推荐
专栏
教程
课程
飞鹅
本次共找到117条
键值
相关的信息
执键写春秋
•
4年前
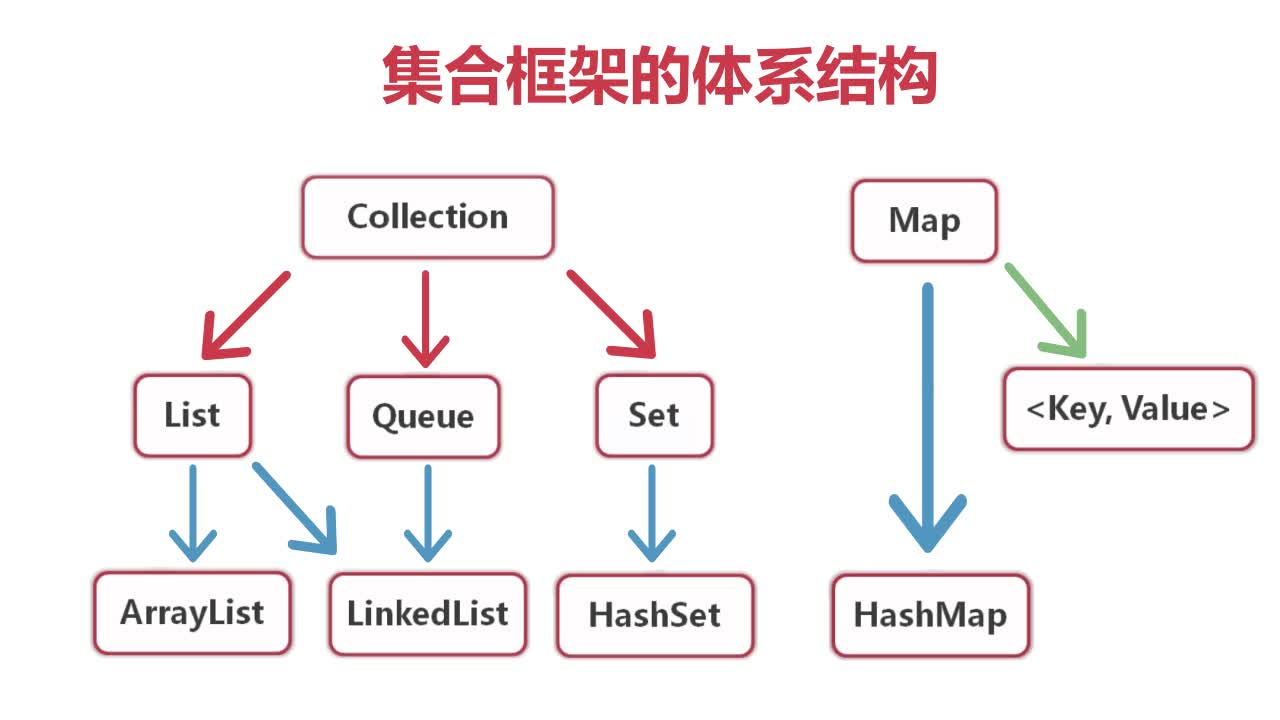
Java集合之综合论述
1.Java集合1.1集合应用场景1.无法预测存储数据的数量的情况下,2.同时存储一对一关系的数据3.需要进行数据的增删4.数据重复问题1.2集合框架的体系结构集合框架分为两类,一是Collection,用于存储类的对象。二是Map,以键值对的形式存储信息。Collection主要有三个子接口,List(序列),Queue(队列
Wesley13
•
4年前
Oracle序列Sequence
Oracle序列Sequence解释一.对于序列的定义序列(Sequence)是序列号生成器,可以为表中的行自动生成序列号,产生一组等间隔的数值(类型为数字)。不占用磁盘空间,占用内存。其主要用途是生成表的主键值,可以在插入语句中引用,也可以通过查询检查当前值,或使序列增至下一个值。 二.创建序列 需要权限,CREATESEQUENC
Wesley13
•
4年前
MongoDB 基本使用
MongoDB是一个基于分布式文件存储的数据库。由C语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。MongoDB将数据存储为一个文档,数据结构由键值(keyvalue)对组成。MongoDB文档(
Stella981
•
4年前
IOS数据存储之NSUserDefaults
概述数据存储是开发中必不可少的一个功能,我们可以通过Sqlite数据库手动创建数据库,定义数据表;可以使用IOS的数据框架CoreData,更方便的操作数据库;也可以直接读写文件系统;这里将介绍另外一种常用的方法:使用NSUserDefaults类,以字典形式保存数据,IOS会自动把字典中的键值对转换成对应的XML文件(也就是plist文件),这
Stella981
•
4年前
Lua中table的实现
本文来自《Lua设计与实现》的阅读笔记,推荐Lua学习者可以购买一本,深入浅出讲解lua的设计和实现原理,很赞,哈哈Lua中对于表的设计,是基于数组和散列表,和其他语言不同,对于数组的下标是从1开始的,对于散列表而言,只要其键值补位nil,都可以存储在其中。一、table的基本类型定义首先看看table的数据定义,参考源码lobject.
Stella981
•
4年前
Couchbase 中的分布式储存
概述Couchbase是一个具有高性能、可扩展性和可用性强的数据库引擎。它可以让开发人员通过 NoSQL 的键值存储(二进制或者JSON)或者使用N1QL的形式对数据进行操作(N1QL是非常类似于SQL的一种语法操作JSON数据的方式)。以现在整体架构来看,Couchbase是往分布式数据库的方向发展下去。分布式数据库一
Stella981
•
4年前
Redis分布式缓存系统Lua脚本食用指引
Redis为什么添加Lua支持redislua脚本出现之前Redis是没有服务器端运算能力的,主要是用来存储,用做缓存,运算是在客户端进行,这里有两个缺点:一、如此会破坏数据的一致性,试想如果两个客户端先后获取(get)一个值,它们分别对键值做不同的修改,然后先后提交结果,最终Redis服务器中的结果肯定不是某一方客户端所预期的
Stella981
•
4年前
List、Map、Set三个接口存取元素时,各有什么特点
List接口以特定索引来存取元素,可以有重复元素Set接口不可以存放重复元素(使用equals方法区分是否重复)Map接口保存的是键值对(keyvaluepair)映射,映射关系可以是一对一或者多对一(key唯一)Set和Map容器都有基于哈希存储和排序树的两种实现版本。基于哈希存储的版本的实现理论存取时间复杂度是O(1),而基于排序树版本的
Stella981
•
4年前
MemCache 入门极简教程
MemCache概述MemCache虽然被称为”分布式缓存”,但是MemCache本身完全不具备分布式的功能Memcache是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度。MemCaChe是一个存储键值对的Hash
此账号已注销
•
3年前
云原生多模型 NoSQL 概述
作者朱建平,TEG/云架构平台部/块与表格存储中心副总监。08年加入腾讯后,承担过对象存储、键值存储,先后负责过KV存储TSSD、对象存储TFS等多个存储平台。NoSQL技术和行业背景NoSQL是对不同于传统关系型数据库的一个统称,提出NoSQL的初衷是针对某些场景简化关系型数据库的设计,更容易水平扩展存储和计算,更侧重于实现高并发、高可用和高伸缩
1
•••
10
11
12