
Prometheus时序数据库-内存中的存储结构
前言
笔者最近担起了公司监控的重任,而当前监控最流行的数据库即是Prometheus。按照笔者打破砂锅问到底的精神,自然要把这个开源组件源码搞明白才行。在经过一系列源码/资料的阅读以及各种Debug之后,对其内部机制有了一定的认识。今天,笔者就来介绍下Prometheus的存储结构。
由于篇幅较长,所以笔者分为两篇,本篇主要是描述Prometheus监控数据在内存中的存储结构。下一篇,主要描述的是监控数据在磁盘中的存储结构。
Gorilla
Prometheus的存储结构-TSDB是参考了Facebook的Gorilla之后,自行实现的。所以阅读 这篇文章《Gorilla: A Fast, Scalable, In-Memory Time Series Database》 ,可以对Prometheus为何采用这样的存储结构有着清晰的理解。
监控数据点
下面是一个非常典型的监控曲线。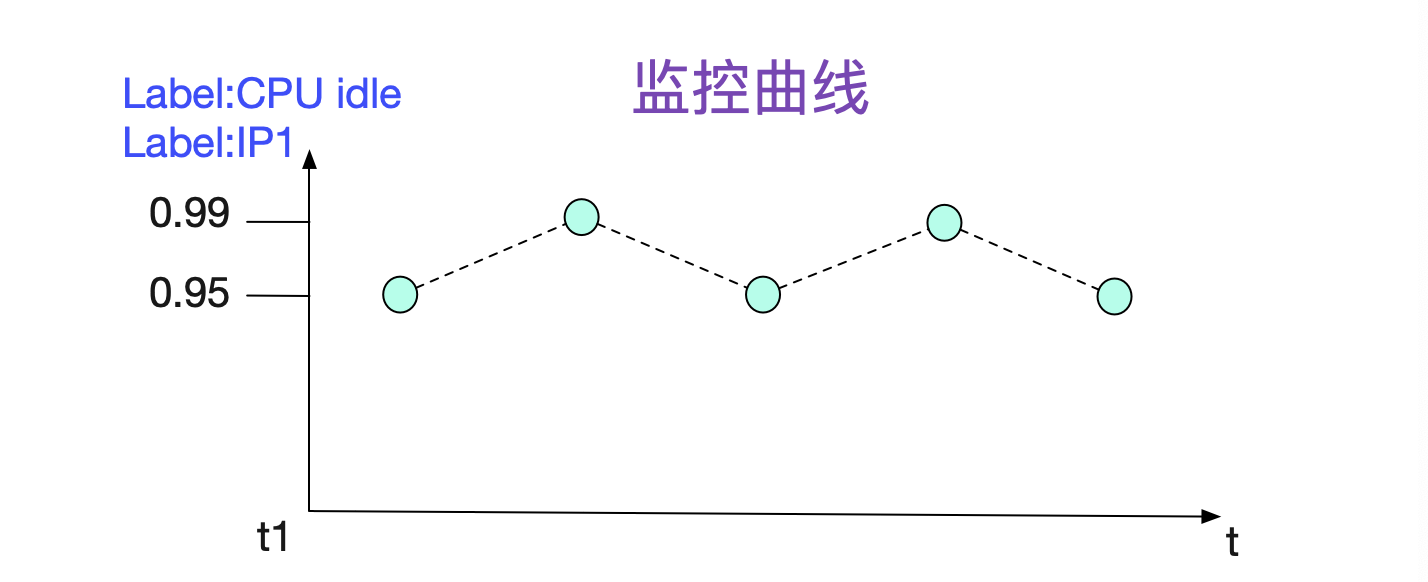
可以观察到,监控数据都是由一个一个数据点组成,所以可以用下面的结构来保存最基本的存储单元
type sample struct {
t int64
v float64
}
同时我们还需要注意到的信息是,我们需要知道这些点属于什么机器的哪种监控。这种信息在Promtheus中就用Label(标签来表示)。一个监控项一般会有多个Label(例如图中),所以一般用labels []Label。
