推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
CuterCorley
•
4年前
Python 快速验证代理IP是否有效
有时候,我们需要用到代理IP,比如在爬虫的时候,但是得到了IP之后,可能不知道怎么验证这些IP是不是有效的,这时候我们可以使用Python携带该IP来模拟访问某一个网站,如果多次未成功访问,则说明这个代理是无效的。代码如下:pythonimportrequestsimportrandomimporttimehttp_ip'118.
Wesley13
•
4年前
java爬虫
想找一些图片做桌面背景,但是又不想一张张去下载,后来就想到了爬虫。。。对于爬虫我也没具体用过,在网上一顿搜索后写了个小demo。爬虫的具体思路就是:1.调用url爬取网页信息2.解析网页信息3.保存数据刚开始还用正则去匹配,获取img标签中的src地址,但是发现有很多不便(主要我正则不太会),后来发现了jsoup这个神器。jsoup
爬虫程序大魔王
•
3年前
爬虫数据采集
经常有小伙伴需要将互联网上的数据保存的本地,而又不想自己一篇一篇的复制,我们第一个想到的就是爬虫,爬虫可以说是组成了我们精彩的互联网世界。网络搜索引擎和其他一些网站使用网络爬虫或蜘蛛软件来更新他们的网络内容或其他网站的网络内容索引。网络爬虫复制页面以供搜索引擎处理,搜索引擎对下载的页面进行索引,以便用户可以更有效地搜索。这都是爬虫数据采集的功劳。这篇文章我总
Python进阶者
•
4年前
分享一次实用的爬虫经验
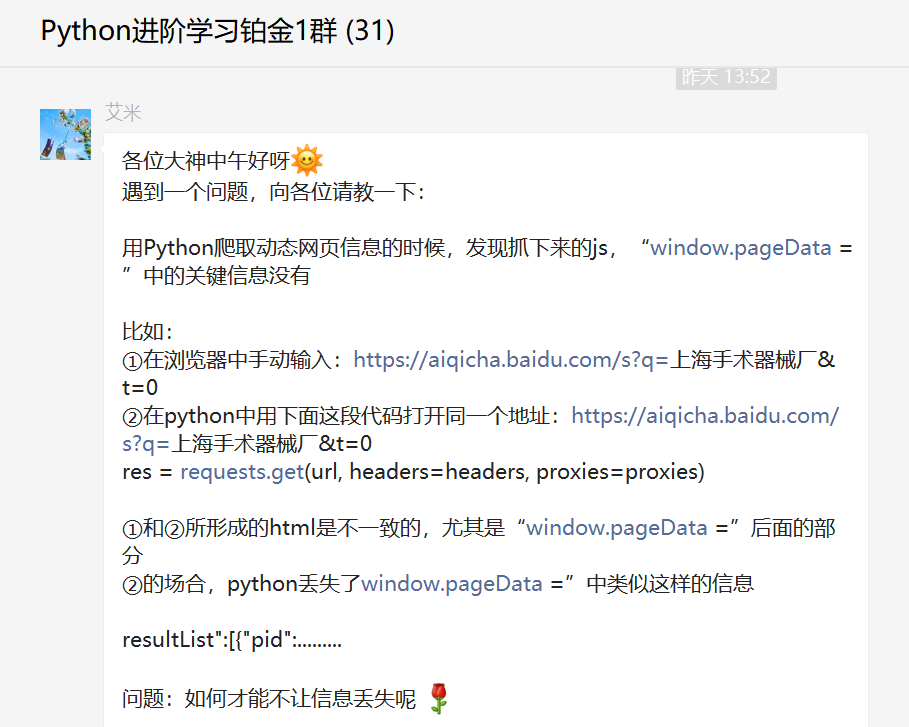
大家好,我是Python进阶者。前言前几天铂金群有个叫【艾米】的粉丝在问了一道关于Python网络爬虫的问题,如下图所示。不得不说这个粉丝的提问很详细,也十分的用心,给他点赞,如果大家日后提问都可以这样的话,想必可以节约很多沟通时间成本。其实他抓取的网站是爱企查,类似企查查那种。一、思路一开始我以为很简单,我照着他给的网站,然后一顿抓包操作,到头来竟然没
Stella981
•
4年前
Python使用又拍云进行第三方文件拉取
在爬虫过程中,需要将图片或其他文件进行存储到云上,但在下载图片时,看官方文档,貌似需要先下载到后再上传又拍云,感觉效率很低下。经查找资料实现Python直接对第三方资源进行文件拉取操作,即不需要下载到本地,代码如下:importupyunupupyun.UpYun('xxxxx','xxxxx','xxxxx')您
小白学大数据
•
2个月前
高效爬虫教程:Python 批量抓取抖音无水印视频
在短视频内容生态中,抖音凭借庞大的用户基数和丰富的内容库,成为了内容创作者、数据分析从业者以及营销人员关注的焦点。获取抖音视频的无水印资源,无论是用于内容二次创作、数据研究还是素材整理,都有着实际的应用需求。本文将从技术原理出发,详细讲解如何利用Pytho
小白学大数据
•
2年前
重定向爬虫和多线程爬虫
在日常爬取工作中会遇到程序返回302的情况,这种是网站重新定向问题,就是爬取的网站进行了跳转,我们想要的数据又需要跳转连接才能取到,比如,我们访问http/www.baidu.com会跳转到https/www.baidu.com,发送请求之后,就会返回30
崇恩圣帝
•
1年前
使用Python识别滑块验证码缺口的方法
步骤一:获取验证码图像首先,我们需要获取网站上的验证码图像。为了简化示例,我们将模拟一个验证码图像,包括带有缺口的滑块图像和完整的背景图像。你可以使用网络爬虫或者API来获取实际网站上的验证码图像。python复制代码获取验证码图像(模拟)importcv
崇恩圣帝
•
1年前
使用Python识别滑块验证码缺口的方法
步骤一:获取验证码图像首先,我们需要获取网站上的验证码图像。为了简化示例,我们将模拟一个验证码图像,包括带有缺口的滑块图像和完整的背景图像。你可以使用网络爬虫或者API来获取实际网站上的验证码图像。python复制代码获取验证码图像(模拟)importcv
小白学大数据
•
9个月前
自动化爬虫:requests定时爬取前程无忧最新职位
引言在互联网招聘行业,前程无忧(51job)作为国内领先的招聘平台之一,汇聚了大量企业招聘信息。对于求职者、猎头或数据分析师来说,实时获取最新的招聘信息至关重要。手动收集数据效率低下,而通过Python编写自动化爬虫,可以定时爬取前程无忧的最新职位,并存储
1
•••
19
20
21
•••
294