
HBase使用定位:大规模数据+高并发+毫秒级响应的OLTP实时系统(数据库)。
集群部署架构
HBase集群一旦部署使用,再想对其作出调整需要付出惨痛代价,所以如何部署HBase集群是使用的第一个关键步骤。
以下是HBase集群使用以来的部署架构变化以及对应的分析。
第一阶段 硬件混合型+软件混合型集群
集群规模:20
部署服务:HBase、Spark、Hive、Impala、Kafka、Zookeeper、Flume、HDFS、Yarn等
硬件情况:内存、CPU、磁盘等参差不齐,有高配有低配,混搭结构
硬件混合型指的是该集群机器配置参差不齐,混搭结构。
软件混合型指的是该集群部署了一套CDH全家桶套餐。
这个集群不管是规模、还是服务部署方式相信都是很多都有公司的”标准“配置。
那么这样的集群有什么问题呢?
如果仅仅HBase是一个非“线上”的系统,或者充当一个历史冷数据存储的大数据库,这样的集群其实一点问题也没有,因为对其没有任何苛刻的性能要求。
但是如果希望HBase作为一个线上能够承载海量并发、实时响应的系统,这个集群随着使用时间的增加很快就会崩溃。
先从硬件混合型来说,一直以来Hadoop都是以宣称能够用低廉、老旧的机器撑起一片天。是的没错,这确实是Hadoop的一个大优势。然而前提是作为离线系统使用。首先说明一下离线系统的定义,就是跑批的系统,Spark、Hive、MapReduce等等,这些都算,没有很强的时间要求,显著的吞吐量大,延迟高。因为没有实时性要求,几台拖拉机跑着也没有问题,只要最后能出结果并且结果正确就ok。
那么我们现在对HBase的要求特别高,对它的定义已经不是一个离线系统而是一个实时系统了。对于一个硬性要求很高的实时系统来说,如果其中几台老机器拖了后腿也会引起线上响应的延迟。
软件混合型集群对实时HBase来说影响也特别大,离线任务最大的特点就是吞吐量特别高,瞬间读写的数据量可以把IO直接撑到10G/s,最主要的影响因素就是大型离线任务带动高IO将会影响HBase的响应性能。如果只是这样的话,线上的表现仅仅为短暂延迟,如果离线任务再把CPU撑爆,RegionServer节点可能会直接宕机挂掉,造成严重的生产影响。
还有一种情况是离线任务大量读写磁盘、读写HDFS,导致HBase IO连接异常也会造成RegionServer异常(HBase日志反应HDFS connection timeout,HDFS日志反应IO Exception),造成线上故障。
硬件混合型+软件混合型结合产生的化学反应简直无法想象的酸爽。。。
第二阶段 全新硬件+软件混合型集群
第二阶段,重新采购了全新的高配机器,搭建了一个新集群并从老集群过渡过来,老集群的旧机器淘汰不用(一般硬件使用年限就是4、5年)。但是受限于机器规模,没有将软件服务分开部署,仍然是软件混合型集群,只是在硬件上做了提升。
集群规模:30(后期加至40)
部署服务:HBase、Spark、Hive、Impala、Kafka、Zookeeper、Flume、HDFS、Yarn等
硬件情况:内存、CPU、磁盘统一高配置
这样的集群还有什么问题呢?
仍然是前文说的软件混合型集群带来的影响,主要是离线任务IO影响大,观测下来,集群磁盘IO到4G以上、集群网络IO 8G以上、HDFS IO 5G以上任意符合一个条件,线上将会有延迟反应。因为离线任务运行太过强势导致RegionServer宕机仍然无法解决,只能重新调整离线任务的执行使用资源、执行顺序等,限制离线计算能力来满足线上的需求。同时还要限制集群的CPU的使用率,可能出现某台机器CPU打满后整个机器假死致服务异常,造成线上故障。
问既然老早就知道原因了,为啥这么多机器了不分几台出来搭个独立的HBase集群?