由于在我们的习惯中,并不关心单独的点,而是要关心这段时间内的曲线情况。所以自然而然的,我们存储结构肯定逻辑上是这个样子: 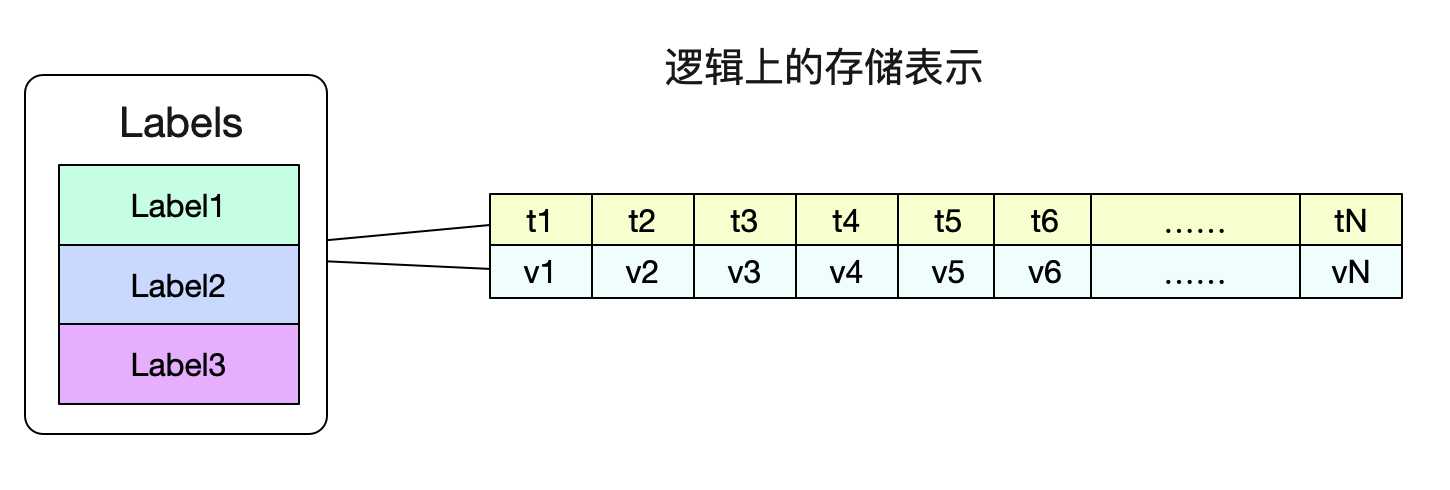
这样,我们就可以很容易的通过一个Labels(标签们)找到对应的数据了。
监控数据在内存中的表示形式
最近的数据保存在内存中
Prometheus将最近的数据保存在内存中,这样查询最近的数据会变得非常快,然后通过一个compactor定时将数据打包到磁盘。数据在内存中最少保留2个小时(storage.tsdb.min-block-duration。至于为什么设置2小时这个值,应该是Gorilla那篇论文中观察得出的结论 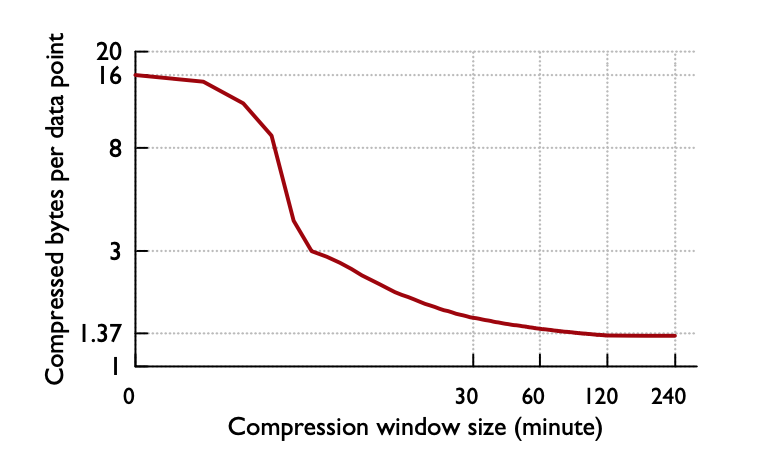
即压缩率在2小时时候达到最高,如果保留的时间更短,就无法最大化的压缩。
内存序列(memSeries)
接下来,我们看下具体的数据结构
type memSeries stuct {
......
ref uint64 // 其id
lst labels.Labels // 对应的标签集合
chunks []*memChunk // 数据集合
headChunk *memChunk // 正在被写入的chunk
......
