
本文来自《Lua设计与实现》的阅读笔记,推荐Lua学习者可以购买一本,深入浅出讲解lua的设计和实现原理,很赞,哈哈
Lua中对于表的设计,是基于数组和散列表,和其他语言不同,对于数组的下标是从1开始的,对于散列表而言,只要其键值补位nil,都可以存储在其中。
一、table的基本类型定义
首先看看table的数据定义,参考源码lobject.h

CommonHeader, 参看专栏前面的文章;
flags 这是一个lua的byte类型的数据,用于表示表中提供了哪些元方法,比如是否提供了元方法_index,该数据最开始设置为1,如果进行查找一次,比如_index,如果存在,这该元方法对应的flag bit设置为0,在下一次查找的时候,只需要比较这个bit即可,对应的元方法在ltm.h中
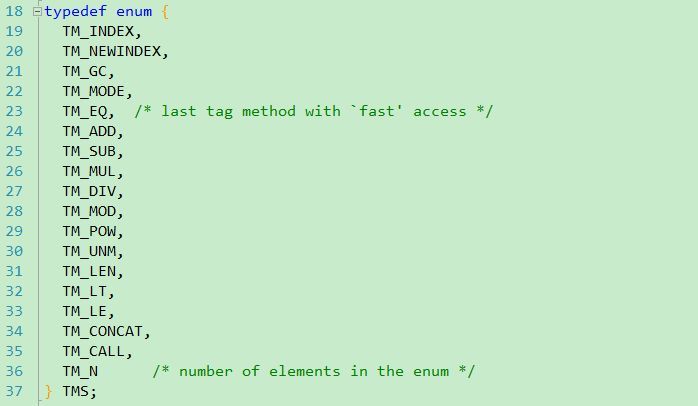
lsizenode,为散列表的大小,必定为2的幂对应的数字;
metatable,该table的元表;
array,该table的数组的指针
node, 该table的散列表的起始位置的指针;
lastfree, 该散列表的最后位置的指针
gclist, gc相关的链表
sizearray, 数组的大小,不一定为2的幂对应的数字
对于node数据,类似于其他语言中的字典设计\hash设计,就是一个键值对集合,其定义为:
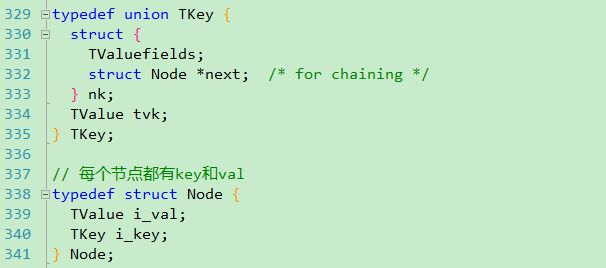
需要提一下的是对于key的设计采用的是union,也就是说Lua的散列表的key,可以为nk对应的struct,也可以是TValue类型
二、table相关的操作的实现原理
1、查找算法的实现原理
借用原文的伪代码:
if 输入的key为整数 && key >= 0 && key <= 数组的大小
尝试在数组部分查找
else 在散列表部分查找
计算出该key的散列值,据其查找对应的node所在散列表中的位置,然后遍历其对应的链表,查找是否有该key对应的元素
举例:
local t = {}
t[1] = 0
t[100] = 0
那么1是在数组中查找,100就是在散列表中去查找了(100大于数组的len)
2、新增元素的实现原理
