
最近有学习些Kafak的源码,想给大家分享下Kafak中改进的二分查找算法。二分查找,是每个程序员都应掌握的基础算法,而Kafka是如何改进二分查找来应用于自己的场景中,这很值得我们了解学习。
由于Kafak把二分查找应用于索引查找的场景中,所以本文会先对Kafka的日志结构和索引进行简单的介绍。在Kafak中,消息以日志的形式保存,每个日志其实就是一个文件夹,且存有多个日志段,一个日志段指的是文件名(起始偏移)相同的消息日志文件和4个索引文件,如下图所示。
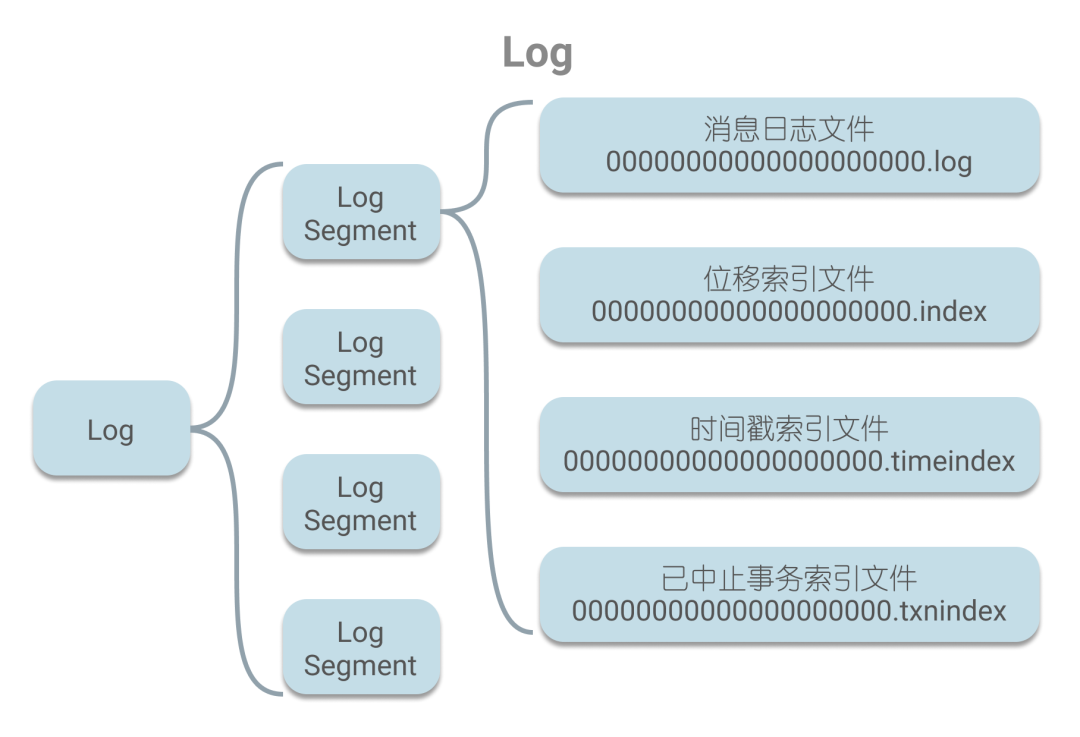
在消息日志文件中以追加的方式存储着消息,每条消息都有着唯一的偏移量。在查找消息时,会借助索引文件进行查找。如果根据偏移量来查询,则会借助位移索引文件来定位消息的位置。为了便于讨论索引查询,下文都将基于位移索引这一背景。位移索引的本质是一个字节数组,其中存储着偏移量和相应的磁盘物理位置,这里偏移量和磁盘物理位置都固定用4个字节,可以看做是每8个字节一个key-value对,如下图:

索引的结构已经清楚了,下面就能正式进入本文的主题“二分查找”。给定索引项的数组和target偏移量,可写出如下代码:
`private def indexSlotRangeFor(idx: ByteBuffer, target: Long, searchEntity: IndexSearchEntity): (Int, Int) = {
// _entries表示索引项的数量
// 1. 如果当前索引为空,直接返回(-1,-1)表示没找到
if (_entries == 0)
return (-1, -1)
// 2. 确保查找的偏移量不小于当前最小偏移量
if (compareIndexEntry(parseEntry(idx, 0), target, searchEntity) > 0)
return (-1, 0)
// 3. 执行二分查找算法,找出target
var lo = 0
var hi = _entries - 1
while (lo < hi) {
val mid = ceil(hi / 2.0 + lo / 2.0).toInt
val found = parseEntry(idx, mid)
val compareResult = compareIndexEntry(found, target, searchEntity)
if (compareResult > 0)
hi = mid - 1
else if (compareResult < 0)
lo = mid
else
return (mid, mid)
}
(lo, if (lo == _entries - 1) -1 else lo + 1)
}
`