}
其中memChunk是真正保存数据的内存块,将在后面讲到。我们先来观察下memSeries在内存中的组织。 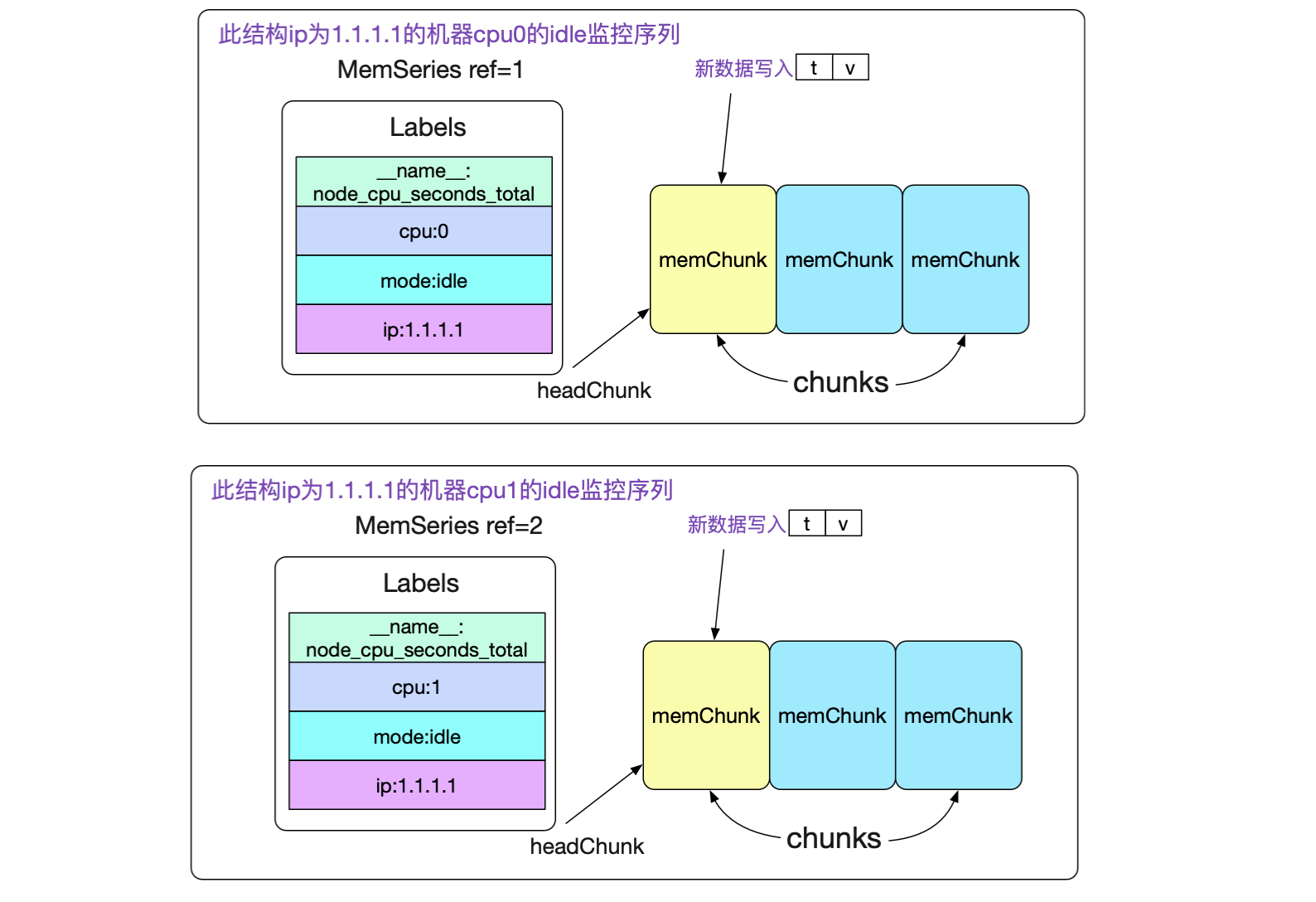
由此我们可以看到,针对一个最终端的监控项(包含抓取的所有标签,以及新添加的标签,例如ip),我们都在内存有一个memSeries结构。
寻址memSeries
如果通过一堆标签快速找到对应的memSeries。自然的,Prometheus就采用了hash。主要结构体为:
type stripeSeries struct {
series [stripeSize]map[uint64]*memSeries // 记录refId到memSeries的映射
hashes [stripeSize]seriesHashmap // 记录hash值到memSeries,hash冲突采用拉链法
locks [stripeSize]stripeLock // 分段锁
}
type seriesHashmap map[uint64][]*memSeries
