推荐
专栏
教程
课程
飞鹅
本次共找到3743条
网站分析
相关的信息
冴羽
•
3年前
VuePress 博客之 SEO 优化(六)站长工具
前言在中,我们使用VuePress搭建了一个博客,最终的效果查看:。本篇接着讲讲SEO优化会用到的站长平台和工具等。1.百度统计地址:网站流量分析工具,能够告诉用户访客是如何找到并浏览用户的网站,在网站上做了些什么2.百度搜索资源平台地址:在添加站点后,可以看到自己站点在百度搜索结果中的一些表现:百度搜索中心也提供了一些教程如:1.《平
Wesley13
•
4年前
Volley解析之表单提交篇
要实现表单的提交,就要知道表单提交的数据格式是怎么样,这里我从某知名网站抓了一条数据,先来分析别人提交表单的数据格式。 数据包:Connection:keepaliveContentLength:123XRequestedWith:ShockwaveFlash/16.0.0.296UserAge
把帆帆喂饱
•
4年前
爬虫
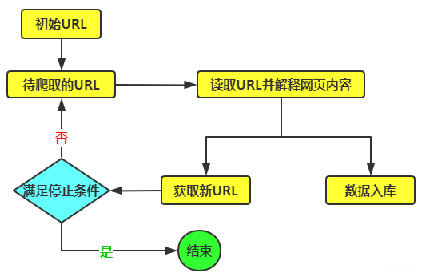
爬虫什么是爬虫使用编程语言所编写的一个用于爬取web或app数据的应用程序怎么爬取数据1.找到要爬取的目标网站、发起请求2.分析URL是如何变化的和提取有用的URL3.提取有用的数据爬虫数据能随便爬取吗?遵守robots.txt协议爬虫的分类通用网络爬虫百度,Google等搜索引擎,从一些初识的URL扩展到整个网站,主要为门户站点搜索引擎和大型网站服务采
Stella981
•
4年前
Scrapy使用入门及爬虫代理配置
本文通过一个简单的项目实现Scrapy采集流程。希望通过该项目对Scrapy的使用方法和框架能够有帮助。1\.工作流程重点流程如下:创建一个Scrapy项目。创建一个爬虫来抓取网站和处理数据。通过命令行将采集的内容进行分析。将分析的数据保存到MongoDB数据库。2\.准备环境安装
Wesley13
•
4年前
OSCHINA博文抄袭检查
rank(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fgithub.com%2Fysc%2Frank)是一个seo工具,用于分析网站的搜索引擎收录排名。比如我写了一篇文章:“使用Java8实现自己的个性化搜索引擎”,我想知道有哪些网站转载了我的文章,我该怎么办呢?请看
Stella981
•
4年前
Selenium使用代理出现弹窗验证如何处理
部分商业网站对爬虫程序限制较多,在数据采集的过程中对爬虫请求进行了多种验证,导致爬虫程序需要深入分析目标网站的反爬策略,定期更新和维护爬虫程序,增加了研发的时间和投入成本。这种情况下,使用无头浏览器例如Selenium,模拟用户的请求进行数据采集是更加方便快捷的方式。同时为了避免目标网站出现IP限制,配合爬虫代理,实现每次请求自动切换IP,能够保证长期稳定
Wesley13
•
4年前
CSS 埋点统计
CSS埋点统计当一个网站或者App的规模达到一定程度,需要分析用户在App或者网站的相应操作,则需要埋点统计用户行为,这个不用多说,具体实现有JS脚本写好埋点事件并调接口,今天get到一种新的埋点统计方式保证耳目一新。下面代码简单示范一下。//index.html<!DOCTYPE
小白学大数据
•
3年前
网站反爬之封IP应对措施
作为爬虫工作者爬取数据是基本的技能,在日常获取数据的过程中遇到网站反爬也是家常事,网站的反爬方式有很多,今天我们重点来分析下封IP的行为。这种情况下大家都是很简单的使用代理IP就解决了,但是网上ip代理有很多家,到底选哪家好呢?这里推荐口碑很好的亿牛云
小白学大数据
•
10个月前
Python 实现如何电商网站滚动翻页爬取
一、电商网站滚动翻页机制分析电商网站如亚马逊和淘宝为了提升用户体验,通常采用滚动翻页加载数据的方式。当用户滚动页面到底部时,会触发新的数据加载,而不是一次性将所有数据展示在页面上。这种机制虽然对用户友好,但对爬虫来说却增加了爬取难度。以淘宝为例,其商品列表
Immerse
•
6个月前
每日分享
每日分享✨独立开发者工具:OpenLinkProfiler是一款免费的反向链接分析工具,用于深入了解网站的反向链接概况,帮助用户制定有效的SEO策略。👇点击直达:https://www.indietools.work/product/e0adbce83f
1
•••
3
4
5
•••
375