推荐
专栏
教程
课程
飞鹅
本次共找到679条
聚簇索引
相关的信息
添砖java的啾
•
4年前
distinct效率更高还是group by效率更高?
目录00结论01distinct的使用02groupby的使用03distinct和groupby原理04推荐groupby的原因00结论先说大致的结论(完整结论在文末):在语义相同,有索引的情况下groupby和distinct都能使用索引,效率相同。在语义相同,无索引的情况下:distinct效率高于groupby。原因是di
Stella981
•
4年前
MyBatis官方文档索引
mybatis的官方文档写得挺详细的,确很难找到入口,整理了一下;mybatis官网文档(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fwww.mybatis.org%2Fmybatis3%2F)|mybatis中文文档(https://www.oschina.ne
Easter79
•
4年前
Springboot整合elasticsearch以及接口开发
Springboot整合elasticsearch以及接口开发搭建elasticsearch集群搭建过程略(我这里用的是elasticsearch5.5.2版本)写入测试数据新建索引book(非结构化索引)PUThttp://192.168.100.102:9200/book
Stella981
•
4年前
Pandas笔记:设置索引
importpandasaspddfpd.DataFrame({"month":1,4,7,10,"year":2012,2014,2013,2014,"sale":55,40,84,31
Wesley13
•
4年前
Java搜索使用引擎
1、Java全文搜索引擎框架Lucene毫无疑问,Lucene是目前最受欢迎的Java全文搜索框架,准确地说,它是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene为开发人员提供了相当完整的工具包,可以非常方便地实现强大的全文检索功能。下面有几款搜索引擎框架也是基于Lucene实现的。官方网站:http:
Stella981
•
4年前
Elasticsearch索引监控之Indices Segments API与Indices Shard Stores
本文将继续介绍elasticsearch索引监控之Indicessegments与IndicesShardstoresapi。IndicesSegments提供Lucene索引(分片级别)使用的segments(段信息)。其对应的示例代码如下:1public static final void test_Indic
Stella981
•
4年前
Impala常用函数索引
增加X自然天selectdays_add(now(),2)字符串转Timestampselectto\_timestamp('2019101420:00:01','yyyyMMddHH:mm:ss');注意,Impala的timestamp的标准是ISO8601 参考:https://en.wiki
Wesley13
•
4年前
sql 优化建议
1、查询语句,尽量避免查询全部,避免写select\fromtable,查哪个写哪个,提高效率; 更新语句,能update具体字段的,不要update所有字段,提升效率。 要尽量避免全表扫描,首先应考虑在where及orderby涉及的列上建立索引 2、一张表中添加索引太少不行,索引的添加可以让查询
3A网络
•
3年前
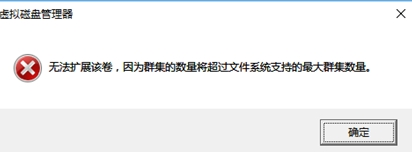
查看Windows磁盘分区块大小的若干种办法
查看Windows磁盘分区块大小的若干种办法背景:在3A云服务器上扩容磁盘,随着业务增加不断扩容磁盘,后来发现扩容超过16T就报错,报的错莫名其妙。我在想,我是单机,不是群集啊,咋回事?我切换到英文界面看到原话,原来微软中文版是把clusters当"群集"翻译了,实际上clusters还有"簇"的意思,在磁盘方面,clustersize其实就是units
京东云开发者
•
2年前
ElasticSearch集群灾难:别放弃,也许能再抢救一下 | 京东云技术团队
1前言Elasticsearch作为一个分布式搜索引擎,自身是高可用的;但也架不住一些特殊情况的发生,如:集群超过半数的master节点丢失,ES的节点无法形成一个集群,进而导致集群不可用;索引shard的文件损坏,分片无法被正常恢复,进而导致索引无法正常
1
•••
17
18
19
•••
68