推荐
专栏
教程
课程
飞鹅
本次共找到10000条
hadoop开发环境搭建
相关的信息
李志宽
•
4年前
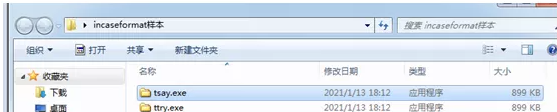
一文 读懂 还原 破解 incaseformat病毒
读懂Incaseformat病毒1.这个病毒的庐山真面目。其实就是个tsay.exe,用delphi语言开发的程序,不过它将应用程序伪装成文件夹的一样的效果,这就是给大家挖了个大坑,大家一般情况下不注意手快就点进去想打开文件夹的那种冲动。2.这个病毒界面的开关这个病毒的界面其实就是一个普通的delphi界面程序,它主要是由一个delphi的label控件和几
Wesley13
•
4年前
SQL解析在美团点评中的应用
数据库作为核心的基础组件,是需要重点保护的对象。任何一个线上的不慎操作,都有可能给数据库带来严重的故障,从而给业务造成巨大的损失。为了避免这种损失,一般会在管理上下功夫。比如为研发人员制定数据库开发规范;新上线的SQL,需要DBA进行审核;维护操作需要经过领导审批等等。而且如果希望能够有效地管理这些措施,需要有效的数据库培训,还需要DBA细心的进行SQL审核
Stella981
•
4年前
React 服务端渲染完美的解决方案
最近在开发一个服务端渲染工具,通过一篇小文大致介绍下服务端渲染,和服务端渲染的方式方法。在此文后面有两中服务端渲染方式的构思,根据你对服务端渲染的利弊权衡,你会选择哪一种服务端渲染方式呢?什么是服务器端渲染使用React构建客户端应用程序,默认情况下,可以在浏览器中输出React组件,进行生成DOM和操作DOM。Re
Wesley13
•
4年前
Java 集合类
为什么使用集合数组长度是固定,如果要改变数组的长度需要创建新的数组将旧数组里面的元素拷贝过去,使用起来不方便。java给开发者提供了一些集合类,能够存储任意长度的对象,长度可以随着元素的增加而增加,随着元素的减少而减少,使用起来方便一些。数组和集合的区别区别1:数组既可以存储基本数据类型,又可以存储引用数据类型,基本数据类
Stella981
•
4年前
APP留存技巧,请给用户一个打开app 的理由
APP推送是维持 APP 留存率最重要的方法之一,但是大多数 APP 开发者都没有正确意识到推送的意义,也没有建立起一套评估 Push 质量的方法。推送是一个典型的双刃剑,如果使用的好可以帮你提升留存率,可是使用不当,甚至滥用将会成为你 APP 的噩梦。但是不幸的是,我看到的大多是推送的不当使用,那有时候就要问了,什么才是真正的APP留存技巧呢?今天小编我就
Wesley13
•
4年前
.NET陷阱之五:奇怪的OutOfMemoryException——大对象堆引起的问题与对策
我们在开发过程中曾经遇到过一个奇怪的问题:当软件加载了很多比较大规模的数据后,会偶尔出现OutOfMemoryException异常,但通过内存检查工具却发现还有很多可用内存。于是我们怀疑是可用内存总量充足,但却没有足够的连续内存了——也就是说存在很多未分配的内存空隙。但不是说.NET运行时的垃圾收集器会压缩使用中的内存,从而使已经释放的内存空隙连成一片吗?
Stella981
•
4年前
JavaScript启动性能瓶颈分析与解决方案
在Web开发中,随着需求的增加与代码库的扩张,我们最终发布的Web页面也逐渐膨胀。不过这种膨胀远不止意味着占据更多的传输带宽,其还意味着用户浏览网页时可能更差劲的性能体验。浏览器在下载完某个页面依赖的脚本之后,其还需要经过语法分析、解释与运行这些步骤。而本文则会深入分析浏览器对于JavaScript的这些处理流程,挖掘出那些影响你应用启动时间的罪
个推技术实践
•
3年前
个推基于Flink SQL建设实时数仓实践
作为一家数据智能企业,个推在服务垂直行业客户的过程中,会涉及到很多数据实时计算和分析的场景,比如在服务开发者时,需要对App消息推送的下发数、到达数、打开率等后效数据进行实时统计;在服务政府单位时,需要对区域内实时人口进行统计和画像分析。为了更好地支撑大数据业务发展,个推也建设了自己的实时数仓。相比Storm、Spark等实时处理框架,Flink不仅具有高吞
WeiSha100
•
3年前
源码员工学习培训考试管理系统
最近单位需要组织员工学习培训考试,花了好几万买了一套系统,可以二次开发使用,免费分享给大家,视频点播可以统计学习进度,也可以组织在线考试,直播和支付功能我们暂时没用到,分享给需要的人展开说一些功能,更多功能有需要的可以下载研究哦:1、视频课程版块:视频课后添加课件,图文,学员可以下载学习2、题库刷题版块:可以批量导入导出培训题目3、直播板版块:对接七牛云端口
WeiSha100
•
3年前
免费版培训机构线上学习考试系统
最近测试了一个培训机构线上学习考试的系统,源码开放,可以线上学习,刷题,直播,在线考试,还有支付功能等,可以建立起一个完整的线上培训系统,源代码和开发文档分享给大家,有需要的可以下载研究哦简单说一下这个系统的主要功能,完整的可以自行下载使用哦1、视频课程:视频课后添加课件,图文,学员可以下载练习2、题库刷题:可以批量导入导出,随时随地刷题练习3、直播:可支持
1
•••
997
998
999
1000