推荐
专栏
教程
课程
飞鹅
本次共找到1824条
统计模型
相关的信息
Wesley13
•
4年前
RBAC 权限模型
RBAC0模型最基本的!(https://oscimg.oschina.net/oscnet/80a47f70d0c945ab47cadc28f63f77ab39d.png)MySQL脚本,没有建立外键约束。!(https://oscimg.oschina.net/oscnet/407d0ad45bb6f39
Stella981
•
4年前
Hadoop综合大作业
一、用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。1.启动hadoop!(https://oscimg.oschina.net/oscnet/e6b2225f65c582affaeaf71dd10f801fb98.bmp)2.Hdfs上创建文件夹并查看 !(https://oscimg.oschi
Stella981
•
4年前
Jieba分词Python简单实现
上一章分享了IKAnalyzer中文分词及词频统计基于Hadoop的MapReducer框架Java实现。这次将与大家分享Jieba中文分词Python简单实现,由于Jieba分词是基于词频最大切分组合,所以不用做词频统计,可以直接得到其关键字。1、安装jieba安装方式可以查看博主的中文分词工具(http://my.oschina.net/ea
Stella981
•
4年前
Keras 时序模型
版权声明:本文为博主原创文章,未经博主允许不得转载。https://blog.csdn.net/Thinking\_boy1992/article/details/53207177本文翻译自(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fkeras.io%2Fgettingst
Wesley13
•
4年前
Spread for Windows Forms高级主题(1)
底层模型概述Spread控件提供了很多模型,这些模型提供了自定义控件的基础架构。同时,这些模型作为底层模板,派生出了更多通用的快捷对象。在不使用Spread的底层模型的情况下,你可以完成许多任务。通过使用Spread设计器或者快捷对象(如单元格、列和行)的属性,你可以在表单上实现许多改变。但是因为表单模型是所有快捷对象的基础,因此在通常
Stella981
•
4年前
Redis线程模型
Redis是单线程模型,它内部采用了文件事件处理器filtereventhandler,而这个处理器是单线程的。文件事件处理器包含:多个socket、IO多路复用程序、事件分派器、事件处理器(连接应答处理器、事件请求处理器、事件回复处理器)。流程:IO多路复用程序会
Wesley13
•
4年前
Java内存模型
注意区分java内存模型(JMM)和java内存结构或者叫内存布局的区别。JMM决定一个线程对共享变量的写入时,能对一个线程可见。内存结构见:https://my.oschina.net/uwith/blog/3110227(https://my.oschina.net/uwith/blog/3110227)为什么有线程安全问题?:当多个线程同时共
Wesley13
•
4年前
IO模型详解
IO编程包括:文件读写操作StringIO和BytesIO内存中操作文件和目录OS序列化jsonpickling操作系统内核空间(缓冲区)收发数据:内核态(内核空间)》用户态用户空
绣鸾
•
2年前
IBM SPSS Statistics 27 Mac(统计分析软件)
是一款由IBM公司精心打造的专业统计分析软件,它能够提供统计分析、数据挖掘、预测建模产品及解决方案。主要被用于通信、医疗、银行、证券、保险、制造业、商业、市场研究、科研教育等多个领域和行业,用于推动企业走向认知商业。软件具有多种关键功能界面,可以让使用者灵
近屿智能
•
10个月前
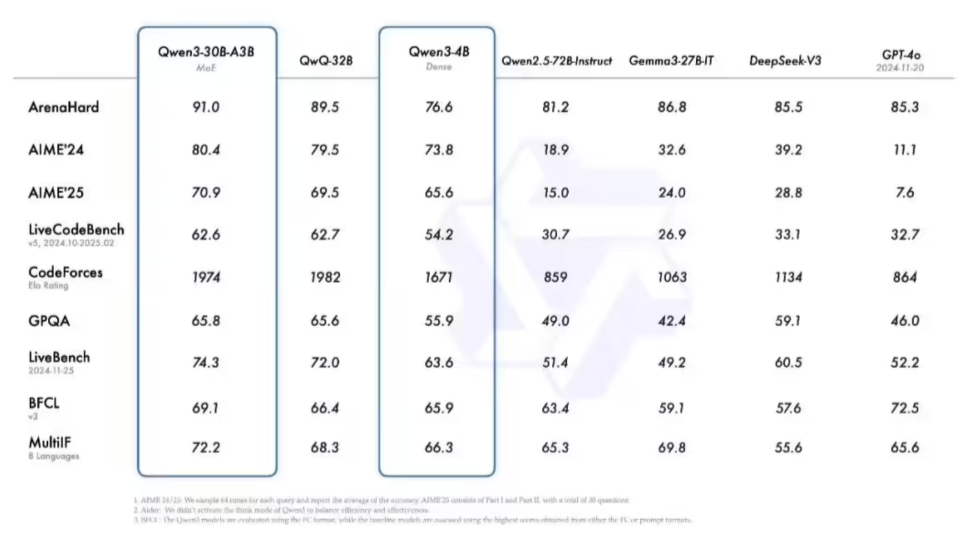
阿里发布新一代通义千问 Qwen3模型 ,近屿智能带你紧跟AI发展潮流
近日,阿里巴巴发布了新一代通义千问Qwen3模型,一举登顶全球最强开源模型。这是国内首个“混合推理模型”,将“快思考”与“慢思考”集成进同一个模型,大大节省算力消耗。旗舰模型Qwen3235BA22B在代码、数学、通用能力等基准测试中,与DeepSeekR
1
•••
11
12
13
•••
183