
Prometheus 介绍
主要特性
之所以 Prometheus 现在这么受欢迎,主要是因为它具备如下特性:
- 多维度数据模型
- 灵活的查询语言
- 不依赖任何分布式存储
- 常见方式是通过拉取方式采集数据
- 也可通过中间网关支持推送方式采集数据
- 通过服务发现或者静态配置来发现监控目标
- 支持多种图形界面展示方式
系统架构
下面这张图描述了 Prometheus 的整体架构,以及其生态中的一些常用组件。
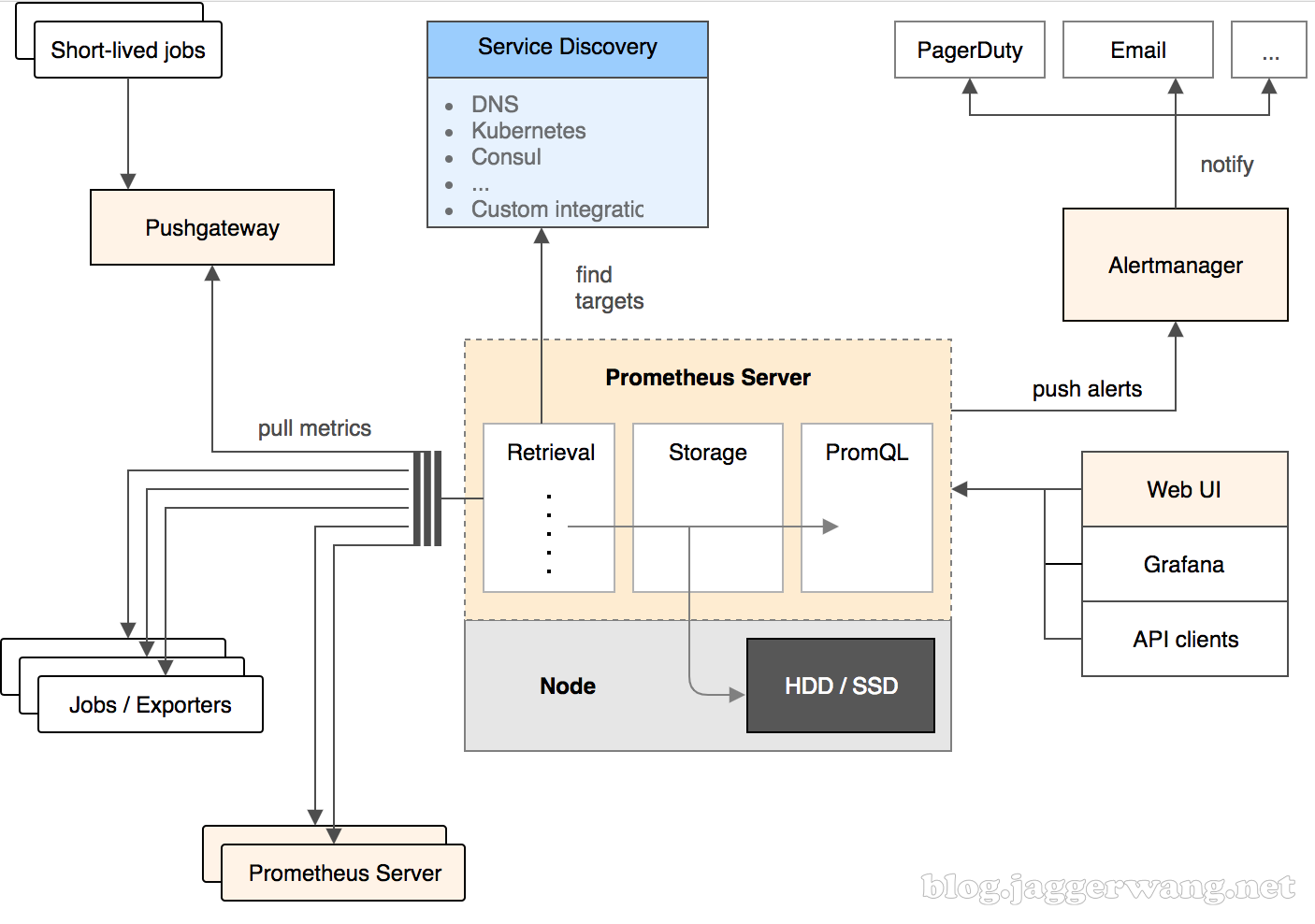
Prometheus Server 采用拉取方式从监控目标直接拉取数据,或者通过中间网关间接地拉取监控目标推送给网关的数据。它在本地存储抓取的数据,通过一定规则进行清理和整理数据,然后把得到的结果存储起来。各种 Web UI 使用 PromQL 查询语言来从 Server 里获取数据。当 Server 监测到有异常时会推送告警给 Alertmanager,Alertmanager 负责去通知相关人。
核心概念
数据模型
Prometheus 从根本上存储的所有数据都是时间序列数据(Time Serie Data,简称时序数据)。时序数据是具有时间戳的数据流,该数据流属于某个度量指标(Metric)和该度量指标下的多个标签(Label)。除了提供存储功能,Prometheus 还可以利用查询表达式来执行非常灵活和复杂的查询。
度量指标和标签
每个时间序列(Time Serie,简称时序)由度量指标和一组标签键值对唯一确定。
度量指标名称描述了被监控系统的某个测量特征(比如 http_requests_total 表示 http 请求总数)。度量指标名称由 ASCII 字母、数字、下划线和冒号组成,须匹配正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
标签开启了 Prometheus 的多维数据模型。对于同一个度量指标,不同标签值组合会形成特定维度的时序。Prometheus 的查询语言可以通过度量指标和标签对时序数据进行过滤和聚合。改变任何度量指标上的任何标签值,都会形成新的时序。标签名称可以包含 ASCII 字母、数字和下划线,须匹配正则表达式 [a-zA-Z_][a-zA-Z0-9_]*,带有 _ 下划线的标签名称保留为内部使用。标签值可以包含任意 Unicode 字符,包括中文。
采样值(Sample)
时序数据其实就是一系列采样值。每个采样值包括:
- 一个 64 位的浮点数值
- 一个精确到毫秒的时间戳
注解(Notation)
一个注解由一个度量指标和一组标签键值对构成。形式如下:
[metric name]{[label name]=[label value], ...} 例如,度量指标为 api_http_requests_total,标签为 method="POST"、handler="/messages" 的注解表示如下:
api_http_requests_total{method="POST", handler="/messages"} 度量指标类型
计数器(Counter)
计数器是一种累计型的度量指标,它是一个只能递增的数值。计数器主要用于统计类似于服务请求数、任务完成数和错误出现次数这样的数据。
计量器(Gauge)
计量器表示一个既可以增加, 又可以减少的度量指标值。计量器主要用于测量类似于温度、内存使用量这样的瞬时数据。
直方图(Histogram)
直方图对采样值(通常是请求持续时间或者响应大小这样的数据)按桶进行统计,每个桶代表一个采样值区间。有以下几种方式来产生直方图(假设度量指标为
- 按桶计数,相当于
<basename>_bucket{le="<upper inclusive bound>"},也就是采样值小于等于指定上限值的次数 - 采样值总和,相当于
<basename>_sum,也就是当前采样值集合里所有采样值的总和 - 采样值总数,相当于
<basename>_count,也就是当前采样值集合里所有采样值的总数,等同于把所有采样值放到一个桶里来计数<basename>_bucket{le="+Inf"}
汇总(Summary)
类似于直方图,汇总也对观察结果进行统计。它除了可以统计采样值总和和总数,还能够按分位数统计。有以下几种方式来产生汇总(假设度量指标为
- φ 分位值,相当于
<basename>{quantile="<φ>"},也就是该采样值排在当前采样值集合的第<basename>_count * φ位 - 采样值总和,相当于
<basename>_sum - 采样值总数,相当于
<basename>_count
任务(Job)和实例(Instance)
在 Prometheus 里,可以从中抓取采样值的端点称为实例,为了扩展服务性能而复制出来的多个这样的服务实例就形成了一个任务。
例如下面的 api-server 任务有四个等同的实例:
job: api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
instance 3: 5.6.7.8:5670
instance 4: 5.6.7.8:5671 Prometheus 抓取完采样值后,会自动给采样值打上以下标签:
- job: 所属任务。
- instance: 所属实例
另外每次抓取时,Prometheus 还会自动在以下时序里插入采样值:
up{job="[job-name]", instance="instance-id"}:采样值为 1 表示实例健康,否则为不健康scrape_duration_seconds{job="[job-name]", instance="[instance-id]"}:采样值为本次抓取消耗时间scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"}:采样值为重新打标签的采样值个数scrape_samples_scraped{job="<job-name>", instance="<instance-id>"}:采样值为本次抓取到的采样值个数
Prometheus 安装
二进制包方式
二进制包方式非常简单,推荐使用这种方式。从 官网 下载对应平台的二进制包,然后解压即可。以 Linux 64 位平台为例,当前版本为 2.2.1。
wget https://github.com/prometheus/prometheus/releases/download/v2.2.1/prometheus-2.2.1.linux-amd64.tar.gz
tar xvfz prometheus-2.2.1.linux-amd64.tar.gz
cd prometheus-2.2.1.linux-amd64
./prometheus 上面的命令会在默认的 9090 端口启动 Prometheus 服务,打开地址 http://localhost:9090/ 即可看到其 Web 界面。
源码方式
Prometheus 是开源的,因此可以下载源码到本地来编译安装。这种方式比较麻烦,适合想学习源码或做二次开发的人。感兴趣的可以自行研究,这里就不做讲解。
Docker 方式
如果当前部署环境支持 Docker,那么可以采用这种方式来运行 Prometheus 服务。使用下面的命令来启动一个 Prometheus 容器:
docker run -p 9090:9090 prom/prometheus 上面把容器内的 9090 端口映射到了宿主机的 9090 端口,因此可以在宿主机上通过 http://localhost:9090/ 来访问容器内的 Prometheus 服务。
Prometheus 配置
概述
执行 prometheus 命令的时候可以通过参数 --config.file 来指定配置文件路径,默认会使用同目录下的 prometheus.yml 文件。Prometheus 服务运行过程中如果配置文件有改动,可以给服务进程发送 SIGHUP 信号来通知服务进程重新从磁盘加载配置。这样无需重启,避免中断服务。
下面来讲解 Prometheus 的核心配置,示例中用到的各种占位符包括:
: 布尔值,true 或 false : 持续时间,格式符合正则表达式 [0-9]+(ms|[smhdwy]) : 标签名,格式符合正则表达式 [a-zA-Z_][a-zA-Z0-9_]* : 标签值,可以包含任意 Unicode 字符 : 文件名,任意有效的文件路径 : 主机,可以是主机名或 IP,后面可跟端口号 : URL 路径部分 : 协议,http 或 https : 字符串 : 密钥,比如密码 - <tmpl_string>: 模板字符串,里面包含需要展开的变量