由于在Prometheus中会频繁的对map[hash/refId]memSeries进行操作,例如检查这个labelSet对应的memSeries是否存在,不存在则创建等。由于golang的map非线程安全,所以其采用了分段锁去拆分锁。 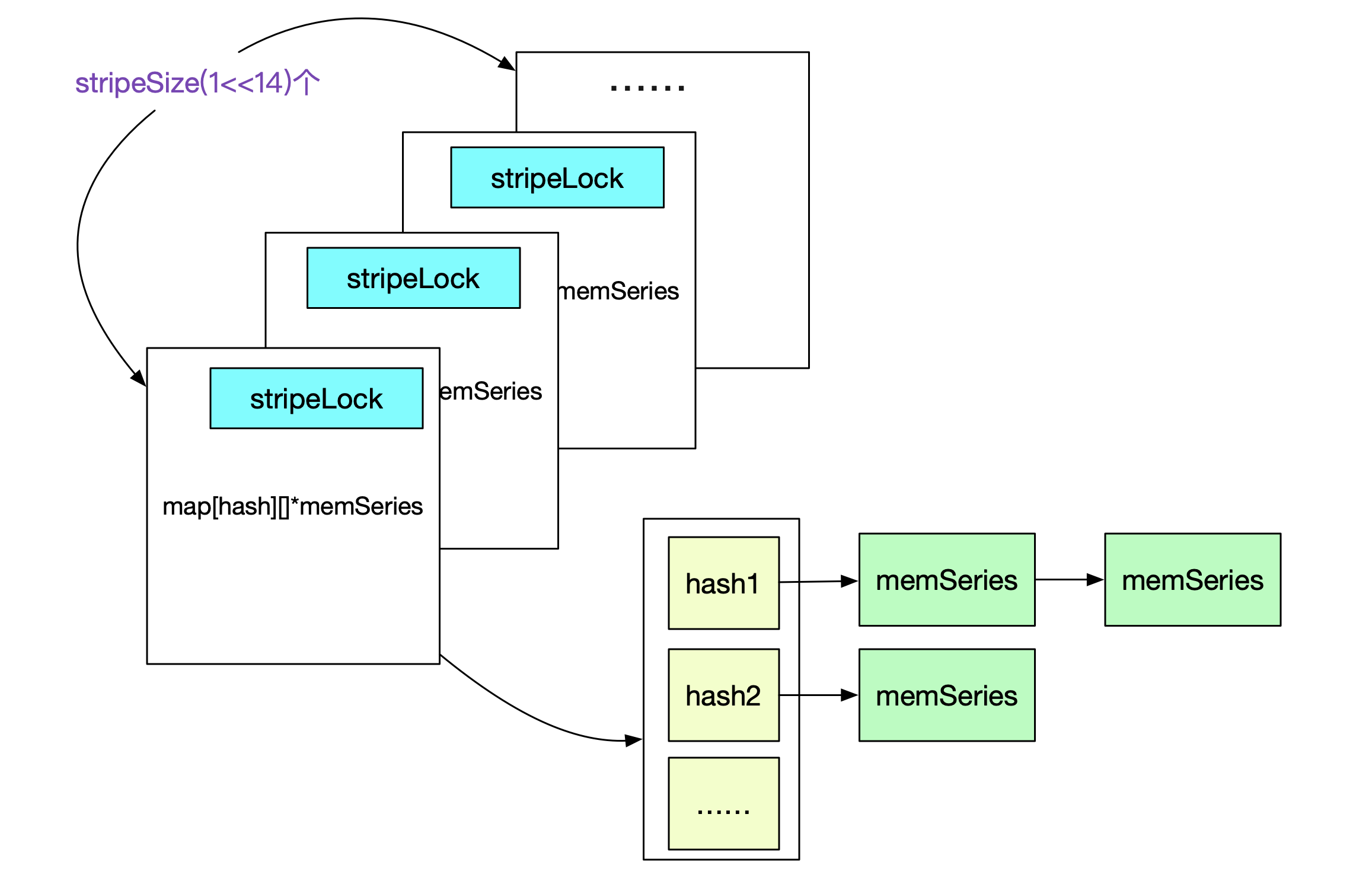
而hash值是依据labelSets的值而算出来。
数据点的存储
为了让Prometheus在内存和磁盘中保存更大的数据量,势必需要进行压缩。而memChunk在内存中保存的正是采用XOR算法压缩过的数据。在这里,笔者只给出Gorilla论文中的XOR描述 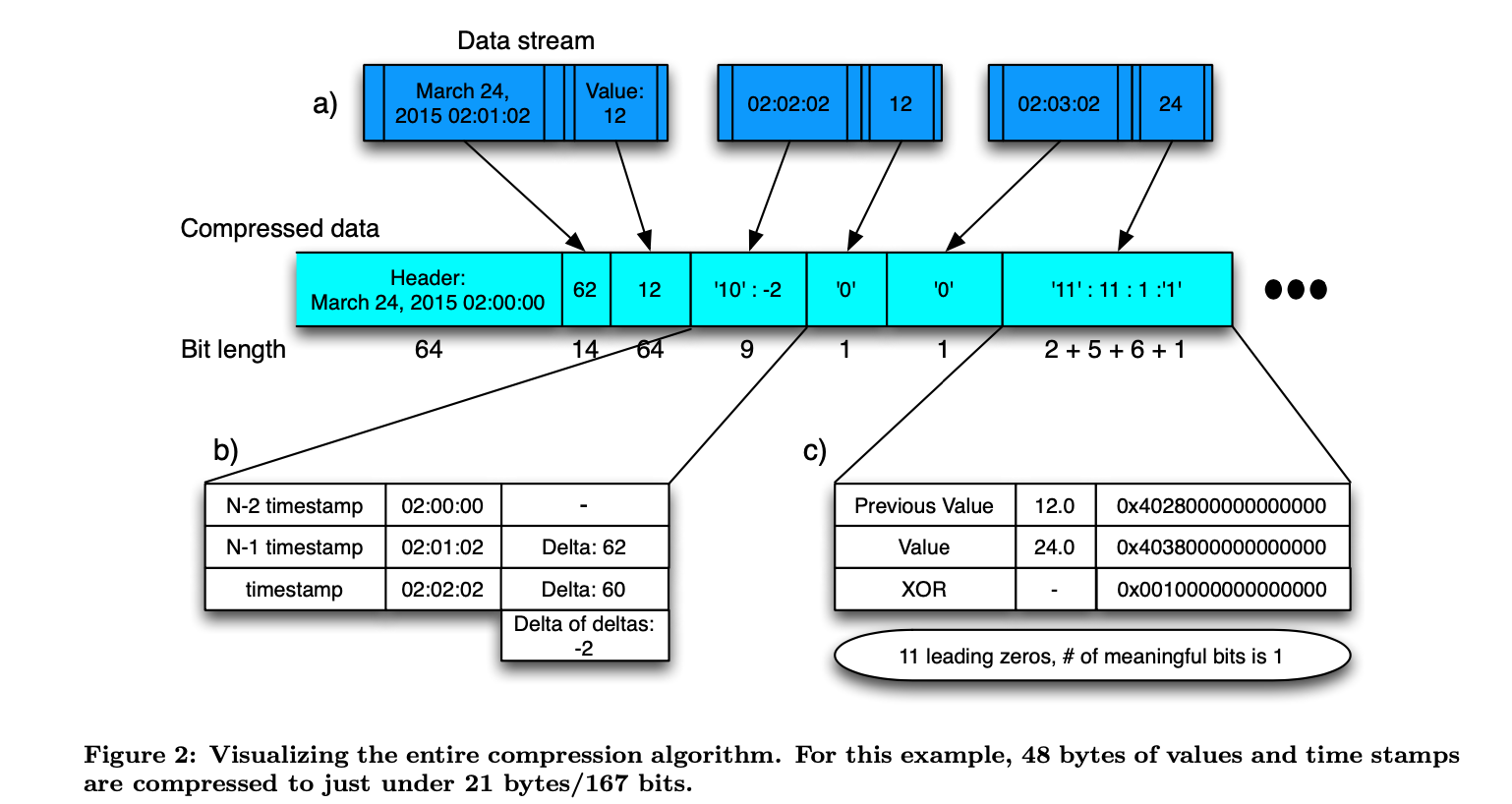
更具体的算法在论文中有详细描述。总之,使用了XOR算法后,平均每个数据点能从16bytes压缩到1.37bytes,也就是说所用空间直接降为原来的1/12!
内存中的倒排索引
上面讨论的是标签全部给出的查询情况。那么我们怎么快速找到某个或某几个标签(非全部标签)的数据呢。这就需要引入以Label为key的倒排索引。我们先给出一组标签集合
{__name__:http_requests}{group:canary}{instance:0}{job:api-server}
{__name__:http_requests}{group:canary}{instance:1}{job:api-server}
{__name__:http_requests}{group:production}{instance:1}{job,api-server}
{__name__:http_requests}{group:production}{instance:0}{job,api-server}
可以看到,由于标签取值不同,我们会有四种不同的memSeries。如果一次性给定4个标签,应该是很容易从map中直接获取出对应的memSeries(尽管Prometheus并没有这么做)。但大部分我们的promql只是给定了部分标签,如何快速的查找符合标签的数据呢?
