推荐
专栏
教程
课程
飞鹅
本次共找到3452条
mysql查询重复记录
相关的信息
捉虫大师
•
4年前
我在组内的Nacos分享
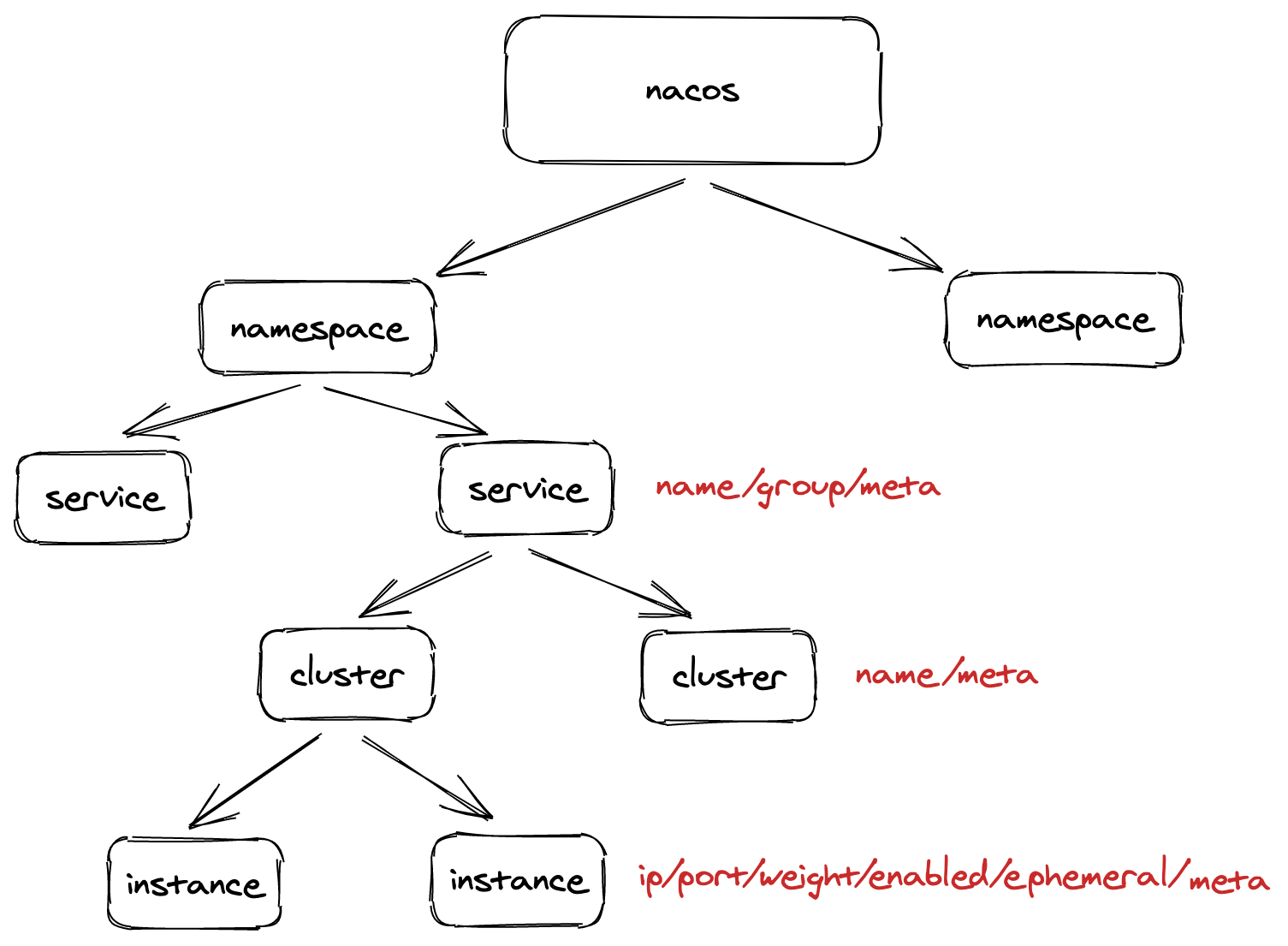
本文已收录https://github.com/lkxiaolou/lkxiaolou欢迎star。Nacos简介Nacos:NamingandConfigurationService,可打包部署配置中心和注册中心,也可独立部署其中之一,配置中心、控制台依赖mysql,由阿里巴巴2018年8月开源,github19.1kstar(截止20
亚瑟
•
4年前
云原生监控系统 Prometheus 入门
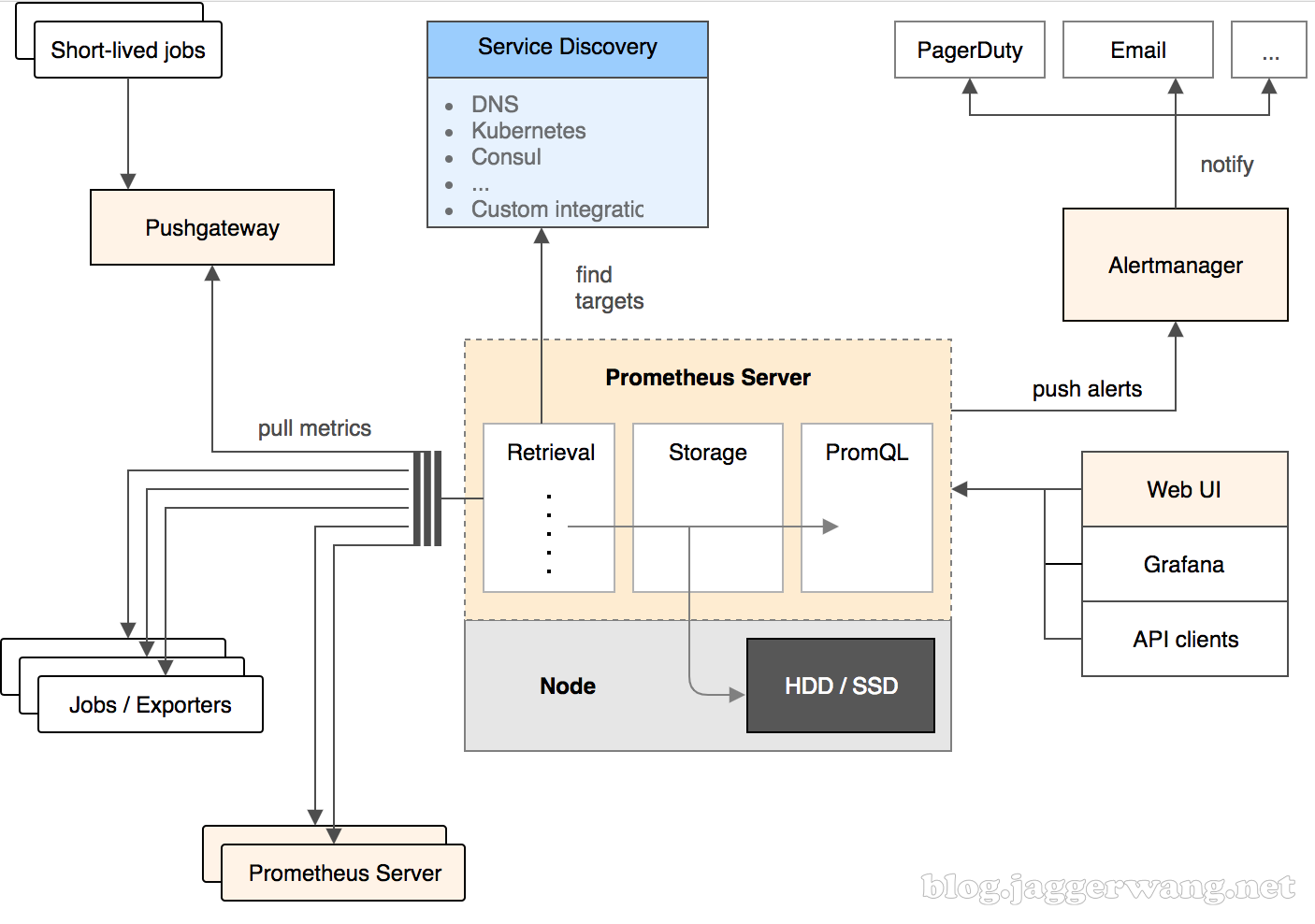
Prometheus介绍主要特性之所以Prometheus现在这么受欢迎,主要是因为它具备如下特性:多维度数据模型灵活的查询语言不依赖任何分布式存储常见方式是通过拉取方式采集数据也可通过中间网关支持推送方式采集数据通过服务发现或者静态配置来发现监控目标支持多
Stella981
•
4年前
SourceTree安装
SourceTree安装教程 作为程序员,不可避免的要在github上查询代码,而在企业项目中,为了使得项目好管理需要使用项目管理客户端,所以接下来详细讲解一下基于git的sourceTree在windows系统下的安装及与GitHub上的账号进行远程连接同步更新的过程。 由于sourceTree的安装过程
Stella981
•
4年前
