推荐
专栏
教程
课程
飞鹅
本次共找到1995条
分布式算法
相关的信息
Souleigh ✨
•
4年前
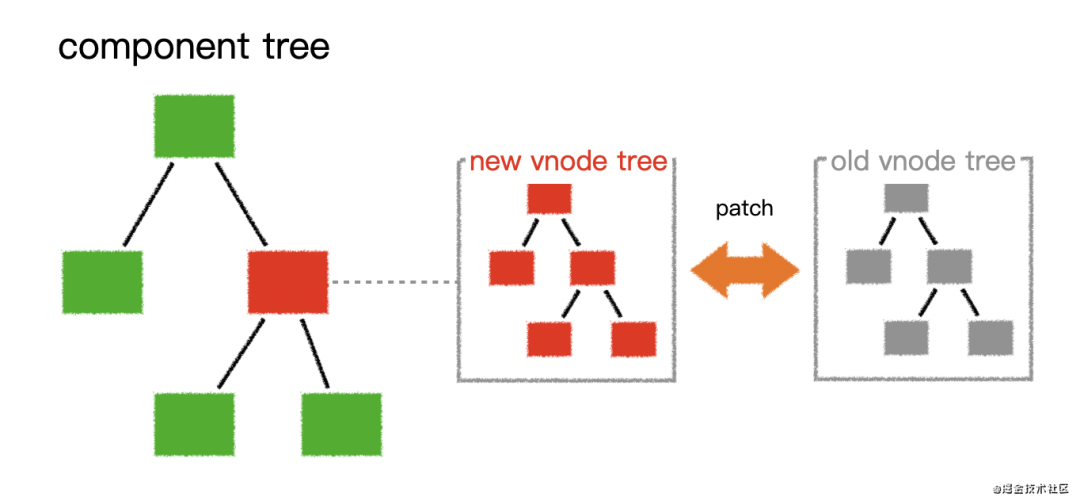
Vue - diff 算法
diff是什么?diff就是比较两棵树,render会生成两颗树,一棵新树newVnode,一棵旧树oldVnode,然后两棵树进行对比更新找差异就是diff,全称difference,在vue里面diff算法是通过patch函数来完成的,所以有的时候也叫patch算法⏳diff发生的时机diff发生在什么时候呢?当然我们可以说在数据更新的时候发生d
Easter79
•
4年前
Vue diff 算法
一、虚拟DOM(virtualdom) diff算法首先要明确一个概念就是diff的对象是虚拟DOM(virtualdom),更新真实DOM是diff算法的结果。 注:virtualdom 可以看作是一个使用JavaScript模拟了DOM结构的树形结构,这个树结构包含
Stella981
•
4年前
Redis分布式锁的正确实现方式
前言分布式锁一般有三种实现方式:1.数据库乐观锁;2.基于Redis的分布式锁;3.基于ZooKeeper的分布式锁。本篇博客将介绍第二种方式,基于Redis实现分布式锁。虽然网上已经有各种介绍Redis分布式锁实现的博客,然而他们的实现却有着各种各样的问题,为了避免误人子弟,本篇博客将详细介绍如何正确地实现Redis分布式锁。
Stella981
•
4年前
FCOS单阶段anchor
本文提出了一种全卷积onestage目标检测算法(FCOS),以逐像素预测的方式解决目标检测问题,类似于语义分割。目前最流行的不论是onestage目标检测算法,如RetinaNet,SSD,YOLOv3,还是twostage目标检测算法,如FasterRCNN。这两类算法大都依赖于预定义的锚框(anchorboxes)。相比之下,本文提出的目
Stella981
•
4年前
LightGBM 算法原理
LightGBM的动机GBDT(GradientBoostingDecisionTree)是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。GBDT在工业界应用广泛,通常被用于点击率预测,搜索排序等任务而GBDT在每一次迭代的时
Stella981
•
4年前
Seata是什么?一文了解其实现原理
一、背景随着业务发展,单体系统逐渐无法满足业务的需求,分布式架构逐渐成为大型互联网平台首选。伴随而来的问题是,本地事务方案已经无法满足,分布式事务相关规范和框架应运而生。在这种情况下,大型厂商根据分布式事务实现规范,实现了不同的分布式框架,以简化业务开发者处理分布式事务相关工作,让开发者专注于核心业务开发。Seata就是这么一个分布式事
Stella981
•
4年前
LVS调度算法
内核中的连接调度算法IPVS在内核中的负载均衡调度是以连接为粒度的。在HTTP协议(非持久中),每个对象从WEB服务器上获取都需要建立一个TCP连接,同一用户的不同请求会被调度到不同服务器上,所以这种细粒度的调度在一定程度上可以避免单个用户访问的突发性引起服务器间的负载不平衡。在内核中的连接调度算法上,IPVS已实现了以下八种调
后端bug开发工程师
•
3年前
常用限流算法详解
一、有哪些常用的限流算法1.固定窗口限流;2.滑动窗口限流;3.漏桶算法限流;4.令牌桶算法限流。二、4种限流算法介绍1.固定窗口限流举例说明:假设时间窗口大小为5s,则0到5s为第一个窗口,5到10s为第二个窗
1
•••
10
11
12
•••
200