推荐
专栏
教程
课程
飞鹅
本次共找到1094条
递归算法
相关的信息
Irene181
•
4年前
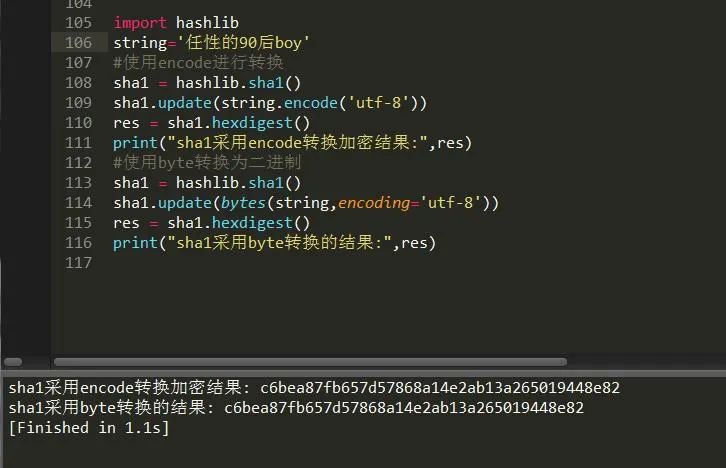
盘点Python加密解密模块hashlib的7种加密算法
大家好,我是黄伟。今天给大家介绍hashlib模块!前言在程序中我们经常可以看到有很多的加密算法,比如说MD5sha1等,今天我们就来了解下这下加密算法的吧,在了解之前我们需要知道一个模块嘛就是hashlib,他就是目前Python一个提供字符加密的模块,它加密的字符类型为二进制编码,所以直接加密字符串会报错。importhashlibstring'任
Souleigh ✨
•
5年前
PHP对时间轮算法的简单实现
什么是时间轮算法?把任务放到它需要被执行的时刻,然后等待时针转到这个时刻,取出该时刻的任务,执行并将任务从该时刻删除(消费)。解决了什么问题?以商品为例,如何实现商品的过保质期自动失效?1:我们可以每分钟执行一个定时任务,扫描全表过期时间大于当前时间的商品,进行失效处理。(当然,也可以将该任务细化成秒级的)2:商品添加时,将该商品的
李志宽
•
4年前
黑客赚钱的路子有多野?CTF逆向入门指南
1、背景在CTF比赛中,CTF逆向题目除了需要分析程序工作原理,还要根据分析结果进一步求出FLAG。逆向在解题赛制中单独占一类题型,同时也是PWN题的前置技能。在攻防赛制中常与PWN题结合。CTF逆向主要涉及到逆向分析和破解技巧,这也要求有较强的反汇编、反编译、加解密的功底。CTF中的逆向题目一般常见考点1、常见算法与数据结构。2、各种排序算法,树,
桃浪十七丶
•
4年前
Linux、Ubuntu20.04平台安装Clion与OpenGL并实现图形算法--区域填充扫描线算法
要说为什么是Ubuntu,早已经把电脑换成了Ubuntu单系统。一、下载、安装Clion1.或者,Clion官网给出的Ubuntu16以后也可以用下属命令安装,这个选项我还没有尝试。bashsudosnapinstallclionclassic2.安装完毕后,可以先去目标文件夹新建目录bashcd/usr/localbashmkdirclion
Wesley13
•
4年前
java 数据结构(五):数据结构简述
1.数据结构概述数据结构(DataStructure是一门和计算机硬件与软件都密切相关的学科,它的研究重点是在计算机的程序设计领域中探讨如何在计算机中组织和存储数据并进行高效率的运用,涉及的内容包含:数据的逻辑关系、数据的存储结构、排序算法(Algorithm)、查找(或搜索)等。2.数据结构与算法的理解程序能否快速而高效地完成预定的任务,
专注IP定位
•
4年前
算法推荐规制!《互联网信息服务算法推荐管理规定(征求意见稿)》公开征求意见
互联网信息服务算法推荐管理规定(征求意见稿)第一条为了规范互联网信息服务算法推荐活动,维护国家安全和社会公共利益,保护公民、法人和其他组织的合法权益,促进互联网信息服务健康发展,弘扬社会主义核心价值观,根据《中华人民共和国网络安全法》、《中华人民共和国数据安全法》、《中华人民共和国个人信息保护法》、《互联网信息服务管理办法》等法律、行政法规,制定本规定。第
Wesley13
•
4年前
MD5 SHA1 HMAC HMAC_SHA1区别
MD5是一种不可逆的加密算法,目前是最牢靠的加密算法之一,尚没有能够逆运算的程序被开发出来,它对应任何字符串都可以加密成一段唯一的固定长度的代码。SHA1是由NISTNSA设计为同DSA一起使用的,它对长度小于264的输入,产生长度为160bit的散列值,因此抗穷举(bruteforce)性更好。HMAC\_SHA1
Stella981
•
4年前
Kafka中改进的二分查找算法
最近有学习些Kafak的源码,想给大家分享下Kafak中改进的二分查找算法。二分查找,是每个程序员都应掌握的基础算法,而Kafka是如何改进二分查找来应用于自己的场景中,这很值得我们了解学习。由于Kafak把二分查找应用于索引查找的场景中,所以本文会先对Kafka的日志结构和索引进行简单的介绍。在Kafak中,消息以日志的形式保存,每个日志其实就是一个文
Stella981
•
4年前
JVM03
前言今天来学习下与JVM垃圾收集机制相关的一些基本概念。如何判断对象是否存活垃圾收集器首要的任务的任务就是判断哪些对象是存活的,哪些对象已经死去了(这里死去的意思是对象不再被任何途径使用)。引用计数算法引用计数算法是在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一;当引用失效时,计数器
京东云开发者
•
2年前
基于Raft算法的DLedger-Library分析 | 京东物流技术团队
在分布式系统应用中,高可用、一致性是经常面临的问题,针对不同的应用场景,我们会选择不同的架构方式,比如masterslave、基于ZooKeeper选主。随着时间的推移,出现了基于Raft算法自动选主的方式,Raft是在Paxos的基础上,做了一些简化和限制,比如增加了日志必须是连续的,只支持领导者、跟随者和候选人三种状态,在理解和算法实现上都相对容易许多。
1
•••
46
47
48
•••
110