推荐
专栏
教程
课程
飞鹅
本次共找到1796条
邮件客户端
相关的信息
Dax
•
4年前
Cookie和Session
Cookie是浏览器(UserAgent)访问一些网站后,这些网站存放在客户端的一组数据,用于使网站等跟踪用户,实现用户自定义功能。Cookie的Domain和Path属性标识了这个Cookie是哪一个网站发送给浏览器的;Cookie的Expires属性标识了Cookie的有效时间,当Cookie的有效时间过了之后,这些数据就被自动删除了。如果不设置
灯灯灯灯
•
4年前
年后腾讯二面,第一个问MySQL主从结构,给我整不会了
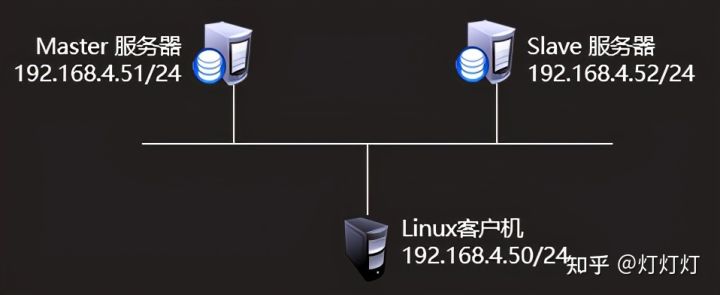
一、MySQL一主一从数据库服务器192.168.4.51配置为主数据库服务器数据库服务器192.168.4.52配置为从数据库服务器客户端192.168.4.50测试配置其中192.168.4.51是主服务器,另一台192.168.4.52作为从服务器,通过调取主服务器上的binlog日志,在本地重做对应的库、表,实现与主服务器的数据同步
Stella981
•
4年前
Linux之sersync数据实时同步
sersync其实是利用inotify和rsync两种软件技术来实现数据实时同步功能的,inotify是用于监听sersync所在服务器上的文件变化,结合rsync软件来进行数据同步,将数据实时同步给客户端服务器。 工作过程:在同步主服务器上开启sersync,负责监听文件系统的变化,然后调用rsync命令把更新的文件同步到目标服务器上,主服务器上
Stella981
•
4年前
BurpSuite实战——合天网安实验室学习笔记
burpsuite是一款功能强大的用于攻击web应用程序的集成平台,通常在服务器和客户端之间充当一个双向代理,用于截获通信过程中的数据包,对于截获到的包可以人为的进行修改和重放。此BurpSuite实战主要包括两个实验:分别是使用burp进行暴力破解和Burpsuite简介及MIME上传绕过实例。链接:合天网安实验室(http
Stella981
•
4年前
Redis+Lua——他叫了外援
Redis从2.6版本开始引入对Lua脚本的支持,通过在Redis服务器中嵌入Lua环境,Redis客户端可以使用Lua脚本,直接在服务端原子的执行多个Redis命令。Lua Lua是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。为
Wesley13
•
4年前
HttpClient学习 使用 详解
Http协议的重要性相信不用我多说了,HttpClient相比传统JDK自带的URLConnection,增加了易用性和灵活性(具体区别,日后我们再讨论),它不仅是客户端发送Http请求变得容易,而且也方便了开发人员测试接口(基于Http协议的),即提高了开发的效率,也方便提高代码的健壮性。因此熟练掌握HttpClient是很重要的必修内容,掌握HttpCl
Stella981
•
4年前
Electron 在 Taro IDE 的开发实践
背景—TaroIDE是一款我们正在精心打造的一站式移动端研发工作台。除了需要实现Taro从创建项目到预览、编译的全部能力,还需要打通用户测试、调试、监控等一系列流程。为了提升开发体验,仅仅一个命令行工具是远远不够的,我们需要开发一款桌面客户端,并同时提供Windows、MacOS等不同系统的版本。Electron\1\ 最初是
Stella981
•
4年前
RabbitMQ学习:RabbitMQ的基本概念及RabbitMQ使用场景(二)
1、RabbitMQ的基本概念RabbitMQ是一种消息中间件,用于处理来自客户端的异步消息。服务端将要发送的消息放入到队列池中。接收端可以根据RabbitMQ配置的转发机制接收服务端发来的消息。RabbitMQ依据指定的转发规则进行消息的转发、缓冲和持久化操作,主要用在多服务器间或单服务器的子系统间进行通信,是分布式系统
Stella981
•
4年前
RabbitMQ学习:安装RabbitMQ及RabbitMQ的初步配置(一)
RabbitMQ基础含义RabbitMQ是一种消息中间件,用于处理来自客户端的异步消息。服务端将要发送的消息放入到队列池中。接收端可以根据RabbitMQ配置的转发机制接收服务端发来的消息。RabbitMQ依据指定的转发规则进行消息的转发、缓冲和持久化操作,主要用在多服务器间或单服务器的子系统间进行通信,是分布式系统标准的配置。
Stella981
•
4年前
Hystrix (容错,回退,降级,缓存)
Hystrix熔断机制就像家里的保险丝一样,若同时使用高功率的电器,就会烧坏电路,这时候保险丝自动断开就有效的保护了电路。而我们程序中也同样是这样。例如若此时数据库压力太大速度很慢,此时还有不断的请求访问后台,就会造成数据库崩溃。这时候hystrix容错机制,可以为客户端请求设置超时链接,添加回退的逻辑,减少集群压力。!(https://os
1
•••
169
170
171
•••
180