推荐
专栏
教程
课程
飞鹅
本次共找到2182条
hadoop集群搭建
相关的信息
lix_uan
•
4年前
Hadoop调优
HDFS核心参数NameNode,DataNode内存配置查看NameNode,DataNode占用内存shelljpsjmapheap2611jmapheap2744经验shellNameNode最小值1G,每增加100w个block,增加1G内存DataNode最小值4G,副本总数超过400w时,每增加1
lix_uan
•
4年前
Hadoop学习总结
HDFS相关HDFS写数据的流程首先由客户端向NameNode服务发起写数据请求NameNode收到请求后会进行基本验证验证类容包括对请求上传的路径进行合法验证对请求的用户进行权限验证验证没有问题后,NameNode会响应客户端允许上传接下来客户端会对文件按照blocksize大小进行切块,切完后依次以块为单位上传此时客户端会请求上传
Stella981
•
4年前
HBase0.96.x开发使用(二)
hbaseshell命令1、进入hbaseshell环境:\hbase@hadoop230~\$./hbaseshellHBaseShell;enter'help<RETURN'forlistofsupportedcommands.Type"exit<RETURN"toleavetheHBaseS
Stella981
•
4年前
HBase生产环境优化不完全指南
HBase使用定位:大规模数据高并发毫秒级响应的OLTP实时系统(数据库)。集群部署架构HBase集群一旦部署使用,再想对其作出调整需要付出惨痛代价,所以如何部署HBase集群是使用的第一个关键步骤。以下是HBase集群使用以来的部署架构变化以及对应的分析。第一阶段硬件混合型软件混合型集群集群规模:20
Stella981
•
4年前
Hadoop机架感知
倘若世子殿下身死拒北城外会有一断手残脚青年自中原而来拾春秋剑入陆地神仙仰头望天而喊我温不胜在此恭请拓跋菩萨赴死!_订正:__在上篇文中NM类比为部门负责人一段中,段中的RM应为NM,感谢_DN_同学的指正。_1.数据分块HDFS作为Hadoop中的一个分布式文件系统,
Stella981
•
4年前
Hadoop主要生态系统简介
Hadoop的起源DougCutting是Hadoop之父,起初他开创了一个开源软件Lucene(用Java语言编写,提供了全文检索引擎的架构,与Google类似),Lucene后来面临与Google同样的错误。于是,DougCutting学习并模仿Google解决这些问题的办法,产生了一个Lucene的微缩版Nutch。后
Wesley13
•
4年前
MongoDB 的分片技术
在MongoDB中分片技术也就是集群。需要1台配置服务器配置各个节点的配置信息,1台路由服务器来知道每一台节点都在哪个地方并给用户提供各个节点数据的访问功能,还有多台节点服务器,存储节点数据。 当前我有三台机器192.168.0.114,192.168.0.115,192.168.0.116,规划如下: 搭建配置服务器:192.1
天翼云开发者社区
•
3年前
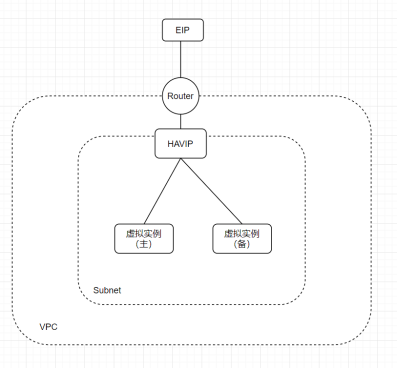
天翼云高可用虚拟IP(HAVIP)实践
(一)产品概述天翼云高可用虚拟IP(HighAvailabilityVirtualIPAddress,简称HAVIP)是一种可用独立创建和删除的私有网络IP地址资源。通过在VIPCIDR中申请一个私有网络IP地址,然后与高可用软件(如高可用软件Keepalived)配合使用,可用在VPC中搭建高可用的主备集群服务,提高VPC中服务的可用性。限制和说明
京东云开发者
•
1年前
HBase集群数据在线迁移方案探索
一、背景订单本地化系统目前一个月的订单的读写已经切至jimkv存储,对应的HBase集群已下线。但存储全量数据的HBase集群仍在使用,计划将这个HBase集群中的数据全部迁到jimkv,彻底下线这个HBase集群。由于这个集群目前仍在线上读写,本文从原理
天翼云开发者社区
•
1年前
初探集群联邦
本文分享自天翼云开发者社区《》,作者:echooo一.什么是集群联邦?集群联邦(Federation)是将多个kubenetes集群注册到统一的控制平面,为用户提供统一API入口的多集群解决方案。集群联邦设计的核心是提供在全局层面对应用的描述能力,并将联邦
1
•••
17
18
19
•••
219