SpringBoot2.2.2版本自动建表
环境idea2019.2 jdk1.8 数据库mysql5.7项目结构!(https://oscimg.oschina.net/oscnet/3179dc9eee1e56f4ce94321ca71451f2f43.png)newProject 使用springboot快速搭建web项目 选好sdk next
Wesley13
•
4年前
MySQL数据库InnoDB存储引擎Log漫游(1)
作者:宋利兵来源:MySQL代码研究(mysqlcode)0、导读本文介绍了InnoDB引擎如何利用UndoLog和RedoLog来保证事务的原子性、持久性原理,以及InnoDB引擎实现UndoLog和RedoLog的基本思路。00–UndoLogUndoLog是为了实现事务的原子性,
Stella981
•
4年前
Linux锐速当前连接数等状态查询,service serverSpeeder status 服务,帮助信息
使用serverSpeeder服务进行锐速的启动,停止,以及重新加载配置等操作;各参数说明如下:1.serviceserverSpeederstart:启动锐速,加载加速模块;使用/serverspeeder/etc/config文件中的配置作为模块加载时的初始化参数;1.serviceserverSp
Stella981
•
4年前
GraphQL 使用介绍
!(https://oscimg.oschina.net/oscnet/9d854df9aa4e01f403bbb6ae4c9da2afbdf.jpg)GraphQL是Fackbook的一个开源项目,它定义了一种查询语言,用于描述客户端与服务端交互时的数据模型和功能,相比RESTfulAPI主要有以下特点:根据需要返回数据
Stella981
•
4年前
Elasticsearch学习记录(1.安装,简单的查询,聚合,防止数据重复,冲突控制等)
首先我的学习是基于该教程进行的(下列部分代码文字出自该教程,在学习过程中增加我自己的理解和补充,便于更好的裂解和学习,并指出下列教程错误的地方):http://es.xiaoleilu.com/(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fes.xiaoleilu.com%2F
爬虫程序大魔王
•
3年前
爬虫数据是如何收集和整理的?
有用户一直好奇识别网站上的爬虫数据是如何整理的,今天就更大家来揭秘爬虫数据是如何收集整理的。通过来获得rDNS方式我们可以通过爬虫的IP地址来反向查询rDNS,例如:我们通过查找此IP:116.179.32.160,rDNS为:baiduspider11617932160.crawl.baidu.com从上面大致可以判断应该是。由于Ho
天翼云开发者社区
•
7个月前
sql优化谓词下推在join场景中的应用
谓词下推的原理是将sql中的限制条件的逻辑尽可能的提前在sql中执行,从而减少加载的数据量,提升下游数据处理的效率以及减少内存消耗。该种方式在hive,MySQL,Doris的语法中均适用。
1
•••
239
240
241
•••
346