前期新集群能用的机器比较少,HBase中存储的数据量非常大,只分几个机器出来可能无法满足。
而后期线上交易已经无法允许暂停迁移,只能支援现有集群,现在看来早分离HBase是个明智的选择,然而我们错过了这个选择。
第三阶段 软、硬件独立的HBase集群
目前处于规划中的第三阶段,从集群部署模式上最大程度保证HBase的稳定性。
集群规模:15+5(RS+ZK)
部署服务:HBase、HDFS(另5台虚拟Zookeeper)
硬件情况:除虚拟机外,物理机统一高配置
这里已经从根本上分离了软硬件对HBase所带来的影响。
另外Zookeeper节点不建议只设置3台,5个节点能保证快速选举,可以使用虚拟机,因为ZK节点本身消耗资源并不大,但是5个虚拟节点不能在一个物理机上,一旦物理机挂了相当于5个ZK全挂,会有单点问题,并且ZK节点不在一起可以解决跨网络访问时,外部请求不到的问题。
其他硬件配置,集群使用万兆网卡(千兆对于大数据集群来说实在太小,很容易打满,影响较大),磁盘尽可能大,内存不用太高,一般128G就已经特别多了HBase本身对内存的需求并不是配的越大越好(详见下文)。CPU核数越多越好,HBase本身压缩数据、compaction线程等都是很吃CPU资源的。
Redis前置层
由于目前第二阶段HBase仍然存在许多问题,不是很稳定,在第三阶段投入使用之前,我们添加了一个Redis前置缓存层(8台共800G内存集群),将HBase中最重要最热点的数据写入Redis中,Redis集群异常应用层可直接穿透查询HBase,这样一来对于用户来说我们的服务将会是一直稳定的(然而这仅仅也是理论稳定,后续仍然出现了故障,详见下文)。
Redis作为HBase的前置缓存存在,存储的热点数据量大概是HBase中的20%。至于如何保证Redis集群的稳定又是另外一个话题了。
HBase配置优化
确定完硬件方面的部署结构,下一个关键步骤是对HBase的配置进行优化调整,尽可能发挥硬件的最大优势。
先看一下具体的硬件配置:
总内存:256G
可分配内存:256 * 0.75 = 192G
总硬盘:1.8T * 12 = 21.6T
可用硬盘空间:21.6T * 0.85 = 18.36T
Region规划
对于Region的大小,HBase官方文档推荐单个在10G-30G之间,单台RegionServer的数量控制在20-200之间。
Region过大过小都会有不良影响:
过大的Region
优点:迁移速度快、减少总RPC请求、减少Flush
缺点:compaction的时候资源消耗非常大、可能会有数据分散不均衡的问题
过小的Region
优点:集群负载平衡、HFile比较少compaction影响小
缺点:迁移或者balance效率低、频繁flush导致频繁的compaction、维护开销大
按照官方推荐的配置最多可以存储的数据量大概为200 * 30G * 3= 18T。如果存储的数据量超过18T,或多或少会有些性能问题。从Region规模这个角度讲,当前单台RegionServer能够合理利用起来的硬盘容量上限基本为18T(已提出Sub-Region的概念来满足超大硬盘的需求)。
视磁盘空间、机器数量而定,当前Region配置为:
hbase.hregion.max.filesize=30G
单节点最多可存储的Region个数约为200
Memstore刷写配置
Memstore是Region中的一块内存区域,随着客户端的写入请求增大,将会产生flush的操作将数据内容写入到磁盘。
解释如何配置Memstore刷写参数之前建议提前了解Memstore的刷写机制,简单总结HBase会在如下几种情况下触发flush操作:
Memstore级别:Region中任意一个MemStore达到了 hbase.hregion.memstore.flush.size 控制的上限(默认128MB),会触发Memstore的flush。
Region级别:Region中Memstore大小之和达到了 hbase.hregion.memstore.block.multiplier hbase.hregion.memstore.flush.size 控制的上限(默认 2 128M = 256M),会触发Memstore的flush。
RegionServer级别:Region Server中所有Region的Memstore大小总和达到了 hbase.regionserver.global.memstore.upperLimit * hbase_heapsize 控制的上限(默认0.4,即RegionServer 40%的JVM内存),将会按Memstore由大到小进行flush,直至总体Memstore内存使用量低于 hbase.regionserver.global.memstore.lowerLimit * hbase_heapsize 控制的下限(默认0.38, 即RegionServer 38%的JVM内存)。
RegionServer中HLog数量达到上限:将会选取最早的 HLog对应的一个或多个Region进行flush(通过参数hbase.regionserver.maxlogs配置)。