这就引入倒排索引。 先看一下,上面例子中的memSeries在内存中会有4种,同时内存中还夹杂着其它监控项的series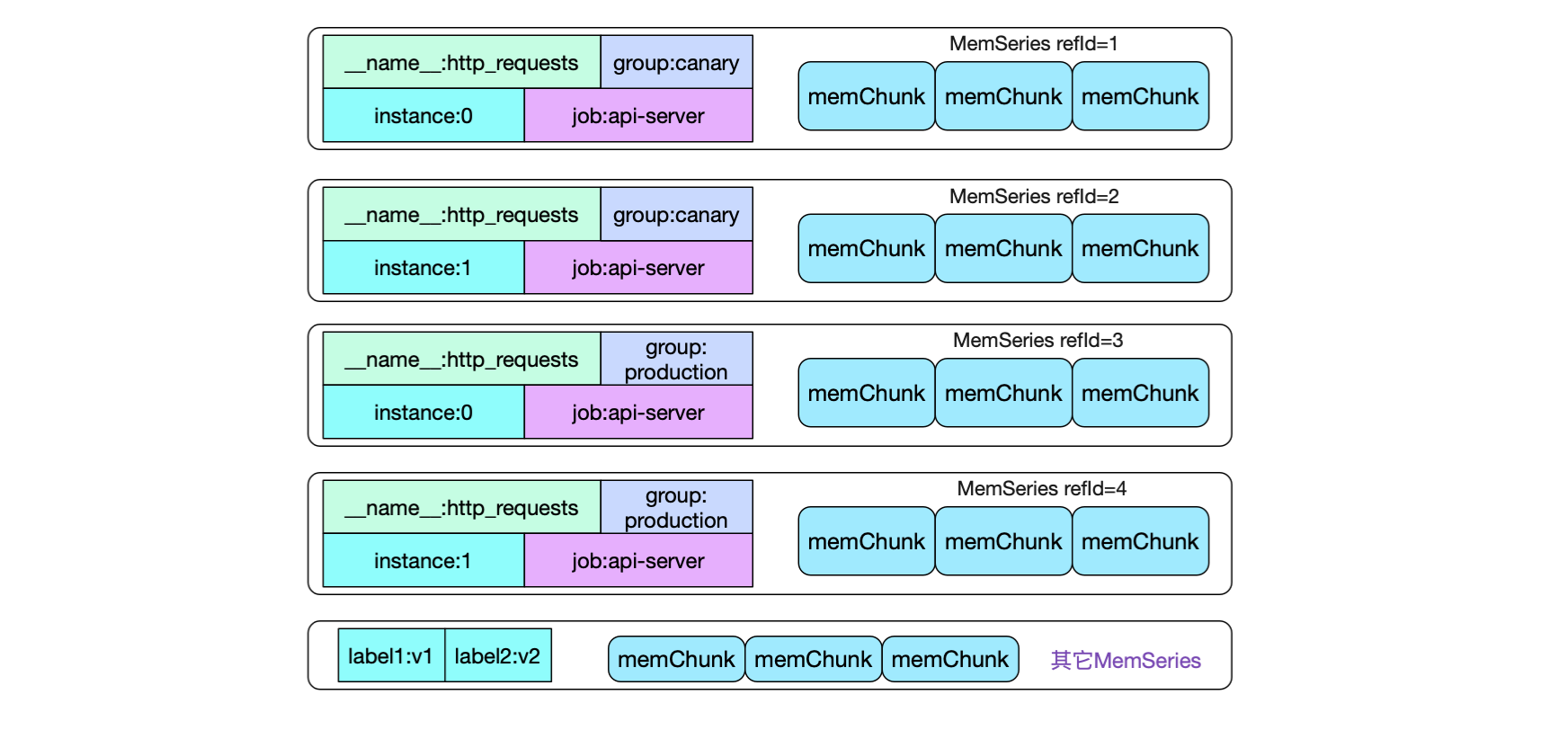
如果我们想知道job:api-server,group为production在一段时间内所有的http请求数量,那么必须获取标签携带 ({__name__:http_requests}{job:api-server}{group:production})的所有监控数据。
如果没有倒排索引,那么我们必须遍历内存中所有的memSeries(数万乃至数十万),一一按照Labels去比对,这显然在性能上是不可接受的。而有了倒排索引,我们就可以通过求交集的手段迅速的获取需要哪些memSeries。 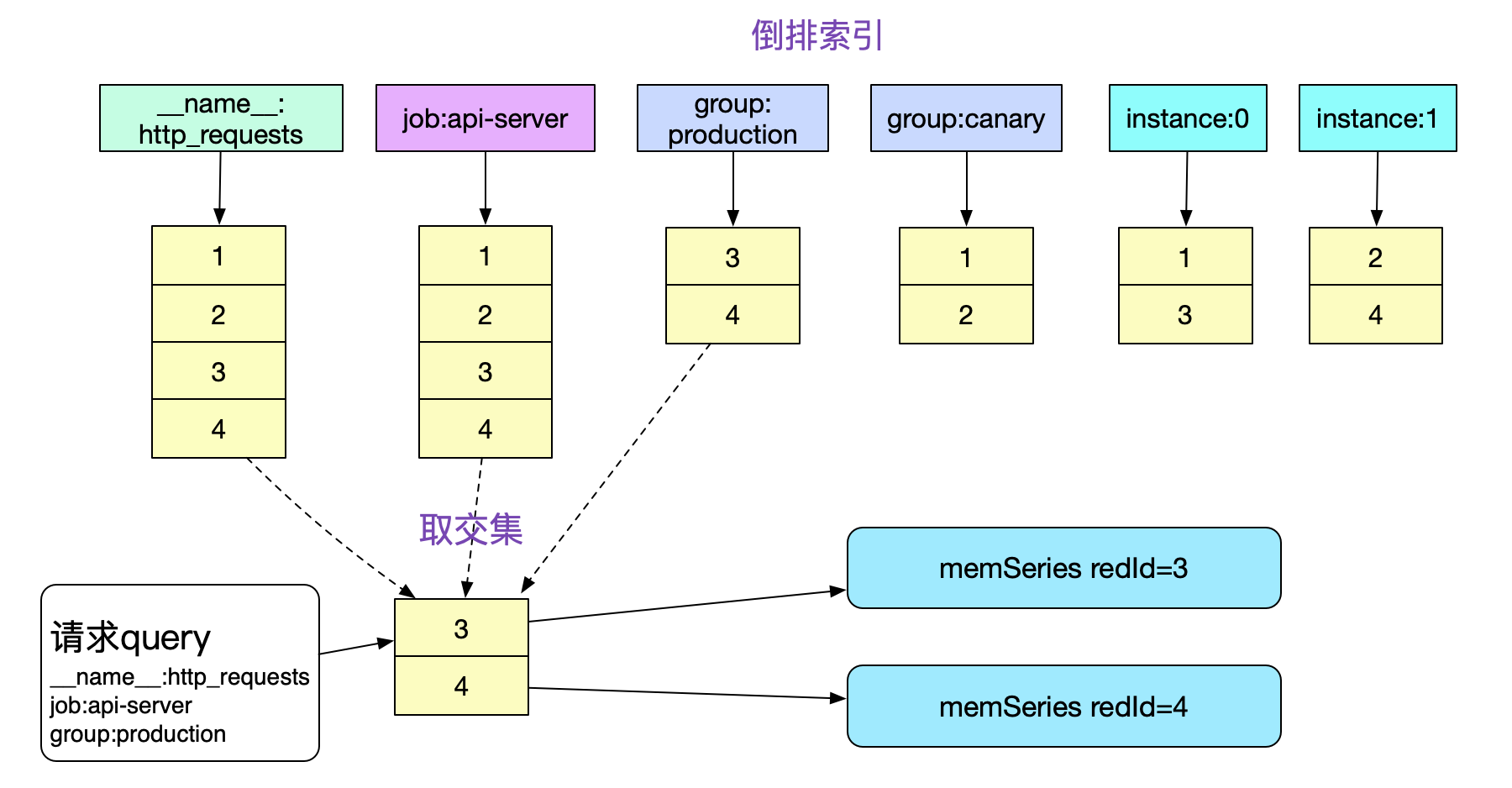
注意,这边倒排索引存储的refId必须是有序的。这样,我们就可以在O(n)复杂度下顺利的算出交集,另外,针对其它请求形式,还有并集/差集的操作,对应实现结构体为:
type intersectPostings struct {...} // 交集
type mergedPostings struct {...} // 并集
type removedPostings struct {...} // 差集
倒排索引的插入组织即为Prometheus下面的代码
Add(labels,t,v)
|->getOrCreateWithID
|->memPostings.Add
// Add a label set to the postings index.
func (p *MemPostings) Add(id uint64, lset labels.Labels) {
p.mtx.Lock()
// 将新创建的memSeries refId都加到对应的Label倒排里去
for _, l := range lset {
p.addFor(id, l)
}
p.addFor(id, allPostingsKey) // allPostingKey "","" every one都加进去
p.mtx.Unlock()
}
正则支持
事实上,给定特定的Label:Value还是无法满足我们的需求。我们还需要对标签正则化,例如取出所有ip为1.1.*前缀的http_requests监控数据。为了这种正则,Prometheus还维护了一个标签所有可能的取值。对应代码为:
Add(labels,t,v)
|->getOrCreateWithID
|->memPostings.Add
func (h *Head) getOrCreateWithID(id, hash uint64, lset labels.Labels){
...
for _, l := range lset {
valset, ok := h.values[l.Name]
if !ok {
valset = stringset{}
h.values[l.Name] = valset
}
// 将可能取值塞入stringset中
valset.set(l.Value)
// 符号表的维护
h.symbols[l.Name] = struct{}{}
h.symbols[l.Value] = struct{}{}
}
...
