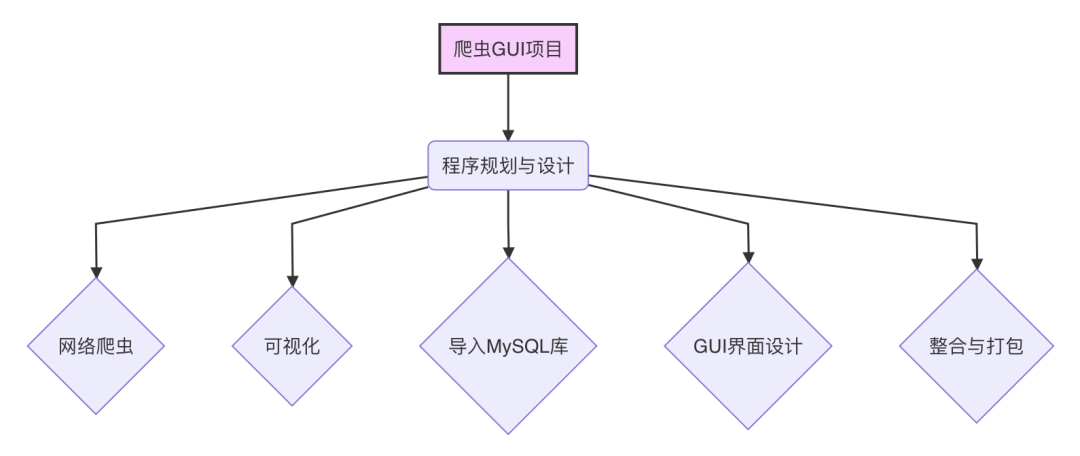
有用户一直好奇爬虫识别网站上的爬虫数据是如何整理的,今天就更大家来揭秘爬虫数据是如何收集整理的。
通过查询 IP 地址来获得 rDNS 方式
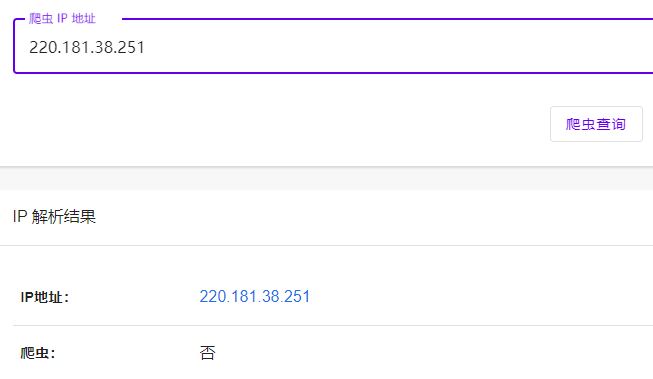
我们可以通过爬虫的 IP 地址来反向查询 rDNS,例如:我们通过反向 DNS 查找工具查找此 IP: 116.179.32.160 ,rDNS 为:baiduspider-116-179-32-160.crawl.baidu.com
从上面大致可以判断应该是百度搜索引擎蜘蛛。由于 Hostname 可以伪造,所以我们只有反向查找,仍然不准确。我们还需要正向查找,我们通过 ping 命令查找 baiduspider-116-179-32-160.crawl.baidu.com 能否被解析为:116.179.32.160,通过下图可以看出 baiduspider-116-179-32-160.crawl.baidu.com 被解析为 116.179.32.160 的 IP 地址,说明是百度搜索引擎爬虫确信无疑。
通过 ASN 相关信息查找
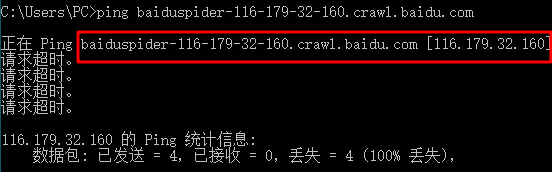
并不是所有爬虫都遵守上面的规定,大部分爬虫反向查找没有任何结果,我们需要查询 IP 地址的 ASN 信息来判断爬虫信息是不是正确。
例如:这个 IP 是 74.119.118.20,我们通过查询 IP 信息可以看到这个 IP 地址是美国加利福尼亚桑尼维尔的 IP 地址。
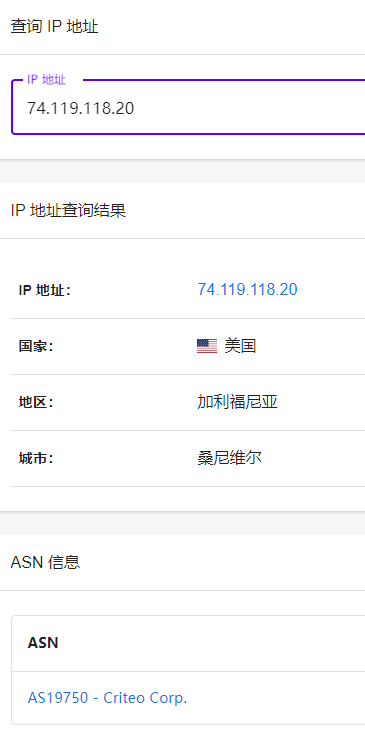
通过 ASN 信息我们可以看出来他是 Criteo Corp. 公司的 IP。
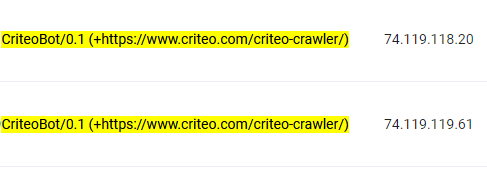
上面的截图是通过日志记录查看到 critieo crawler 的记录信息,黄色部分是它的 User-agent ,后面是它的 IP,这条记录也没有什么问题(这个 IP 的确是 CriteoBot 的 IP 地址)。
通过爬虫的官方文档公布的 IP 地址段
有一些爬虫会公布 IP 地址段,我们会将官方公布的爬虫 IP 地址段直接保存到数据库,这是一种既简单又快捷的方法。
通过公开日志
我们经常可以在互联网上查看到公开日志,例如下图就是我找到的公开日志记录:
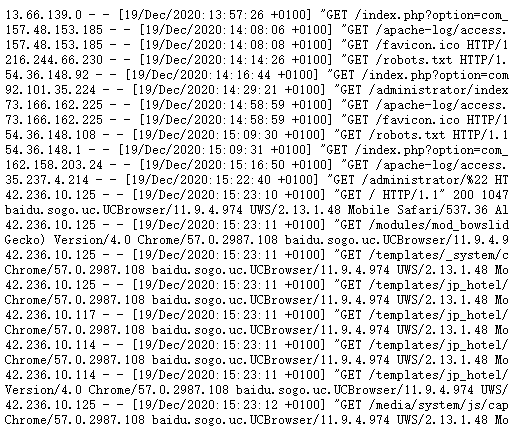
我们可以对日志记录进行解析,根据 User-agent 来判断那些是爬虫,那些是访客,极大的丰富了我们的爬虫记录数据库。
总结
通过以上四个方式详细说明了爬虫识别网站是如何收集和整理爬虫数据的,同时如何确保爬虫数据的准确可靠,当然在实际操作过程中不仅仅是以上四种方法,不过都使用的比较少,所以在此处也不做介绍。