HBase定期flush:确保Memstore不会长时间没有持久化,默认周期为1小时。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000左右的随机延时。
手动执行flush:用户可以通过shell命令 flush ‘tablename’或者flush ‘region name’分别对一个表或者一个Region进行flush。
需要注意的是MemStore的最小flush单元是Region而不是单个MemStore。一个Region中Memstore越多每次flush的开销越大,即ColumnFamily控制越少越好,一般不超过3个。
Memstore我们主要关注Memstore、Region和RegionServer级别的刷写,其中Memstore和Region级别的刷写并不会对线上造成太大影响,但是需要控制其阈值和刷写频次来进一步提高性能,而RegionServer级别的刷写将会阻塞请求直至刷写完成,对线上影响巨大,需要尽量避免。
配置的重要参数如下:
hbase.hregion.memstore.flush.size=256M: 控制的Memstore大小默认值为128M,太过频繁的刷写会导致IO繁忙,刷新队列阻塞等。
设置太高也有坏处,可能会较为频繁的触发RegionServer级别的Flush,这里设置为256M。hbase.hregion.memstore.block.multiplier=3: 控制的Region flush上限默认值为2,意味着一个Region中最大同时存储的Memstore大小为2 * MemstoreSize ,如果一个表的列族过多将频繁触发,该值视情况调整。
hbase.regionserver.global.memstore.upperLimit: 控制着整个RegionServer中Memstore最大占据的比例,一定程度上可以理解为RS内存中写缓存的大小。详见下文。
内存规划
首先HBase的内存模式可以分为两种:
LRUBlockCache:适用于写多读少型
BucketCache:适用于写少读多型
这两种模式的说明可以参考CDH官方文档。
我们将会选择BucketCache的内存模型来配置HBase,该模式下能够最大化利用内存,减少GC影响,对线上的实时服务较为有利。
讨论具体配置之前,从HBase最佳实践-集群规划引入一个Disk / JavaHeap Ratio的概念来帮助我们设置内存相关的参数。
前面说过,对于HBase来说,内存并不是分配的越大越好,内存给多了GC起来是个灾难,内存大小和硬盘大小之间存在一定的关联。
Disk / JavaHeap Ratio指的是一台RegionServer上1bytes的Java内存大小需要搭配多大的硬盘大小最合理。
Disk / JavaHeap Ratio=DiskSize / JavaHeap = RegionSize / MemstoreSize ReplicationFactor HeapFractionForMemstore * 2
简单公式解释(详细解释见上链接):
硬盘容量维度下Region个数:DiskSize / (RegionSize * ReplicationFactor)
JavaHeap维度下Region个:JavaHeap * HeapFractionForMemstore / (MemstoreSize / 2 )
硬盘维度和Java Headp维度理论相等:DiskSize / (RegionSize *ReplicationFactor) = JavaHeap HeapFractionForMemstore / (MemstoreSize / 2 ) => DiskSize / JavaHeap = RegionSize / MemstoreSize ReplicationFactor HeapFractionForMemstore 2
以默认配置为例:
RegionSize: hbase.hregion.max.filesize=10G
MemstoreSize: hbase.hregion.memstore.flush.size=128M
ReplicationFactor: dfs.replication=3
HeapFractionForMemstore: hbase.regionserver.global.memstore.lowerLimit = 0.4
计算为:10G / 128M 3 0.4 * 2 = 192,即RegionServer上1bytes的Java内存大小需要搭配192bytes的硬盘大小最合理。
集群可用内存为192G,即对应的硬盘空间需要为192G * 192 = 36T,显然这是很不合理的
由于我们能够使用的硬盘只有18T,所以可以适当调小内存,并重新调整以上参数。
写缓存配置
现在根据公式和之前的配置:
DiskSize / JavaHeap = RegionSize / MemstoreSize ReplicationFactor HeapFractionForMemstore * 2
DiskSize:18T
JavaHeap:?
RegionSize:30G
MemstoreSize:256M
ReplicationFactor:3
HeapFractionForMemstore :?
