推荐
专栏
教程
课程
飞鹅
本次共找到235条
根文件系统
相关的信息
刘望舒
•
4年前
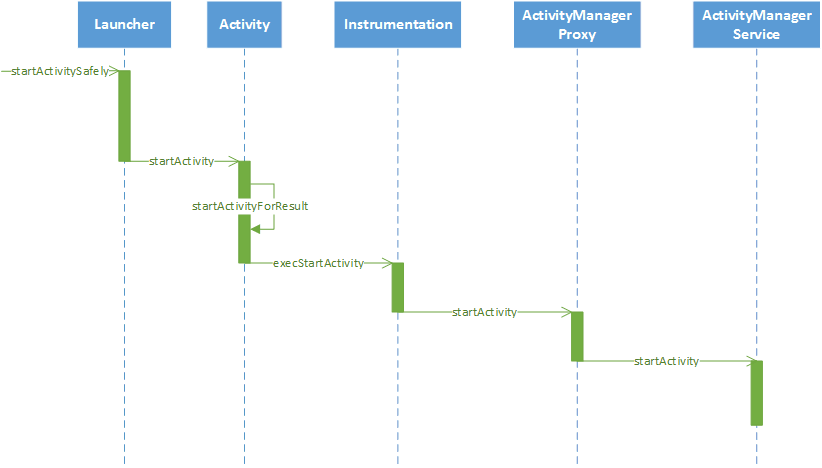
Android深入四大组件(一)应用程序启动过程(前篇)
Android框架层Android深入四大组件categories:Android框架层本文首发于微信公众号「后厂技术官」前言在此前的文章中,我讲过了Android系统启动流程和Android应用进程启动过程,这一篇顺理成章来学习Android7.0的应用程序的启动过程。分析应用程序的启动过程其实就是分析根Activity的启动过程。<!more1
Andy20
•
4年前
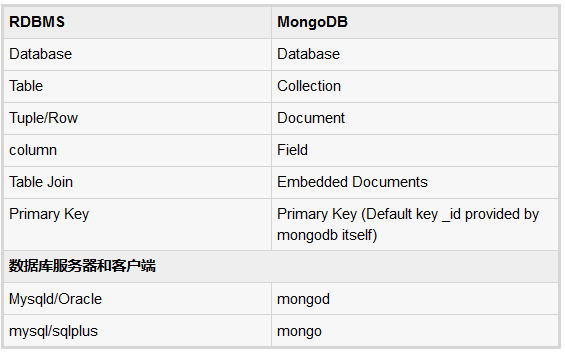
30分钟让你了解MongoDB基本操作
今天记录下MongoDB的基本操作,这只是最基本的,所以是应该掌握的。数据库数据库是一个物理容器集合。每个数据库都有自己的一套文件系统上的文件。一个单一的MongoDB服务器通常有多个数据库。集合集合是一组MongoDB的文档。它相当
Peter20
•
4年前
MYSQL里的索引类型介绍
首先要明白索引(index)是在存储引擎(storageengine)层面实现的,而不是在server层面。不是所有的存储引擎支持有的索引类型。1、BTREE最常见的索引类型,他的思想是所有的值(被索引的列)都是被排过序的,每个叶节点到根节点的距离是相等的,所以适合用来找某一范围内的数据,而且可以直接支持排序(orderby)支持innoDB和MyIS
Wesley13
•
4年前
vertica 安装日记
如果Linux系统已经安装好后,并且文件系统为Ext4格式的(centos6默认ext4,centos默认为xfs,安装系统的时候可以修改,之后不能修改所以一定要在装系统时候修改为Ext4)才能继续以下步骤。1.手动配置静态IPvi/etc/sysconfig/networkscripts/ifcfg{相应的网络设备如:ent33}(Ip
Stella981
•
4年前
Linux中selinux详解
Linux中selinux详解SELinux的基本操作SELinux是个经过安全强化的Linux操作系统,实际上,基本上原来的运用软件没有必要修改就能在它上面运行。真正做了特别修改的RPM包只要50多个。像文件系统EXT3都是经过了扩展。对于一些原有的命令也进行了扩展,另外还增加了
