推荐
专栏
教程
课程
飞鹅
本次共找到1429条
网站备案
相关的信息
冴羽
•
3年前
VuePress 博客之 SEO 优化(六)站长工具
前言在中,我们使用VuePress搭建了一个博客,最终的效果查看:。本篇接着讲讲SEO优化会用到的站长平台和工具等。1.百度统计地址:网站流量分析工具,能够告诉用户访客是如何找到并浏览用户的网站,在网站上做了些什么2.百度搜索资源平台地址:在添加站点后,可以看到自己站点在百度搜索结果中的一些表现:百度搜索中心也提供了一些教程如:1.《平
Jacquelyn38
•
4年前
基于TypeScript从0到1搭建一款爬虫工具
前言今天,我们将使用TS这门语言搭建一款爬虫工具。目标网址是什么呢?我们去上网一搜,经过几番排查之后,我们选定了这一个网站。https://www.hanju.run/一个视频网站,我们的目的主要是爬取这个网站上视频的播放链接。下面,我们就开始进行第一步。第一步俗话说,万事开头难。不过对于这个项目而言,恰恰相反。你需要做以下几个事情:1.我们需要创建
把帆帆喂饱
•
4年前
爬虫
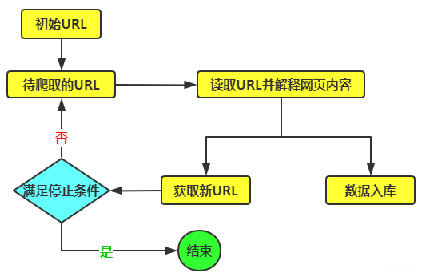
爬虫什么是爬虫使用编程语言所编写的一个用于爬取web或app数据的应用程序怎么爬取数据1.找到要爬取的目标网站、发起请求2.分析URL是如何变化的和提取有用的URL3.提取有用的数据爬虫数据能随便爬取吗?遵守robots.txt协议爬虫的分类通用网络爬虫百度,Google等搜索引擎,从一些初识的URL扩展到整个网站,主要为门户站点搜索引擎和大型网站服务采
Stella981
•
4年前
Selenium使用代理出现弹窗验证如何处理
部分商业网站对爬虫程序限制较多,在数据采集的过程中对爬虫请求进行了多种验证,导致爬虫程序需要深入分析目标网站的反爬策略,定期更新和维护爬虫程序,增加了研发的时间和投入成本。这种情况下,使用无头浏览器例如Selenium,模拟用户的请求进行数据采集是更加方便快捷的方式。同时为了避免目标网站出现IP限制,配合爬虫代理,实现每次请求自动切换IP,能够保证长期稳定
sum墨
•
1年前
《花100块做个摸鱼小网站! · 序》灵感来源
大家好呀,我是summo,这次来写写我在上班空闲(摸鱼)的时候做的一个小网站的事。去年阿里云不是推出了个活动嘛,2核2G的云服务器一年只要99块钱,懂行的人应该知道这个价格在业界已经是非常良心了,虽然优惠只有一年,但是买一台用来学习还是非常合适的。
小白学大数据
•
10个月前
Python 实现如何电商网站滚动翻页爬取
一、电商网站滚动翻页机制分析电商网站如亚马逊和淘宝为了提升用户体验,通常采用滚动翻页加载数据的方式。当用户滚动页面到底部时,会触发新的数据加载,而不是一次性将所有数据展示在页面上。这种机制虽然对用户友好,但对爬虫来说却增加了爬取难度。以淘宝为例,其商品列表
WeiSha100
•
3年前
开源职业技能学习培训网站源码搭建
源码,可用于搭建线上学习网站,提供前后台源码,开发文档,数据字典,源码开放,用户可以在原产品的基础上进行深入的二次开发。多个终端,私有化部署,功能有点播,直播,题库,考试,学情监督等!1、点播视频:在线点播视频,可上传图文资料,习题,课件等2、在线直播:对接七牛云端口,弹性带宽,直播可转存为点播课程3、题库:可批量管理上传的题库,随时随地刷题4、考试功能:
小万哥
•
2年前
一些对程序员有用的网站
宙哈哈
•
2年前
文字点选行为验证插件助您的网站更安全
随着互联网的快速发展,网络安全问题也日益突出。为了防止恶意机器人或自动程序的攻击,越来越多的网站采用了文字点选验证码作为一种有效的安全验证手段。
1
•••
25
26
27
•••
143