可得 JavaHeap * HeapFractionForMemstore 约等于 24,假设 HeapFractionForMemstore 在0.4-0.6之间波动取值,对应那么 JavaHeap 的大小为60-40G。
这里可以取0.6+40G的配置,因为JavaHeap越大,GC起来就越痛苦,我们可以将多余的内存给到堆外读缓存BucketCache中,这样就可以保证JavaHeap并没有实际浪费。
RegionServer JavaHeap堆栈大小: 40G
hbase.regionserver.global.memstore.upperLimit=0.6: 整个RS中Memstore最大比例
hbase.regionserver.global.memstore.lowerLimit=0.55: 整个RS中Memstore最小比例
读缓存配置
BucketCache模式下HBase的内存布局如图所示:
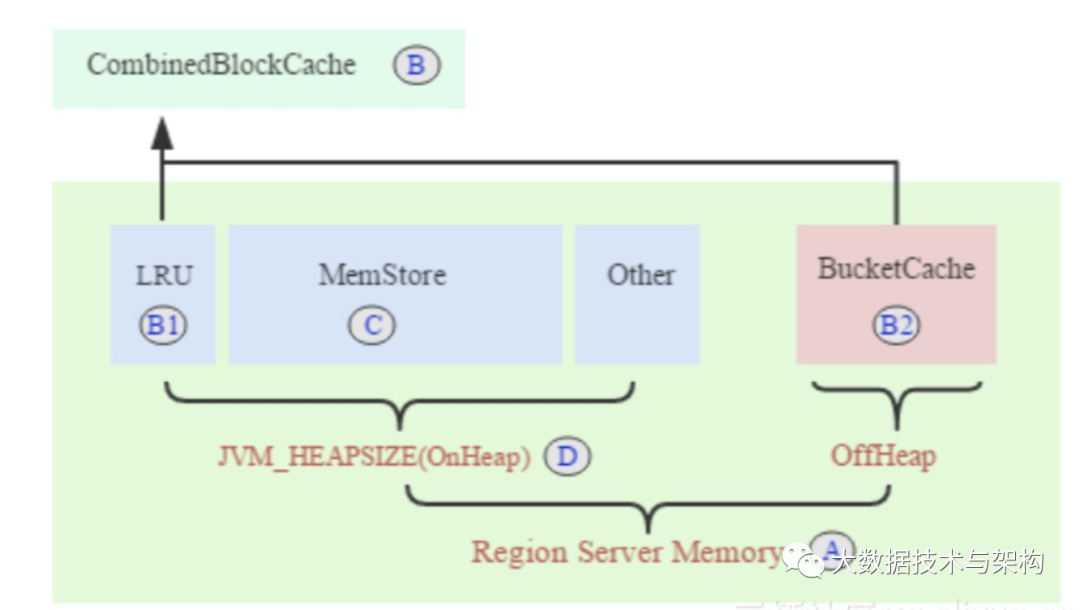
该模式主要应用于线上读多写少型应用,整个RegionServer内存(Java进程内存)分为两部分:JVM内存和堆外内存。
读缓存CombinedBlockCache:LRUBlockCache + 堆外内存BucketCache,用于缓存读到的Block数据
LRUBlockCache:用于缓存元数据Block
BucketCache:用于缓存实际用户数据Block
写缓存MemStore:缓存用户写入KeyValue数据
其他部分用于RegionServer正常运行所必须的内存
当前内存信息如下:
A 总可用内存:192G
D JavaHeap大小:40G
C 写缓存大小:24G
B1 LRU缓存大小:?
B2 BucketCache堆外缓存大小:?
B理论上可以将192-40=152G全部给到堆外缓存,考虑到HDFS进程、其他服务以及预留内存,这里只分配到72G。HBase本身启动时对参数会有校验限制(详见下文检验项)。
TIPS:任何软件使用的硬件资源安全线是80%以下,一旦超出将会有无法预料的问题,这是个传统的运维玄学。曾经在Redis前置层上应验过,相同的数据量相同的写入速度,Redis集群的内存使用率达到了90%直接挂了。
B=B1+B2,B1和B2的比例视情况而定,这里设为1:9。
配置堆外缓存涉及到的相关参数如下:
hbase.bucketcache.size=96 * 1024M: 堆外缓存大小,单位为M
hbase.bucketcache.ioengine=offheap: 使用堆外缓存
hbase.bucketcache.percentage.in.combinedcache=0.9: 堆外读缓存所占比例,剩余为堆内元数据缓存大小
hfile.block.cache.size=0.15: 校验项,+upperLimit需要小于0.8
校验项
LRUBlockCache + MemStore < 80% * JVM_HEAP -> (7.2+24)/40=0.78 <= 0.8
RegionSize / MemstoreSize ReplicationFactor HeapFractionForMemstore 2 -> 30 1024 / 256 3 0.6 2 = 432 -> 40G 432 = 17T <= 18T
hfile.block.cache.size + hbase.regionserver.global.memstore.upperLimit = 0.75 <= 0.8
上一张CDH官方图便于理解offheap下HBase的内存模型:
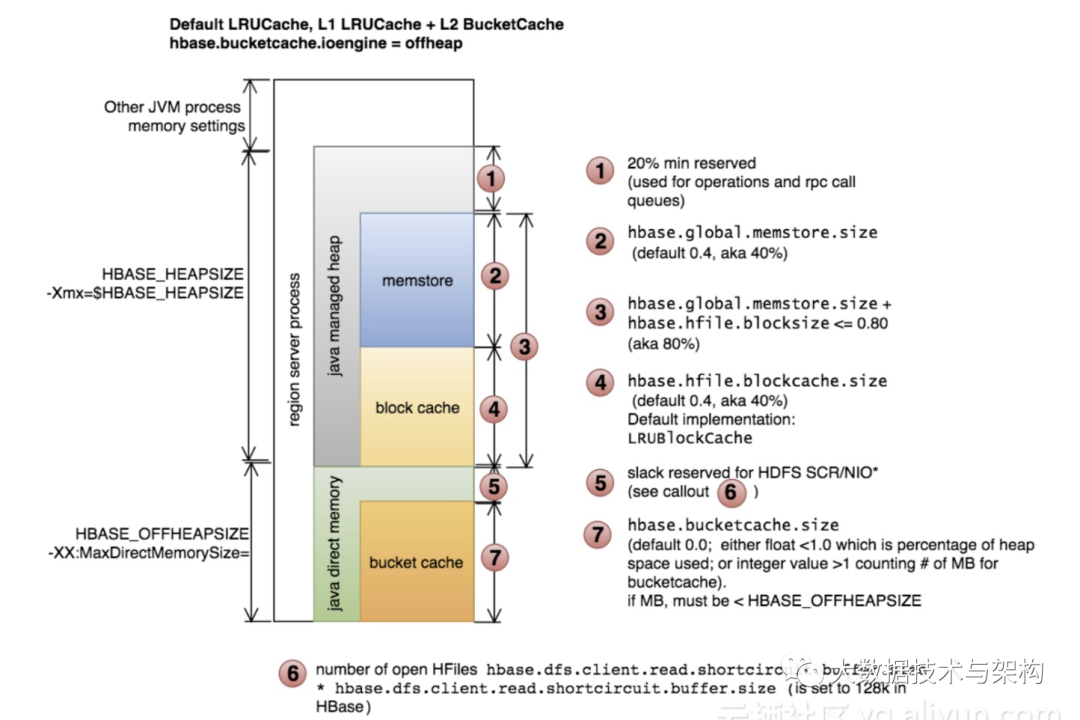
其他HBase服务端配置
应用层响应配置
响应配置的优化能够提升HBase服务端的处理性能,一般情况下默认配置都是无法满足高并发需求的。
hbase.master.handler.count=256: Master处理客户端请求最大线程数
hbase.regionserver.handler.count=256: RS处理客户端请求最大线程数
说明:如果设置小了,高并发的情况下,应用层将会收到HBase服务端抛出的无法创建新线程的异常从而导致应用层线程阻塞。
hbase.client.retries.number=3
hbase.rpc.timeout=5000
说明:默认值太大了,一旦应用层连接不上HBse服务端将会进行近乎无限的重试,从而导致线程堆积应用假死等,影响比较严重,可以适当减少。
- hbase.hstore.blockingStoreFiles=100: storefile个数达到该值则block写入
说明:线上该参数可以调大一些,不然hfile达到指定数量时就会block等到compact。
HDFS相关配置
dfs.datanode.handler.count=64
dfs.datanode.max.transfer.threads=12288
dfs.namenode.handler.count=256
dfs.namenode.service.handler.count=256
配置汇总
RegionServer JavaHeap堆栈大小: 40G
hbase.hregion.max.filesize=30G
hbase.hregion.memstore.flush.size=256M
hbase.hregion.memstore.block.multiplier=3
hbase.regionserver.global.memstore.upperLimit=0.6
hbase.regionserver.global.memstore.lowerLimit=0.55
hbase.bucketcache.size=64 * 1024M
hbase.bucketcache.ioengine=offheap
hbase.bucketcache.percentage.in.combinedcache=0.9
hfile.block.cache.size=0.15
hbase.master.handler.count=256
hbase.regionserver.handler.count=256
hbase.client.retries.number=3
hbase.rpc.timeout=5000
hbase.hstore.blockingStoreFiles=100
这里只给出相对比较重要的配置,其余参数视情况参考文档说明。
应用层使用优化
服务端配置完成之后,如何更好的使用HBase集群也需要花点心思测试与调整。
这里仅介绍Spark操作HBase优化经验,接口服务方面待定。
查询场景
批量查询
Spark有对应的API可以批量读取HBase数据,但是使用过程比较繁琐,这里安利一个小组件Spark DB Connector,批量读取HBase的代码可以这么简单:
val rdd = sc.fromHBase[(String, String, String)]("mytable") .select("col1", "col2") .inColumnFamily("columnFamily") .withStartRow("startRow") .withEndRow("endRow")
done!
