
一、检查集群状态
1.1 使用sh.status()查看集群摘要信息
1、使用sh.status()可以查看分片信息、数据库信息、集合信息
sh.status()
如果数据块较多时,使用sh.status(true)
又是输出会很多,就不会截断,要使用如下查看
2、too many chunks to print, use verbose if you want to force print
可通过执行以下命令查看
printShardingStatus(db.getSisterDB("config"),1);
1.2 检查配置信息
永远不要直接连接到配置服务器,以防配置服务器被不小心修改或者删除。应先连接到mongos,
然后通过config数据库来查询相关信息,方法与查询其他数据库一样。
>use config
>show tables;
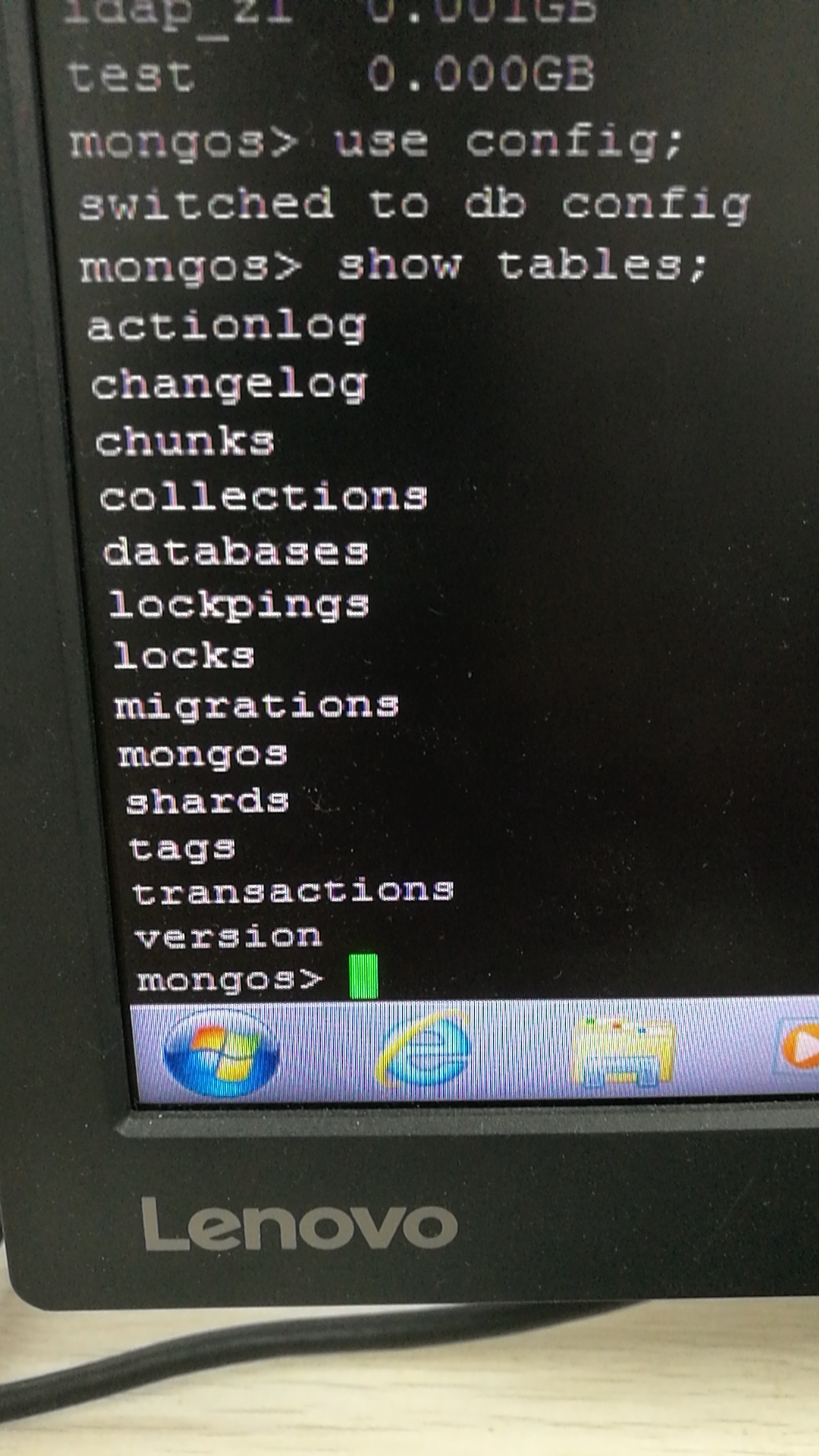
1、config.shards
shards集合跟踪记录集群内所有分片的信息。文档结构如下
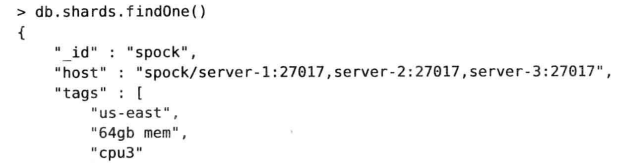
分片的"_id"来自与副本集的名称,所以集群中的每个副本集名称都必须是唯一的。
更新副本集配置的时候(比如添加删除成员),host字段会自动更新
2、config.databases
databases集合跟踪记录集群中所有数据库的信息,不管数据库有没有分片

