推荐
专栏
教程
课程
飞鹅
本次共找到1855条
循环结构
相关的信息
待兔
•
4年前
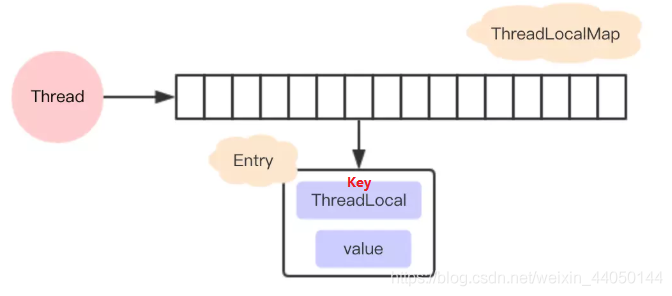
ThreadLocal源码分析
最近在学多线程并发的知识,发现好像ThreadLoca还挺重要,决定看看源码以及查找各方资料来学习一下。ThreadLocal能够提供线程的局部变量,让每个线程都可以通过set/get来对这个局部变量进行操作,不会和其它线程的局部变量进行冲突,实现了线程的数据隔离。首先是ThreadLocal的结构:每个Thread维护一个ThreadLocalMap,这个
codigger
•
6个月前
代码的“活”艺术:Object Sense 的元编程与运行时灵活性如何解锁编程新境界?
聚焦OSE在动态代码生成、反射机制及注解等元编程方面的强大能力,洞察它如何赋予开发者在运行时操作代码的超能力,开辟前所未有的开发模式与创新空间。传统编程语言仿佛被浇筑在混凝土中的建筑——编译时便固化了结构,运行时难以应对突发变化。当软件系统日益复杂,用户需
Stella981
•
4年前
Prometheus时序数据库
Prometheus时序数据库内存中的存储结构前言笔者最近担起了公司监控的重任,而当前监控最流行的数据库即是Prometheus。按照笔者打破砂锅问到底的精神,自然要把这个开源组件源码搞明白才行。在经过一系列源码/资料的阅读以及各种Debug之后,对其内部机制有了一定的认识。今天,笔者就来介绍
Easter79
•
4年前
Springmvc+mybatis+Dubbo+ZooKeeper+Redis+KafKa
开发工具1.EclipseIDE:采用Maven项目管理,模块化。2.代码生成:通过界面方式简单配置,自动生成相应代码,目前包括三种生成方式(增删改查):单表、一对多、树结构。生成后的代码如果不需要注意美观程度,生成后即可用。技术选型(只列了一部分技术)1、后端服务框架:Dubbo、zookeeper、Rest服务缓存:redis
Wesley13
•
4年前
Java多线程之线程安全队列Queue
在Java多线程应用中,队列的使用率很高,多数生产消费模型的首选数据结构就是队列。Java提供的线程安全的Queue可以分为阻塞队列和非阻塞队列,其中阻塞队列的典型例子是BlockingQueue,非阻塞队列的典型例子是ConcurrentLinkedQueue,在实际应用中要根据实际需要选用阻塞队列或者非阻塞队列。注:什么叫线程安全?这个首先要明确。
dkll
•
1个月前
打造私域流量级圈子论坛小程序上线部署:uni前端+php后端,兴趣分享经验扩谈,适用小白创业者
圈子论坛小程序是一种基于微信平台的社交应用小程序,它允许用户在小程序内创建和参与各种主题的社区,进行话题讨论、内容分享、互动评论、点赞、关注等活动。1.完整的安装代码包:本系统提供完整的安装代码包,包括小程序前端代码、后端服务代码以及数据库结构等。2.丰富
深度学习
•
8个月前
链表栈实现指南:从基础到实践
一、简介和特点链表栈是一种使用链表实现的栈数据结构,遵循后进先出(LIFO)原则。本文实现的链表栈通过动态内存分配节点,避免了数组实现的固定大小限制。主要特点:1.动态大小:无需预先分配固定空间2.高效操作:入栈和出栈都是O(1)时间复杂度3.内存效率
布局王
•
8个月前
鸿蒙Next仓颉语言开发实战教程:聊天列表
昨天分享了消息列表页面,今天继续分享聊天页面的开发过程:这个页面又是常见的上中下布局,从上至下依次为导航栏、聊天列表和输入框工具栏,我们可以先写一下简单的结构,最上面导航栏是横向布局,所以写个Row容器,中间是List,底部仍然是Row容器,导航栏和底部输
上海张律师
•
8个月前
如何实现组件截图 -- componentSnapshot
HarmonyOS应用开发在我开发手里项目的过程中,遇到这么一个功能需求:即用户在完成一系列的学习并通过考试以后,要生成一张证书,这张证书的结构是:一个背景图,上面还有文字、其他图片等,文字和图片都是根据用户信息动态生成的,整个证书在显示的时候是通过St
深度学习
•
7个月前
2013年蓝桥杯国赛C组危险系数(洛谷P8604):图论算法解密
一、问题描述地下网络由多个站点和连接通道组成。当某个站点被敌人破坏后,可能导致其他站点间失去联系。DF(x,y)定义为:使站点x和y断开连接的所有关键点z的数量。二、核心思想1.表示:使用网络结构1.连通性检查:算法1.关键点判定:逐个排除节点后检查连通性
1
•••
146
147
148
•••
186