实时查询
以流式计算为例,Spark Streaming中,我们要实时查询HBase只能通过HBase Client API(没有队友提供服务的情况下)。
那么HBase Connection每条数据创建一次肯定是不允许的,效率太低,对服务压力比较大,并且ZK的连接数会暴增影响服务。
比较可行的方案是每个批次创建一个链接(类似foreachPartiton中每个分区创建一个链接,分区中数据共享链接)。但是这种方案也会造成部分连接浪费、效率低下等。
如果可以做到一个Streaming中所有批次、所有数据始终复用一个连接池是最理想的状态。
Spark中提供了Broadcast这个重要工具可以帮我们实现这个想法,只要将创建的HBase Connection广播出去所有节点就都能复用,但是真实运行代码时你会发现HBase Connection是不可序列化的对象,无法广播。。。
其实利用scala的lazy关键字可以绕个弯子来实现:
//实例化该对象,并广播使用class HBaseSink(zhHost: String, confFile: String) extends Serializable { //延迟加载特性 lazy val connection = { val hbaseConf = HBaseConfiguration.create() hbaseConf.set(HConstants.ZOOKEEPER_QUORUM, zhHost) hbaseConf.addResource(confFile) val conn = ConnectionFactory.createConnection(hbaseConf) sys.addShutdownHook { conn.close() } conn }}
在Driver程序中实例化该对象并广播,在各个节点中取广播变量的value进行使用。
广播变量只在具体调用value的时候才会去创建对象并copy到各个节点,而这个时候被序列化的对象其实是外层的HBaseSink,当在各个节点上具体调用connection进行操作的时候,Connection才会被真正创建(在当前节点上),从而绕过了HBase Connection无法序列化的情况(同理也可以推导RedisSink、MySQLSink等)。
这样一来,一个Streaming Job将会使用同一个数据库连接池,在Structured Streaming中的foreachWrite也可以直接应用。
写入场景
批量写入
同理安利组件
rdd.toHBase("mytable") .insert("col1", "col2") .inColumnFamily("columnFamily") .save()
这里边其实对HBase Client的Put接口包装了一层,但是当线上有大量实时请求,同时线下又有大量数据需要更新时,直接这么写会对线上的服务造成冲击,具体表现可能为持续一段时间的短暂延迟,严重的甚至可能会把RS节点整挂。
大量写入的数据带来具体大GC开销,整个RS的活动都被阻塞了,当ZK来监测心跳时发现无响应就将该节点列入宕机名单,而GC完成后RS发现自己“被死亡”了,那么就干脆自杀,这就是HBase的“朱丽叶死亡”。
这种场景下,使用bulkload是最安全、快速的,唯一的缺点是带来的IO比较高。
大批量写入更新的操作,建议使用bulkload工具来实现。
实时写入
理同实时查询,可以使用创建的Connection做任何操作。
其他
hbase-env.sh 的 HBase 客户端环境高级配置代码段
配置了G1垃圾回收器和其他相关属性
-XX:+UseG1GC-XX:InitiatingHeapOccupancyPercent=65-XX:-ResizePLAB-XX:MaxGCPauseMillis=90-XX:+UnlockDiagnosticVMOptions-XX:+G1SummarizeConcMark-XX:+ParallelRefProcEnabled-XX:G1HeapRegionSize=32m-XX:G1HeapWastePercent=20-XX:ConcGCThreads=4-XX:ParallelGCThreads=16-XX:MaxTenuringThreshold=1-XX:G1MixedGCCountTarget=64-XX:+UnlockExperimentalVMOptions-XX:G1NewSizePercent=2-XX:G1OldCSetRegionThresholdPercent=5
hbase-site.xml 的 RegionServer 高级配置代码段(安全阀)
手动split region配置
<property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value></property><property> <name>hbase.region.server.rpc.scheduler.factory.class</name> <value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value> <description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description></property><property> <name>hbase.rpc.controllerfactory.class</name> <value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value> <description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description></property><property> <name>hbase.regionserver.thread.compaction.large</name> <value>5</value></property><property> <name>hbase.regionserver.region.split.policy</name> <value>org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy</value></property>
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。