如果在数据库上执行enableSharding,此处的"partition"字段值是true。
primary是主数据库。数据库的所有集合均默认被创建在数据库的主分片上。
3、config.collections
collections集合跟踪记录所有分片的集合信息(非分片集合信息除外)
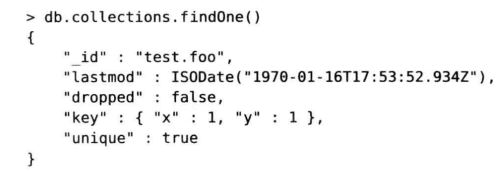
1)_id 集合的命名空间
2)key 片键。本例中由x和y组成的复合片键
3)unique 表明片键是一个唯一索引。该字段只有当值为true时才会出现。片键默认不是唯一的。
4、config.chunks
sh.status()大部分信息来自于config.chunks
chunks集合记录所有集合中所有块的信息。chunks集合中的一个典型文档结构如下

1)_id块的唯一标识符。通常由命名空间、片键和块的下边界值组成
2)ns 块所属的集合名称
3)min 块范围的最小值
4)max 快范围的最大值
5)shard 块所属分片
6)lastmod与lastmodEpoch字段用于记录块的版本
5、config.changelog
changelog集合用于跟踪记录集群的操作,因为该集合会记录所有的拆分和迁移操作。
1)拆分记录文档结构如下


2)当分片收到mongos发来的moveChunk命令时,它会
(1)检查命令的参数
(2)向配置服务器申请获得一个分布锁,一边进入迁移过程
(3)尝试连接到to分片
(4)数据复制,这是整个过程的“临界区”
(5)与to分片和配置服务器一起确认迁移是否成功
6、config.tags
该集合的创建是在为系统配置分片标签时发生的。每个标签都与一个块范围相关联

7、config.settings
该集合含有当前的均衡器设置和块大小的文档信息。
通过修改该集合,可以开启或者关闭均衡器,也可以修改块的大小。
注意:
应该总是连接到mongos修改该集合的值,而不是直接连接到配置服务器
2、对集合分片步骤
1)启动数据库分片
sh.enableSharding("test")
2)启动集合分片
对集合分片时要选择一个分片键(shard key)
如果集合已存在,那么分片键上必须有索引
db.users.ensureIndex({"username":1})
sh.shardCollection("test.users",{"username":1})
3、查看chunk信息
db.chunks.find(criteria,{"min":1,"max":1})