配置文件格式为 YAML,内容如下:
# 全局配置对所有其它地方有效,作为其它地方配置的默认值。
global:
# 抓取间隔
[ scrape_interval: <duration> | default = 1m ]
# 抓取超时时间
[ scrape_timeout: <duration> | default = 10s ]
# 规则评估间隔
[ evaluation_interval: <duration> | default = 1m ]
# 抓取配置
scrape_configs:
[ - <scrape_config> ... ]
# 规则配置文件列表,可使用通配符 *
rule_files:
[ - <filepath_glob> ... ]
# 告警管理器配置
alerting:
alert_relabel_configs:
[ - <relabel_config> ... ]
alertmanagers:
[ - <alertmanager_config> ... ] 规则包括记录规则和报警规则,两者处理比较类似,所以放在一起。Prometheus 会定期评估规则,对于记录规则会在对应的时序里插入采样值,对于报警规则会在条件满足时发送警告到告警管理器(Alertmanager)。
抓取配置
抓取配置可以有多个,一般来说每个任务对应一个配置。单个抓取配置的格式如下:
# 任务名
job_name: <job_name>
# 抓取间隔,默认为对应全局配置
[ scrape_interval: <duration> | default = <global_config.scrape_interval> ]
# 抓取超时时间,默认为对应全局配置
[ scrape_timeout: <duration> | default = <global_config.scrape_timeout> ]
# 协议,默认为 http,可选 https
[ scheme: <scheme> | default = http ]
# 抓取地址的路径,默认为 /metrics
[ metrics_path: <path> | default = /metrics ]
# 抓取地址的参数
params:
[ <string>: [<string>, ...] ]
# 是否尊重抓取回来的标签,默认为 false
[ honor_labels: <boolean> | default = false ]
# 静态目标配置
static_configs:
[ - <static_config> ... ]
