推荐
专栏
教程
课程
飞鹅
本次共找到1077条
bp神经网络算法
相关的信息
22
•
4年前
【排序算法动画解】排序介绍及冒泡排序
本文为系列专题的第12篇文章。1.2.3.4.5.6.7.8.9.10.11.本文先简单介绍一下什么是排序,然后再结合动画介绍暴力排序和冒泡排序。1.什么是排序?排序在日常生活中无处不在。比如考试成绩的排名、体育课的从低到高的队形、网购时按价格升序排列或降序排列等等。|姓名|学号|班级|成绩|||||
Souleigh ✨
•
5年前
PHP对时间轮算法的简单实现
什么是时间轮算法?把任务放到它需要被执行的时刻,然后等待时针转到这个时刻,取出该时刻的任务,执行并将任务从该时刻删除(消费)。解决了什么问题?以商品为例,如何实现商品的过保质期自动失效?1:我们可以每分钟执行一个定时任务,扫描全表过期时间大于当前时间的商品,进行失效处理。(当然,也可以将该任务细化成秒级的)2:商品添加时,将该商品的
公众号: 奋飞安全
•
4年前
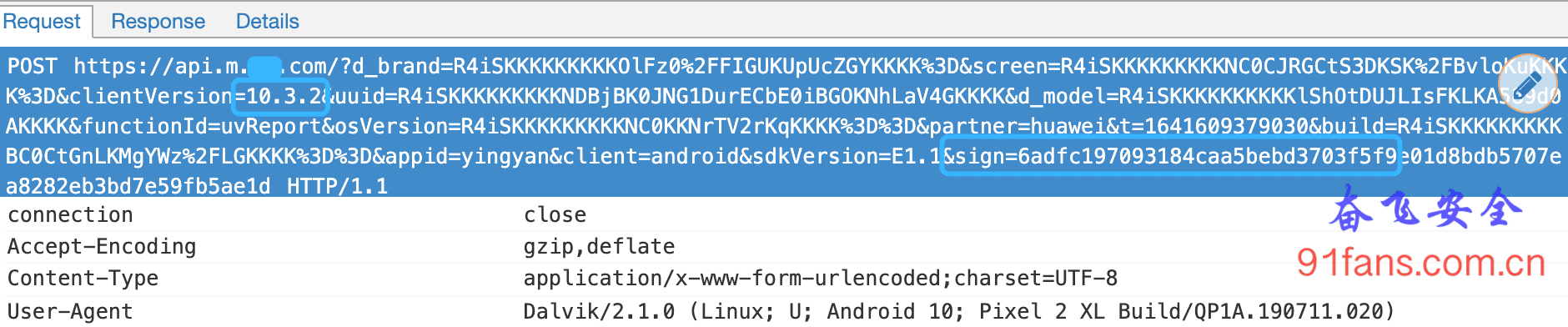
某电商App sign签名算法解析(五)
一、目标李老板:奋飞呀,据说某电商App升级了,搞出了一个64位的sign。更牛的是入参都加密了!奋飞:这么拉风,拉出来咱们盘盘。v10.3.2二、步骤32位和64位我们掌握了那么多方法,先搜字符串呢?还是先Hook呢?子曾经曰过:看到32位签名就要想起MD5和HmacSHA1,看到64位签名就要想起HmacSHA256。那就先搞搞java的密码学相关
桃浪十七丶
•
4年前
Linux、Ubuntu20.04平台安装Clion与OpenGL并实现图形算法--区域填充扫描线算法
要说为什么是Ubuntu,早已经把电脑换成了Ubuntu单系统。一、下载、安装Clion1.或者,Clion官网给出的Ubuntu16以后也可以用下属命令安装,这个选项我还没有尝试。bashsudosnapinstallclionclassic2.安装完毕后,可以先去目标文件夹新建目录bashcd/usr/localbashmkdirclion
专注IP定位
•
4年前
算法推荐规制!《互联网信息服务算法推荐管理规定(征求意见稿)》公开征求意见
互联网信息服务算法推荐管理规定(征求意见稿)第一条为了规范互联网信息服务算法推荐活动,维护国家安全和社会公共利益,保护公民、法人和其他组织的合法权益,促进互联网信息服务健康发展,弘扬社会主义核心价值观,根据《中华人民共和国网络安全法》、《中华人民共和国数据安全法》、《中华人民共和国个人信息保护法》、《互联网信息服务管理办法》等法律、行政法规,制定本规定。第
Stella981
•
4年前
Soft
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!Abstract:我们提出了一种新的方法,通过端到端的训练策略来学习深度架构中的可压缩表征。我们的方法是基于量化和熵的软(连续)松弛,我们在整个训练过程中对它们的离散对应体进行了退火。我们在两个具有挑战性的应用中展示了这种方法:图像压缩和神经网络压缩。虽然这些任务通常是用不同的方法来处理的
Stella981
•
4年前
Kafka中改进的二分查找算法
最近有学习些Kafak的源码,想给大家分享下Kafak中改进的二分查找算法。二分查找,是每个程序员都应掌握的基础算法,而Kafka是如何改进二分查找来应用于自己的场景中,这很值得我们了解学习。由于Kafak把二分查找应用于索引查找的场景中,所以本文会先对Kafka的日志结构和索引进行简单的介绍。在Kafak中,消息以日志的形式保存,每个日志其实就是一个文
Wesley13
•
4年前
OSEA中QRS波检测算法代码分析
最近一直在搞R波检测算法,对OSEA代码主要是对注释做一个翻译,增加注释,使代码更容易理解。一、首先看QRSDE.H/FILE:qrsdet.hAUTHOR:Pat
helloworld_54277843
•
3年前
PyTorch已为我们实现了大多数常用的非线性激活函数
PyTorch已为我们实现了大多数常用的非线性激活函数,我们可以像使用任何其他的层那样使用它们。让我们快速看一个在PyTorch中使用ReLU激活函数的例子:在上面这个例子中,输入是包含两个正值、两个负值的张量,对其调用ReLU函数,负值将取为0,正值则保持不变。现在我们已经了解了构建神经网络架构的大部分细节,我们来构建一个可用于解决真实问题的深度学习架构。
helloworld_91538976
•
3年前
PyTorch已为我们实现了大多数常用的非线性激活函数
PyTorch已为我们实现了大多数常用的非线性激活函数,我们可以像使用任何其他的层那样使用它们。让我们快速看一个在PyTorch中使用ReLU激活函数的例子:在上面这个例子中,输入是包含两个正值、两个负值的张量,对其调用ReLU函数,负值将取为0,正值则保持不变。现在我们已经了解了构建神经网络架构的大部分细节,我们来构建一个可用于解决真实问题的深度学习架构。
1
•••
45
46
47
•••
108