推荐
专栏
教程
课程
飞鹅
本次共找到6380条
系统日志
相关的信息
Easter79
•
4年前
sqoop从hive导入数据到mysql时出现主键冲突
今天在将一个hive数仓表导出到mysql数据库时出现进度条一直维持在95%一段时间后提示失败的情况,搞了好久才解决。使用的环境是HUE中的Oozie的workflow任何调用sqoop命令,该死的oozie的日志和异常提示功能太辣鸡了,最后发现是重复数据导致数据进入mysql表时出现主键冲突进而导致数据同步失败。(1)众所周知hive表是没有主键与索引
Wesley13
•
4年前
java用户角色权限设计
实现业务系统中的用户权限管理B/S系统中的权限比C/S中的更显的重要,C/S系统因为具有特殊的客户端,所以访问用户的权限检测可以通过客户端实现或通过客户端服务器检测实现,而B/S中,浏览器是每一台计算机都已具备的,如果不建立一个完整的权限检测,那么一个“非法用户”很可能就能通过浏览器轻易访问到B/S系统中的所有功能。因此B/S业务系统都需要有
Wesley13
•
4年前
2020年数学建模
E题校园供水系统智能管理校园供水系统是校园公用设施的重要组成部分,学校为了保障校园供水系统的正常运行需要投入大量的人力、物力和财力。随着科学技术的发展,校园内已经普遍使用了智能水表,从而可以获得大量的实时供水系统运行数据。后勤部门希望基于这些数据,通过数学建模和数据挖掘及时发现和解决供水系统中存在的问题,提高校园服务和管理水平。附件是某
Stella981
•
4年前
Kafka 和 RocketMQ 之性能对比
在双十一过程中投入同样的硬件资源,Kafka搭建的日志集群单个Topic可以达到几百万的TPS,而使用RocketMQ组件的核心业务集群,集群TPS只能达到几十万TPS,这样的现象激发了我对两者性能方面的思考。温馨提示:TPS只是众多性能指标中的一个,我们在做技术选型方面要从多方面考虑,本文并不打算就消息中间件选型方面投入太多笔墨,重点想尝试剖析两
Python进阶者
•
4年前
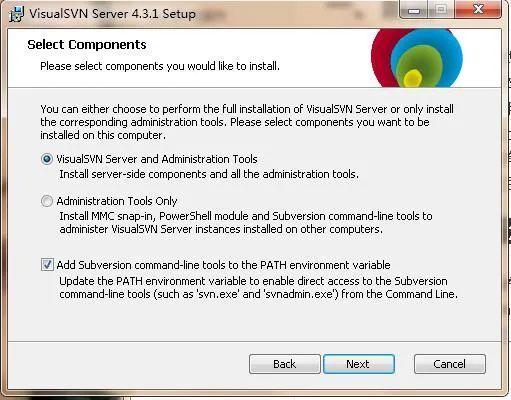
手把手教你搭建集中式版本控制系统SVN服务器
大家好,我是IT共享者,人称皮皮。一、前言我们前段日子学过了分布式版本控制系统git,相信大家都领略到了它的强大,今天我们来说说集中式版本控制系统svn,跟分布式版本控制系统不同的是,集中式版本控制系统旨在用于多个人协同开发一个项目,而且它的版本控制系统都是存放在中央服务器上的,如果你需要使用就得从中央服务器上调用,它不像git,每个用户都可以有自己的版本
Easter79
•
4年前
TarsGo新版本发布,支持protobuf,zipkin和自定义插件
Tars是腾讯从2008年到今天一直在使用的后台逻辑层的统一应用框架,目前支持C,Java,PHP,Nodejs,Golang语言。该框架为用户提供了涉及到开发、运维、以及测试的一整套解决方案,帮助一个产品或者服务快速开发、部署、测试、上线。它集可扩展协议编解码、高性能RPC通信框架、名字路由与发现、发布监控、日志统计、配置管理等于一体,通过它可以快速用
Wesley13
•
4年前
MySQL数据库CPU问题一则
作者:张政俊,中欧基金DBAMysql一般出现CPU负载过高问题的时候,我们都会去看下故障期间的慢sql日志,然后找出全表扫描、索引不合理、函数运算过多的sql,让开发同学优化下。实在不行的话,那就升级CPU硬件,替换更高频率的CPU,1路的升级成2路,2路的升级成四路。这次出现的问题因为关乎到每天的业务处理,所以很多措施无法第一时间到位,
Wesley13
•
4年前
logstash tcp multihost output(多目标主机输出,保证TCP输出链路的稳定性)
在清洗日志时,有一个应用场景,就是TCP输出时,需要在一个主机挂了的情况下,自已切换到下一个可用入口,而原tcpoutput仅支持单个目标主机设定。故本人在原tcp的基础上,开发出tcp\_multihost输出插件,来满足此场景。插件在一开始的时候会随机选择一个链路,而在链路出错连续超过3(默认)次后会尝试数组中下一个主机github:http
Easter79
•
4年前
SpringBoot2.0笔记四
当搞全局捕获异常时可以使用到AOP技术,采用异常通知,也可以用AOP搞日志记录在类上面加上@EnableAsyns注解开启异步调用@Asyns,在方法上加上此注解,可以实现异步调用,底层是多线程技术,相当于加上这个注解的方法重新开启了一个单独的线程正常情况下,当A方法调用B方法时,是需要B方法执行完成,有返回结果时等待返回。这是顺序的方式从上到下
DeepFlow开源
•
2年前
应用响应时延背后 深藏的网络时延
应用异常时,基本可以分为服务访问不通和服务响应慢两个大类。其中服务响应慢的问题定位非常棘手,很多无头案。应用团队有日志和追踪,对于自认为的不可能不合理的事情都会甩给基础设施团队,又由于基础设施团队现有的监控数据缺乏应用的观测视角,通常成为一切「不是我的问题」超自然现象的终极背锅侠,其中以网络团队尤为严重。
1
•••
133
134
135
•••
638