# 单次抓取的采样值个数限制,默认为 0,表示没有限制
[ sample_limit: <int> | default = 0 ] honor_labels 表示是否尊重抓取回来的采样值的标签。当抓取回来的采样值的标签值跟服务端配置的不一致时,如果该配置为 true,则以抓取回来的为准。否则以服务端的为准,抓取回来的值会保存到一个新标签下,该新标签名在原来的前面加上了“exported_”,比如 exported_job。
static_configs 下配置了该任务要抓取的所有实例,按组配置,包含相同标签的实例可以分为一组,以简化配置。单个组的配置格式如下:
# 目标地址列表,地址由主机 + 端口组成
targets:
[ - '<host>' ]
# 标签列表
labels:
[ <labelname>: <labelvalue> ... ] 抓取目标除了采用静态配置方式,还可以动态发现。动态发现依赖于一个服务发现服务(比如 Consul,可以从这个服务里查询到目前系统里的服务列表),适合监控目标非常多并且经常变化的场景。
记录规则配置
记录规则允许我们把一些经常需要使用并且查询时计算量很大的查询表达式,预先计算并保存到一个新的时序。查询这个新的时序比从原始的一个或多个时序实时计算快得多,并且还能够避免重复计算。在一些特殊场景下这甚至是必须的,比如仪表盘里展示的各类定时刷新的数据,数据种类多且需要计算非常快。
记录规则配置文件的格式如下:
groups:
[ - <rule_group> ] 记录规则配置按组来组织,一个组下的所有规则按顺序定时执行。单个组的格式如下:
# 组名,在文件内唯一
name: <string>
# 规则评估间隔,默认为对应的全局配置
[ interval: <duration> | default = global.evaluation_interval ]
rules:
[ - <rule> ... ] 每个组下包含多条规则,格式如下:
# 规则名称,也就是该规则产生的时序数据的度量指标名
record: <string>
# PromQL 查询表达式,表示如何计算得到采样值
expr: <string>
# 关联标签
labels:
[ <labelname>: <labelvalue> ] 配置验证
Prometheus 的配置项比较多,配置时容易出错,所以它提供了 promtool 工具来验证配置的正确性。该工具可使用下面的命令来安装:
go get github.com/prometheus/prometheus/cmd/promtool 请安装最新版的 Go 语言,低版本可能无法编译成功。由于需要从 GitHub 下载源码,时间会比较长,尽量使用代理。
安装完成后,可使用 promtool check config <config-files> 和 promtool check rules <rule-files> 来分别检查主配置文件和规则配置文件。
Prometheus 使用
我们通过使用 Prometheus 监控其自身来学习它的基本用法。
