
1、RabbitMQ的基本概念
RabbitMQ是一种消息中间件,用于处理来自客户端的异步消息。服务端将要发送的消息放入到队列池中。接收端可以根据RabbitMQ配置的转发机制接收服务端发来的消息。RabbitMQ依据指定的转发规则进行消息的转发、缓冲和持久化操作,主要用在多服务器间或单服务器的子系统间进行通信,是分布式系统标准的配置。
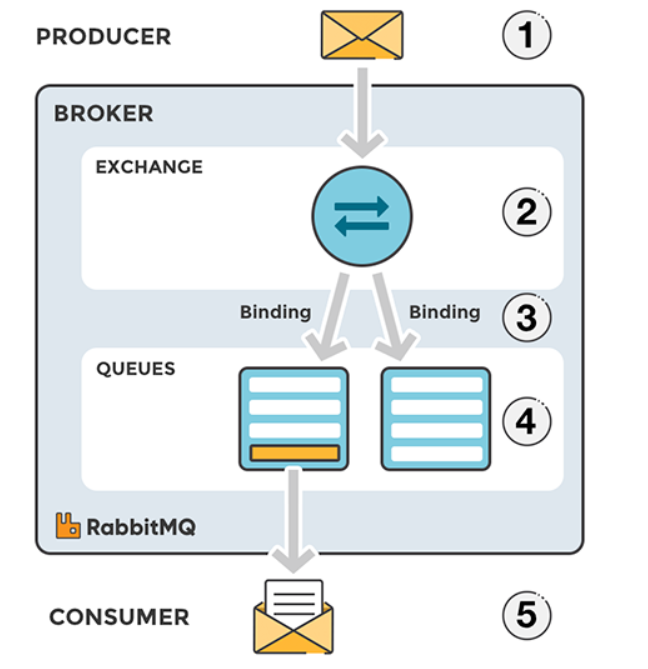
Exchange
接受生产者发送的消息,并根据Binding规则将消息路由给服务器中的队列。ExchangeType决定了Exchange路由消息的行为。在RabbitMQ中,ExchangeType常用的有direct、Fanout和Topic三种。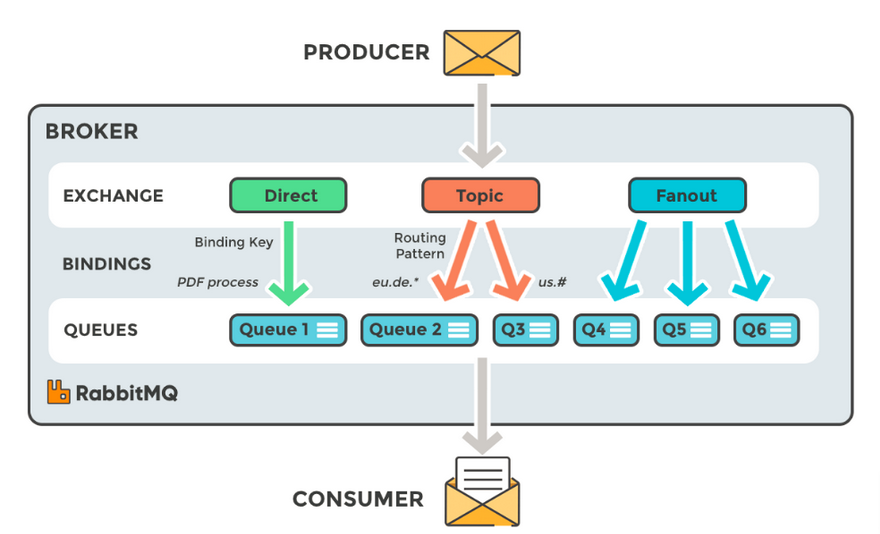
Message Queue
消息队列。我们发送给RabbitMQ的消息最后都会到达各种queue,并且存储在其中(如果路由找不到相应的queue则数据会丢失),等待消费者来取。
Binding Key
它表示的是Exchange与Message Queue是通过binding key进行联系的,这个关系是固定。
Routing Key
生产者在将消息发送给Exchange的时候,一般会指定一个routing key,来指定这个消息的路由规则。这个routing key需要与Exchange Type及binding key联合使用才能生,我们的生产者只需要通过指定routing key来决定消息流向哪里。
2、RabbitMQ 使用场景
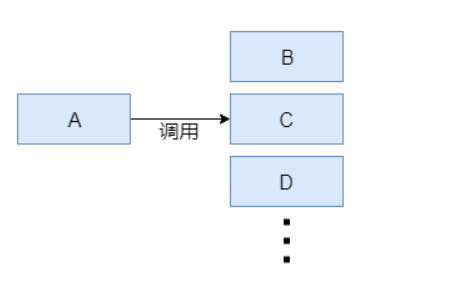
服务解耦
假设有这样一个场景, 服务A产生数据, 而服务B,C,D需要这些数据, 那么我们可以在A服务中直接调用B,C,D服务,把数据传递到下游服务即可。
但是,随着我们的应用规模不断扩大,会有更多的服务需要A的数据,如果有几十甚至几百个下游服务,而且会不断变更,再加上还要考虑下游服务出错的情况,那么A服务中调用代码的维护会极为困难。
这是由于服务之间耦合度过于紧密。
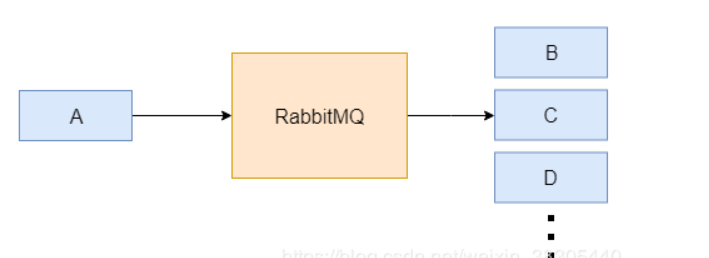
再来考虑用RabbitMQ解耦的情况。