上述代码使用了普通的二分查找,下面我们看下这样会存在什么问题。虽然每个索引项的大小是4B,但操作系统访问内存时的最小单元是页,一般是4KB,即4096B,会包含了512个索引项。而找出在索引中的指定偏移量,对于操作系统访问内存时则变成了找出指定偏移量所在的页。假设索引的大小有13个页,如下图所示:

由于Kafka读取消息,一般都是读取最新的偏移量,所以要查询的页就集中在尾部,即第12号页上。下面我们结合上述的代码,看下查询最新偏移量,会访问哪些页。根据二分查找,将依次访问6、9、11、12号页。

当随着Kafka接收消息的增加,索引文件也会增加至第13号页,这时根据二分查找,将依次访问7、10、12、13号页。

可以看出访问的页和上一次的页完全不同。之前在只有12号页的时候,Kafak读取索引时会频繁访问6、9、11、12号页,而由于Kafka使用了mmap来提高速度,即读写操作都将通过操作系统的page cache,所以6、9、11、12号页会被缓存到page cache中,避免磁盘加载。但是当增至13号页时,则需要访问7、10、12、13号页,而由于7、10号页长时间没有被访问(现代操作系统都是使用LRU或其变体来管理page cache),很可能已经不在page cache中了,那么就会造成缺页中断(线程被阻塞等待从磁盘加载没有被缓存到page cache的数据)。在Kafka的官方测试中,这种情况会造成几毫秒至1秒的延迟。
鉴于以上情况,Kafka对二分查找进行了改进。既然一般读取数据集中在索引的尾部。那么将索引中最后的8192B(8KB)划分为“热区”,其余部分划分为“冷区”,分别进行二分查找。代码实现如下:
`private def indexSlotRangeFor(idx: ByteBuffer, target: Long, searchEntity: IndexSearchType): (Int, Int) = {
// 1. 如果当前索引为空,直接返回(-1,-1)表示没找到
if(_entries == 0)
return (-1, -1)
// 二分查找封装成方法
def binarySearch(begin: Int, end: Int) : (Int, Int) = {
var lo = begin
var hi = end
while(lo < hi) {
val mid = (lo + hi + 1) >>> 1
val found = parseEntry(idx, mid)
val compareResult = compareIndexEntry(found, target, searchEntity)
if(compareResult > 0)
hi = mid - 1
else if(compareResult < 0)
lo = mid
else
return (mid, mid)
}
(lo, if (lo == _entries - 1) -1 else lo + 1)
}
/**
* 2. 确认热区首个索引项位。_warmEntries就是所谓的分割线,目前固定为8192字节处