配置 Prometheus 监控其自身
Prometheus 服务本身也通过路径 /metrics 暴露了其内部各项度量指标,我们只需要把它加入到监控目标里就可以。
global:
# 全局默认抓取间隔
scrape_interval: 15s
scrape_configs:
# 任务名
- job_name: 'prometheus'
# 本任务的抓取间隔,覆盖全局配置
scrape_interval: 5s
static_configs:
# 抓取地址同 Prometheus 服务地址,路径为默认的 /metrics
- targets: ['localhost:9090'] 配置完成后启动服务:
./prometheus 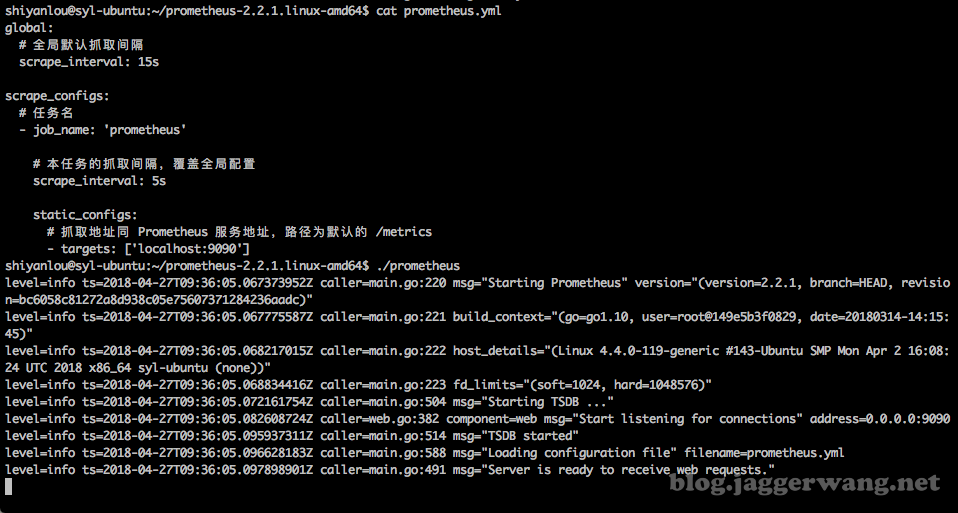
可打开地址 http://localhost:9090/metrics 来确认是否有抓取到数据。
使用表达式浏览器来查询数据
在本地打开页面 http://localhost:9090/,会自动跳转到 Graph 页。在这个页面里可以执行表达式来查询数据,数据展示方式支持 Console 文本方式和 Graph 图形方式。可从 Execute 后面的下拉列表里选择某个度量指标,或者手动输入任意合法的 PromQL 表达式。
比如选择或输入 prometheus_target_interval_length_seconds 会查询到该度量指标相关的所有时序,这里共有四个。

Console 方式列出匹配的所有时序,以及每个时序的最新采样值。
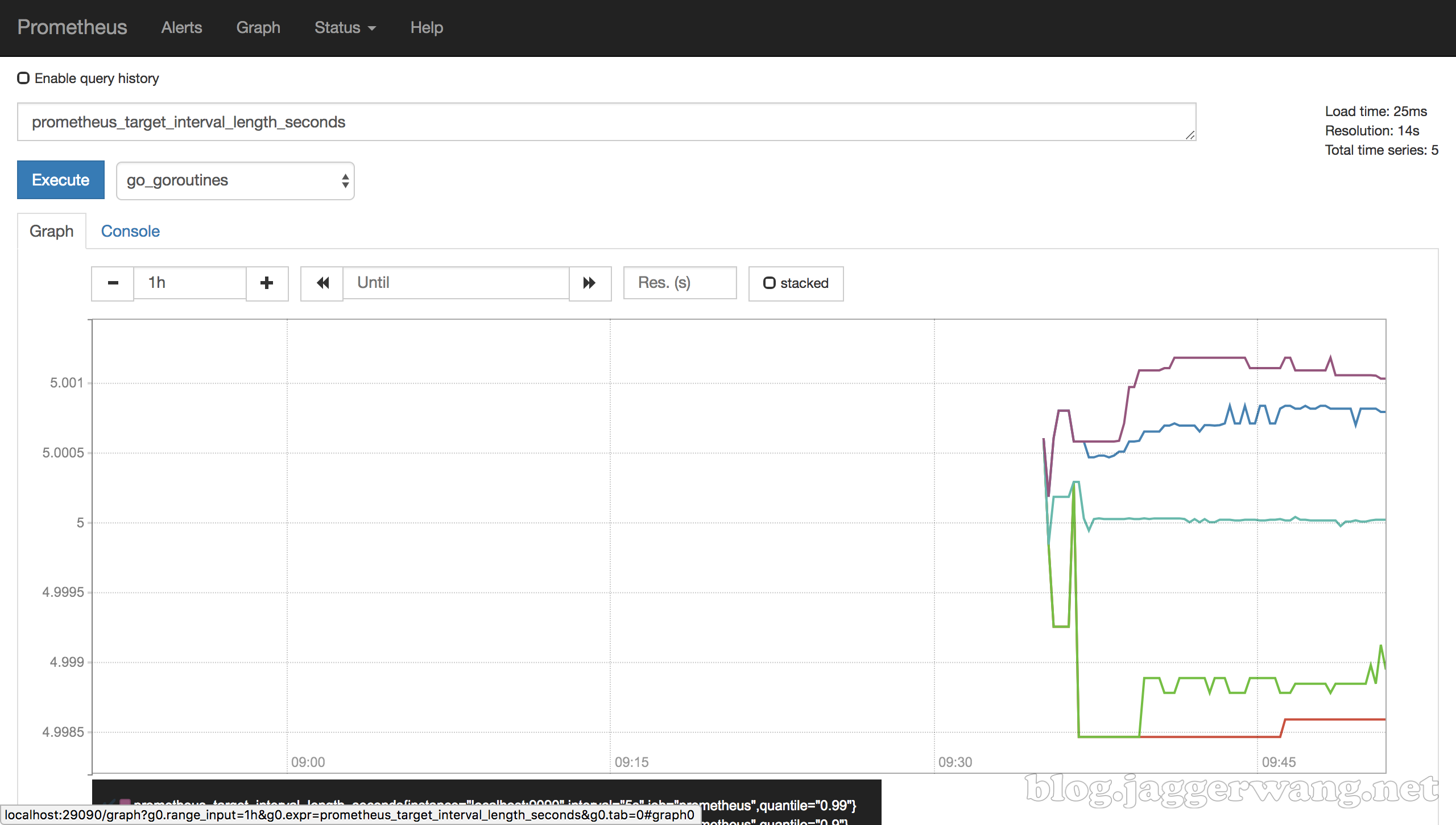
Graph 方式以图形方式展示匹配的所有时序最近一段时间内的采样值,默认为最近一小时。
prometheus_target_interval_length_seconds 这个度量指标的含义是实际抓取目标时的间隔秒数。可以使用表达式 prometheus_target_interval_length_seconds{quantile="0.99"} 来查询 0.99 分位的采样值。使用表达式 count(prometheus_target_interval_length_seconds) 可以查询到该度量指标包含的采样值个数。
本文仅对 Prometheus 做了一个简单的入门介绍,Prometheus 还提供了灵活强大的查询语言 PromeQL,数据可视化可使用更强大的 Grafana,报警功能通过独立的 Alertmanager 来提供,功能也是相当强大。更多内容大家可以去阅读官方文档。
参考资料
本文转自 https://blog.jaggerwang.net/cloud-native-monitor-system-prometheus-intro/,如有侵权,请联系删除。