}
那么,在内存中,我们就有了如下的表 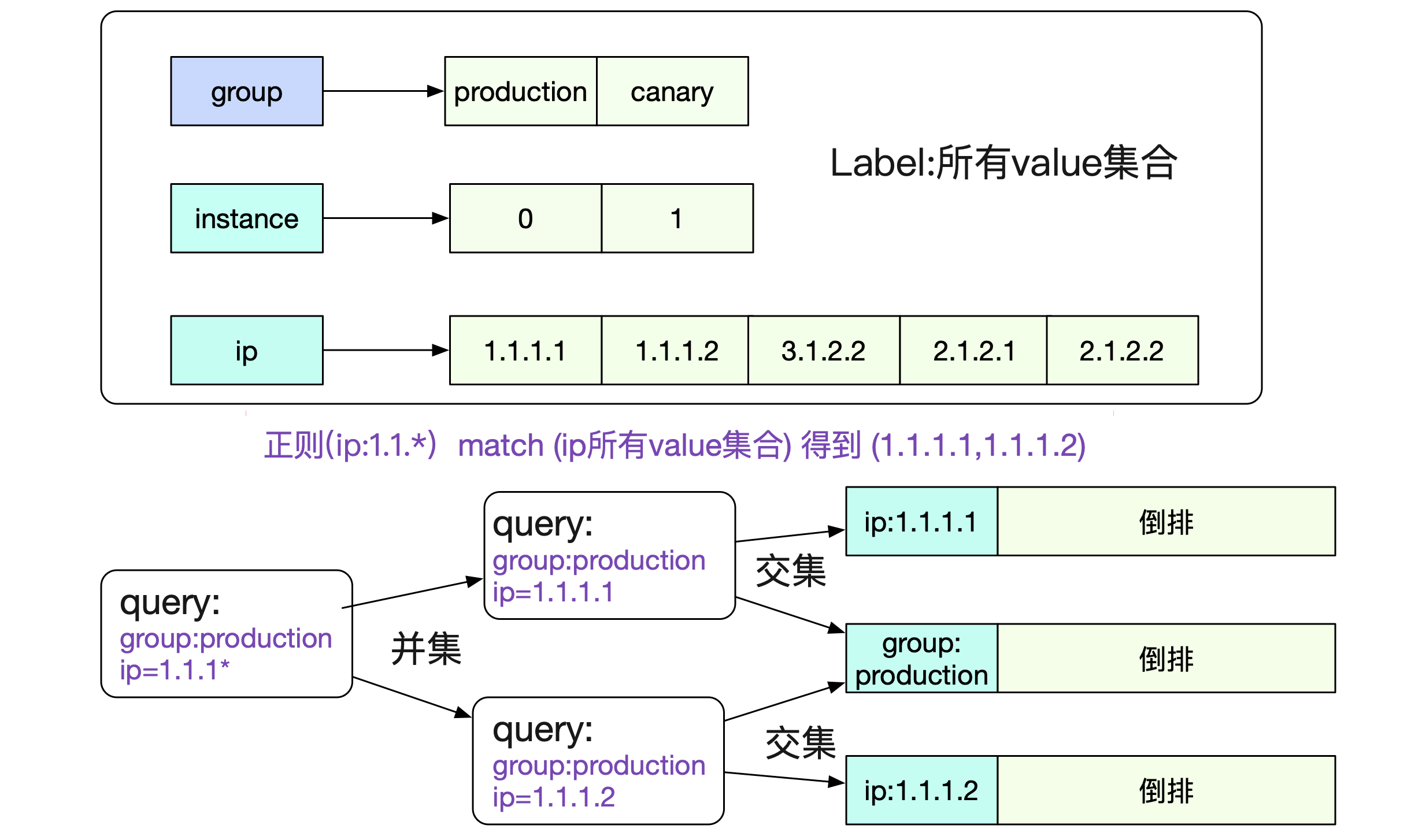
图中所示,有了label和对应所有value集合的表,一个正则请求就可以很容的分解为若干个非正则请求并最后求交/并/查集,即可得到最终的结果。
总结
Prometheus作为当今最流行的时序数据库,其中有非常多的值得我们借鉴的设计和机制。这一篇笔者主要描述了监控数据在内存中的存储结构。下一篇,将会阐述监控数据在磁盘中的存储结构,敬请期待!
欢迎大家关注我公众号,里面有各种干货,还有大礼包相送哦! 