* 对于OffsetIndex,_warmEntries = 8192 / 8 = 1024,即第1024个索引项
* 大部分查询集中在索引项的尾部,所以把尾部的8192字节设置为热区
* 如果查询target在热区索引项范围,直接查热区,避免页中断
*/
val firstHotEntry = Math.max(0, _entries - 1 - _warmEntries)
// 3. 判断target偏移值在热区还是冷区
if(compareIndexEntry(parseEntry(idx, firstHotEntry), target, searchEntity) < 0) {
// 如果在热区,搜索热区
return binarySearch(firstHotEntry, _entries - 1)
}
// 4. 确保要查找的位移值不能小于当前最小位移值
if(compareIndexEntry(parseEntry(idx, 0), target, searchEntity) > 0)
return (-1, 0)
// 5. 如果在冷区,搜索冷区
binarySearch(0, firstHotEntry)
}
`
这样做的好处是,在频繁查询尾部的情况下,尾部的页基本都能在page cahce中,从而避免缺页中断。
下面我们还是用之前的例子来看下。由于每个页最多包含512个索引项,而最后的1024个索引项所在页会被认为是热区。那么当12号页未满时,则10、11、12会被判定是热区;而当12号页刚好满了的时候,则11、12被判定为热区;当增至13号页且未满时,11、12、13被判定为热区。假设我们读取的是最新的消息,则在热区中进行二分查找的情况如下:
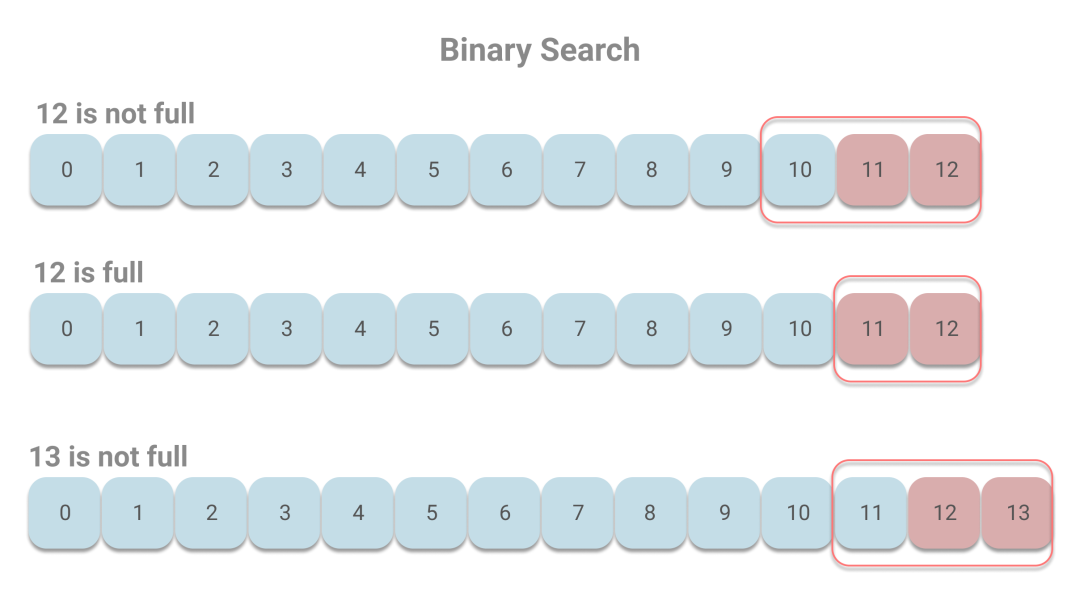
当12号页未满时,依次访问11、12号页,当12号页满时,访问页的情况相同。当13号页出现的时候,依次访问12、13号页,不会出现访问长时间未访问的页,则能有效避免缺页中断。
关于为什么设置热区大小为8192字节,官方给出的解释,这是一个合适的值:
足够小,能保证热区的页数小于等于3,那么当二分查找时的页面都很大可能在page cache中。也就是说如果设置的太大了,那么可能出现热区中的页不在page cache中的情况。
足够大,8192个字节,对于位移索引,则为1024个索引项,可以覆盖4MB的消息数据,足够让大部分在in-sync内的节点在热区查询。
最后一句话总结下:在Kafka索引中使用普通二分搜索会出现缺页中断的现象,造成延迟,且结合查询大多集中在尾部的情况,通过将索引区域划分为热区和冷区,分别搜索,将尽可能保证热区中的页在page cache中,从而避免缺页中断。
本文分享自微信公众号 - java宝典(java_bible)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