Wesley13
•
4年前
Java使用SSLSocket通信
JSSE(JavaSecuritySocketExtension)是Sun公司为了解决互联网信息安全传输提出的一个解决方案,它实现了SSL和TSL协议,包含了数据加密、服务器验证、消息完整性和客户端验证等技术。通过使用JSSE简洁的API,可以在客户端和服务器端之间通过SSL/TSL协议安全地传输数据。首先,需要将OpenSSL生成根证书CA及签
Stella981
•
4年前
FastCgi与PHP
首先,CGI是干嘛的?CGI是为了保证webserver传递过来的数据是标准格式的,方便CGI程序的编写者。webserver(比如说nginx)只是内容的分发者。比如,如果请求/index.html,那么webserver会去文件系统中找到这个文件,发送给浏览器,这里分发的是静态数据。好了,如果现在请求的是/index.php,根据配
Stella981
•
4年前
Linux SD卡建立两个分区
本文主要介绍Linux环境下SD卡建立两个分区的操作流程:操作环境:LinuxUbuntu2016.4操作目的:将SD卡分为两个分区:第一分区格式为FAT32,大小500M。第二个分区为ext4,占剩下的所有空间,用来装Ubuntu的文件系统具体操作如下;一.使用lsblk或者fd
贾蔷
•
8个月前
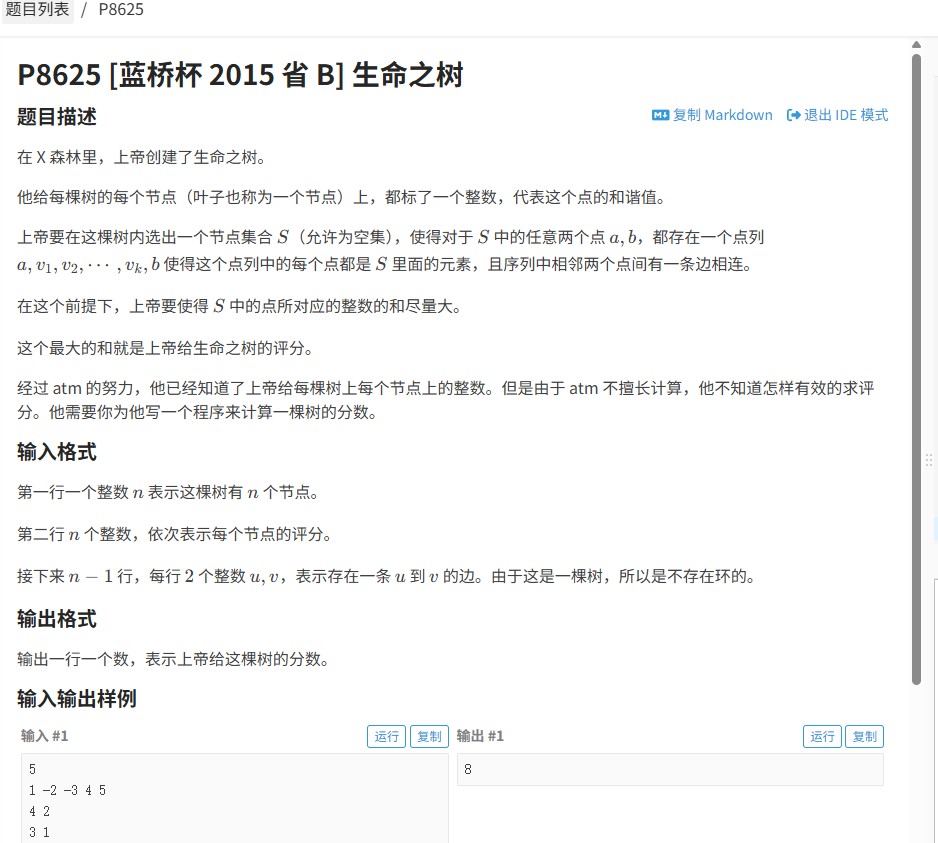
【蓝桥杯2015省赛解析】生命之树(洛谷P8625):树形DP解题全攻略
一、题目解读“生命之树”是一道经典的树形结构问题,要求计算一棵带权树中,以某个节点为根的最大子树权值和。题目输入为n个节点及边信息,每个节点有权值wi,需找到所有节点中,子树权值和最大的节点,并输出其值。核心挑战在于如何处理树形结构的递归关系,并高效聚合子
贾蔷
•
8个月前
牛客13279题解:利用递归与深度优先搜索计算树的最大高度(附完整代码)
一、题目解读牛客13279题要求计算给定树的最大高度。题目输入一棵以邻接表形式表示的树(节点从0开始编号),需要输出从根节点到最深叶节点的最长路径长度。树的结构由n个节点和n1条边构成,保证为连通无环图。理解题目核心在于准确获取树的拓扑关系,并设计算法遍历
1
•••
15
16
17
•••
24