行逻辑如下:
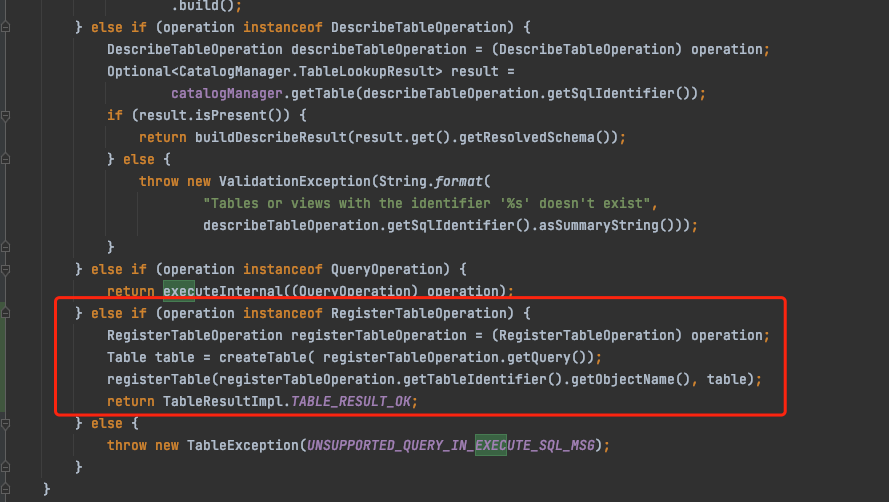
通过以上三步,完成源码修改,然后将flink-parser打包替换当前依赖,即可实现对register table语法的扩展。
Flink的SQL执行基于calcite,语法拓展的实现简要概括分为语法解析、转换、优化和执行4个阶段,其中会涉及到Java CC、Planner等知识,有兴趣的同学可以查阅相关内容做深入了解。
本文围绕中间表注册入手,对个推基于Flink SQL建设实时数仓的实践进行了总结和分享。
后续,我们还将持续梳理在实时业务场景下的Flink SQL应用实践,沉淀包括SQL稳定性、SQL资源配置等在内的通用解决方案;同时还将展开批流一体的探索,通过统一开发标准,来提升大数据作业的整体效率。
我们还将陆续面向行业总结和输出这些实践经验,更多精彩内容,请持续关注个推技术实践公众号。