推荐
专栏
教程
课程
飞鹅
本次共找到3129条
解释型语言
相关的信息
Irene181
•
4年前
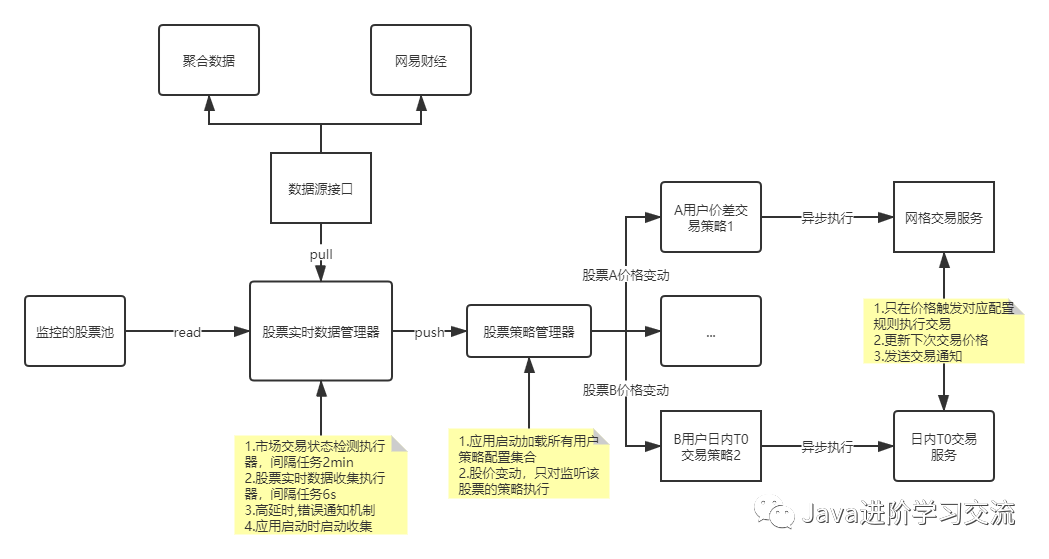
项目实战——打造一款股票区间交易盯盘系统
一、简介大家好,我是Snowball。今天给大家分享的内容是基于Java编程,实现股票交易相关功能开发,如果读者对股票或金融衍生物交易不太了解,又比较感兴趣的话可自行查询相关资料。在这篇文章里边,介绍了两个策略,,这篇文章,我们来实战个大的项目。常见的交易策略有很多种,例如趋势型,网格型,剥头皮,概率法则,高频交易等,今天主要给大家介绍2种低频的交易
Wesley13
•
4年前
C语言编译器为什么能够用C语言编写?
不知道大家有没有想过一个问题:C语言编译器为什么能够用C语言编写?所谓C语言编译器,就是把编程得到的文件,比如.c,.h的文件,进行读取,并对内容进行分析,按照C语言的规则,将其转换成cpu可以执行的二进制文件。在学习C/C或者想要学习C/C可以加入我们的学习交流QQ群:954607083,领取学习资料其本质在于对文件的读入,分析,及
Stella981
•
4年前
B端和C端销售差异
之前遇到过几个资深做销售的人,讨论起C端和B端销售问题。他们觉得销售是相同的呀,只有这个人销售能力强,销售B端管理软件也没有问题呀。每次都要费尽口舌跟他们解释B端管理软件销售的难点所在。虽然本身不是做销售出身,但在B端管理软件从业那么久,也是深知C端和B端的区别的,下面就具体解释说明一下。B端要求更多的专业知识,决策时间长,而C端正好相反C端
Wesley13
•
4年前
Objective
一、基本概念ObjectiveC(简称OC)是iOS开发的核心语言,苹果公司在维护,在开发过程中也会配合着使用C语言、C,OC主要负责UI界面,C语言、C可用于图形处理。C语言是面向过程的语言,OC是在C语言基础上加上了一层面向对象的语法(将复杂面向对象语法去掉了)。我们可以使用OC开发MacOSX平台和IOS平台的应用程序。2
Wesley13
•
4年前
mysql数据库优化课程
mysql数据库优化课程9、php用什么写的一、总结一句话总结:php是用c语言写的,所以php里面的那些模块什么都是c语言c语言:php是用c语言写的,所以php里面的那些模块什么都是c语言2、google搜索和百度搜索的区别是什么?
Stella981
•
4年前
NET Core Web API下事件驱动型架构CQRS架构中聚合与聚合根的实现
NETCoreWebAPI下事件驱动型架构在前面两篇文章中,我详细介绍了基本事件系统的实现,包括事件派发和订阅、通过事件处理器执行上下文来解决对象生命周期问题,以及一个基于RabbitMQ的事件总线的实现。接下来对于事件驱动型架构的讨论,就需要结合一个实际的架构案例来进行分析。在领域驱动设计的讨论范畴,CQRS架构本身就是事件驱动的,因此,我打算首先介
Wesley13
•
4年前
17 张程序员壁纸「使用频率奇高」
点击关注上方“C语言入门到精通”,获取100道C语言案例
个推技术实践
•
3年前
如何使Codis存储成本降低90%?个推:去吧,Pika!
作为一家数据智能公司,个推不仅拥有海量的关系型数据,也积累了丰富的keyvalue等非关系型数据资源。个推采用Codis保存大规模的keyvalue数据,随着公司kv类型数据的不断增加,使用原生的Codis搭建的集群所花费的成本越来越高。在一些对性能响应要求不高的场景中,个推计划采用新的存储和管理方案以有效兼顾成本与性能。经过选型,个推引入了360开源的存储
此账号已注销
•
3年前
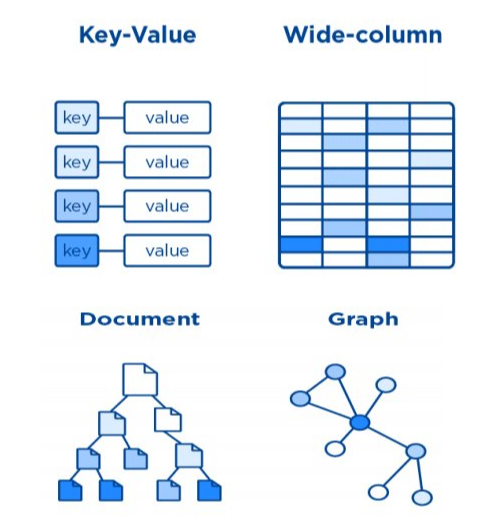
云原生多模型 NoSQL 概述
作者朱建平,TEG/云架构平台部/块与表格存储中心副总监。08年加入腾讯后,承担过对象存储、键值存储,先后负责过KV存储TSSD、对象存储TFS等多个存储平台。NoSQL技术和行业背景NoSQL是对不同于传统关系型数据库的一个统称,提出NoSQL的初衷是针对某些场景简化关系型数据库的设计,更容易水平扩展存储和计算,更侧重于实现高并发、高可用和高伸缩
1
•••
44
45
46
•••
313