给lua中添加新元素的时候,会有可能触发重新分配table中的数组和散列表,其本质来自于散列表的rehash(由于lua对于下标超过数组的大小的数字,都会存储在散列表部分去,所以数组部分的插值不会触发rehash)
散列表的组织,就是多个mainposition,每个单独的mainposition会对应一个数据链表,当插入一个key的时候,会调用luaHset\luaH_setnum\luaH_setstr,来获得该key对应的TValue指针,如果没有,则调用内部的newkey函数来分配一个新的key:
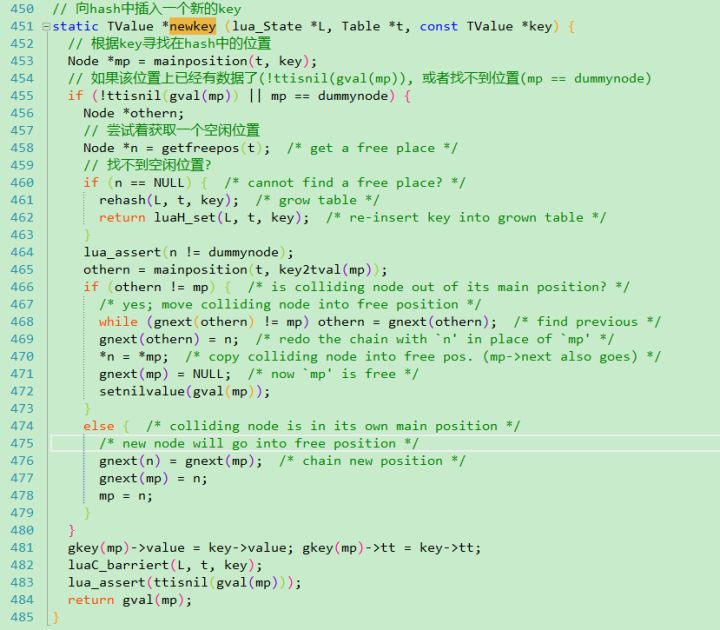
基本的实现过程看源代码写的比较详细,这儿说一下rehash部分的操作,在ltable.c中:
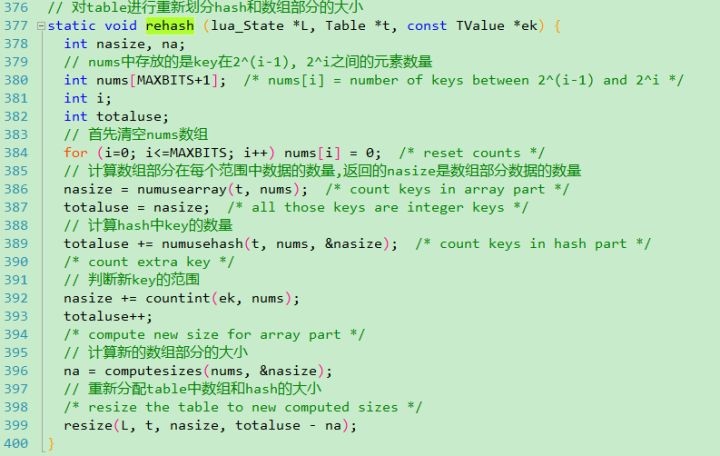
- nums中存放的是元素的数量
2)分表遍历数组(numusearray)和散列表(numusehash),统计更新nums中的数量大小
- 重新计算数组和hash部分的大小,数组大小的计算规则:逐个遍历nums数组,获得其范围区间内所包含的整数数量大于50%的最大索引,作为rehash后的数组大小,这个索引值来自与computesizes函数:

可能看了会有点迷糊,那我就用大白话说一下吧:
首先nums数组在统计后,每个下标对应的是处于当前2^(i -1) - 2^i中的元素的个数,然后不断的累加计算,求得满足 sum > 2^n/2的最大下标值(这个下标值是nums数组中的)
所以,在不同的rehash阶段,table中的同一个key可能会在数组部分和散列表部分交替出现,也是可能的。
由于rehash会带来较大的性能消耗,所以一般都尽量避免,比如在创建表的时候,就采用预填充的算法
3、取长度算法的原理
如果table中元表没有重载len方法,则调用的是luaH_getn方法,其基本的伪代码为:
if 表中存在数组部分:
初始化i = 0, j = sizearray
while(j - i > 1){
m = (j + i)/2
if(array[m-1] == nil)
j = m
else
i = m
}
return i
else
查找表中散列表长度,算法同数组部分
对于表中只有散列表的时候,其实质就是对键值为正整数的部分进行长度操作,如果既有数组,又有散列表,则优先对数组部分进行长度操作











