推荐
专栏
教程
课程
飞鹅
本次共找到542条
绝对定位
相关的信息
DevOpSec
•
4年前
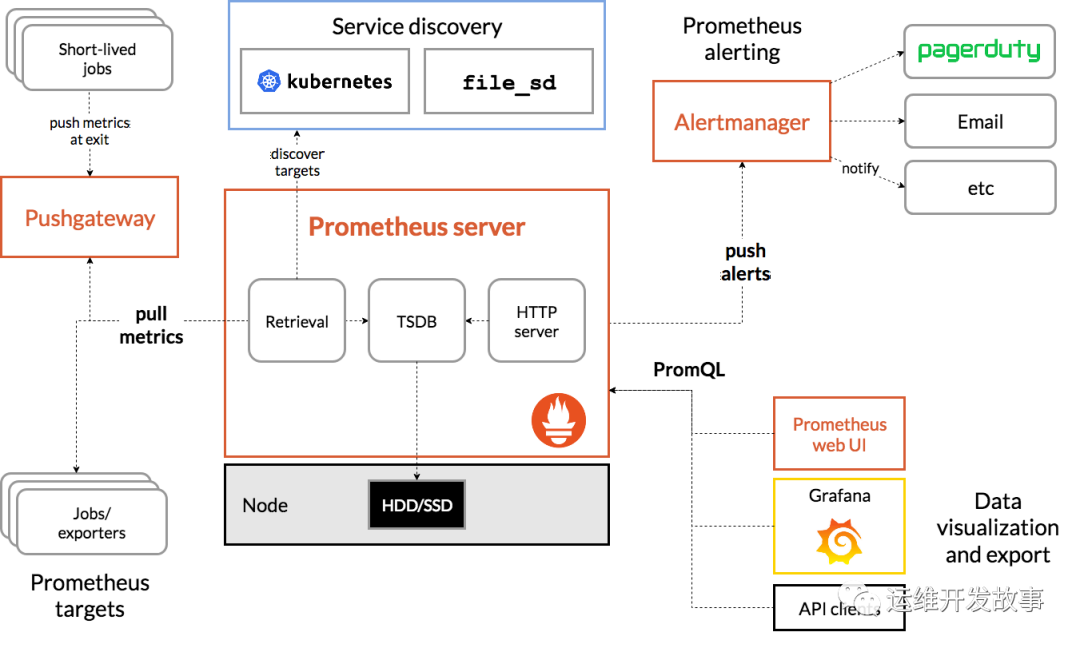
运维,关于监控的那些事,你有必要了解一下
作者|乔克来源|运维开发故事监控是整个运维以及产品整个生命周期最重要的一环,它旨在事前能够及时预警发现故障,事中能够结合监控数据定位问题,事后能够提供数据用于分析问题。一、监控的目的监控贯穿应用的整个生命周期。即从程序设计、开发、部署、下线。其主要的服务对象有:技术业务技术通过监控系统可以了解技术的环
Wesley13
•
4年前
CMDB到底如何建设?
!(https://oscimg.oschina.net/oscnet/8bf091e5bbea12b6a9b2dca3c6a37d9b0e5.gif)点击蓝字关注我们随着自动化运维的火热,CMDB建设项目不断的涌现,正是因为CMDB就是自动化运维的基石。关于CMDB的概念、定位、价值、与周边的关系、企业面临的痛点等,这里不做阐述,总结来说就是C
Wesley13
•
4年前
HTML5的一些新特性之增强型表单
众所周知,HTML5增加了一些新特性,作为一名小白,我也紧跟步伐,接下来几天将会学习HTML5的以下的一些新特性(可能会有多或少,会不定时更新和编辑):(1)增强型表单;(2)视频和音频(重点);(3)Canvas绘图技术;(4)SVG绘图技术;(5)拖放API;(6)地理定位(重点)熟练掌握; (7)WebWorker;(8)W
Wesley13
•
4年前
PHP 文件上传的原理及案例分析
原理将客户端文件上传至服务器端,在服务器端临时存储,再将服务器端临时存储的文件移至指定位置实现文件上传需要的知识点:前端页面1.form表单必须是用post发送方式,因为get会将参数带到url中,而上传的文件转换后字符会很长,而且也是为了安全性2.form表单需要使用enctype
Wesley13
•
4年前
Java8 HashMap详解
Java8HashMapJava8对HashMap进行了一些修改,最大的不同就是利用了红黑树,所以其由数组链表红黑树组成。根据Java7HashMap的介绍,我们知道,查找的时候,根据hash值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的
Stella981
•
4年前
Apache Hudi重磅RFC解读之记录级别全局索引
1\.摘要Hudi表允许多种类型操作,包括非常常用的upsert,当然为支持upsert,Hudi依赖索引机制来定位记录在哪些文件中。当前Hudi支持分区和非分区的数据集。分区数据集是将一组文件(数据)放在称为分区的桶中的数据集。一个Hudi数据集可能由N个分区和M个文件组成,这种组织结构也非常方便hive/presto/sp
Stella981
•
4年前
Ignite 与 Spark 都很强,那如果把它们整合起来会怎样?
在前面的文章(https://my.oschina.net/editorialstory/blog/2050881)中,我们分别介绍了Ignite和Spark这两种技术,从功能上对两者进行了全面深入的对比。经过分析,可以得出这样一个结论:两者都很强大,但是差别很大,定位不同,因此会有不同的适用领域。但是,这两种技术也是可以互补的,那么它们互
Wesley13
•
4年前
2020国赛数学建模B题 穿越沙漠思路
赛题总体定位:运筹规划。情景非常具体,数据需要少,需紧密结合情景具体建模,不要硬套模型。编程能力要求高一点。三问都是优化模型,注意模型之间的关联。注意点:1.对游戏规则摸清楚,不要急着建模。2.涉及到路线、事件的选择,使用01变量等定义模型。3.最短路径基本可以数出来,考察的是最优路径
Stella981
•
4年前
Python日志库logging总结
在部署项目时,不可能直接将所有的信息都输出到控制台中,我们可以将这些信息记录到日志文件中,这样不仅方便我们查看程序运行时的情况,也可以在项目出现故障时根据运行时产生的日志快速定位问题出现的位置。1、日志级别Python标准库logging用作记录日志,默认分为六种日志级别(括号为级别对应的数值),NOTSET(0)、DEBUG(10)
京东云开发者
•
2年前
糟糕,被SimpleDateFormat坑到啦!| 京东云技术团队
1\.问题背景问题的背景是这样的,在最近需求开发中遇到需要将给定目标数据通过某一固定的计量规则进行过滤并打标生成明细数据,其中发现存在一笔目标数据的时间在不符合现有日期规则的条件下,还是通过了规则引擎的匹配打标操作。故而需要对该错误匹配场景进行排查,定位其
1
•••
45
46
47
•••
55