A服务只需要向消息服务器发送消息,而不用考虑谁需要这些数据;下游服务如果需要数据,自行从消息服务器订阅消息,不再需要数据时则取消订阅即可。
流量削峰
假设我们有一个应用,平时访问量是每秒300请求,我们用一台服务器即可轻松应对。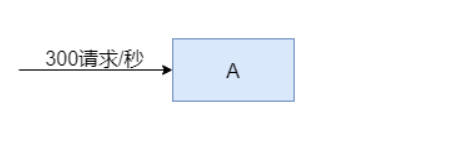
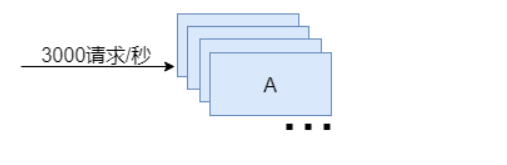
而在高峰期,访问量瞬间翻了十倍,达到每秒3000次请求,那么单台服务器肯定无法应对,这时我们可以考虑增加到10台服务器,来分散访问压力。
但如果这种瞬时高峰的情况每天只出现一次,每次只有半小时,那么我们10台服务器在多数时间都只分担每秒几十次请求,这样就有点浪费资源了。
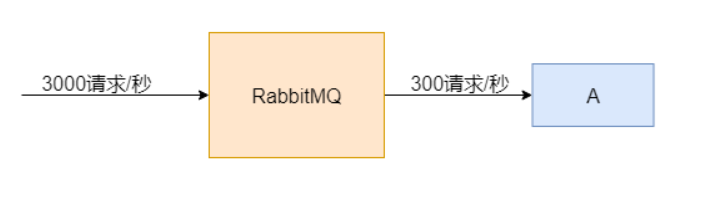
这种情况,我们就可以使用RabbitMQ来进行流量削峰,高峰情况下,瞬间出现的大量请求数据,先发送到消息队列服务器,排队等待被处理,而我们的应用,可以慢慢的从消息队列接收请求数据进行处理,这样把数据处理时间拉长,以减轻瞬时压力。
这是消息队列服务器非常典型的应用场景。
异步调用
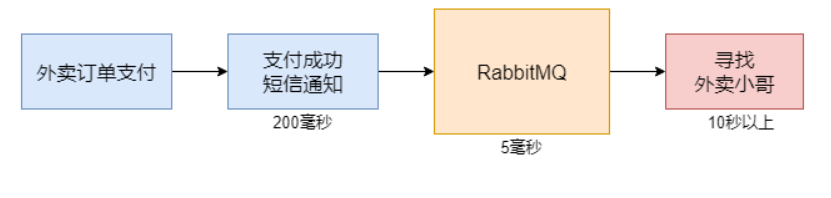
考虑定外卖支付成功的情况。
支付后要发送支付成功的通知,再寻找外卖小哥来进行配送,而寻找外卖小哥的过程非常耗时,尤其是高峰期,可能要等待几十秒甚至更长。
这样就造成整条调用链路响应非常缓慢。
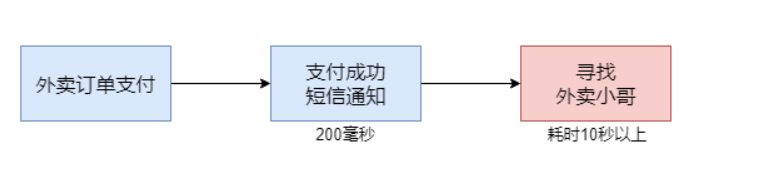
而如果我们引入RabbitMQ消息队列,订单数据可以发送到消息队列服务器,那么调用链路也就可以到此结束,订单系统则可以立即得到响应,整条链路的响应时间只有200毫秒左右。
寻找外卖小哥的应用可以以异步的方式从消息队列接收订单消息,再执行耗时的寻找操作。
上一篇:RabbitMQ学习:安装RabbitMQ及RabbitMQ的初步配置(一) --- https://my.oschina.net/u/4115134/blog/3217755
下一篇:RabbitMQ学习:RabbitMQ的六种工作模式之简单和工作模式(三) --- https://my.oschina.net/u/4115134/blog/3228182









