推荐
专栏
教程
课程
飞鹅
本次共找到1481条
内存映射
相关的信息
美味蟹黄堡
•
3年前
VPS作用都有啥?
国内VPS服务器我们可以将它用在哪些地方,首先我们就要知道作为VPS主机,它所拥有哪些功能。今天就做一个简单的使用介绍,采用的环境是3A网络的VPS服务器,性价比较高。每个VPS服务器都可分配独立公网IP地址、独立操作系统、独立超大空间、独立内存、独立CPU资源、独立执行程序和独立系统配置等。VPS用户除了可以分配多个虚拟主机及无限企业邮箱外,更具有独立服
芝士年糕
•
3年前
top命令详细解读
1.top命令介绍top命令是Linux系统中常用的性能分析工具,可以实时地查看系统的运行情况,比如内存、CPU、负载以及各个进程的资源占用情况。租了一个服务器安装了centos系统,用到了top命令2.top命令输出结果分析首先来看一下执行top后的输出界面展示:top界面主要分为两个部分,前5行展示的是系统的整体性能,光标下面部分是系统中每个进程的具体信
芝士年糕
•
3年前
Nmon使用方法
一、简介1、nmon是一种在AIX与各种Linux操作系统上广泛使用的监控与分析工具,它能在系统运行过程中实时地捕捉系统资源的使用情况,记录的信息比较全面,并且能输出结果到文件中,然后通过nmonanalyzer工具产生数据文件与图形化结果。2、nmon可监控的数据类型内存使用情况磁盘适配器文件系统中的可用空间CPU使用率页面空间和页面速度异步I/O,仅适用
Wesley13
•
4年前
PIE SDK过滤控制
1. 功能简介 栅格数据前置过滤是在渲染之前对内存中的数据根据特定的规则进行处理,然后再进行数据渲染。本示例以定标为例进行示例代码编写。 定标(校准)是将遥感器所得的测量值变换为绝对亮度或变换为与地表反射率、表面温度等物理量有关的相对值的处理过程。或者说,遥感器定标就是建立遥感器每个探测器输出值与该探测器对应的实际地物辐射亮度之
Aimerl0
•
4年前
数据结构笔记
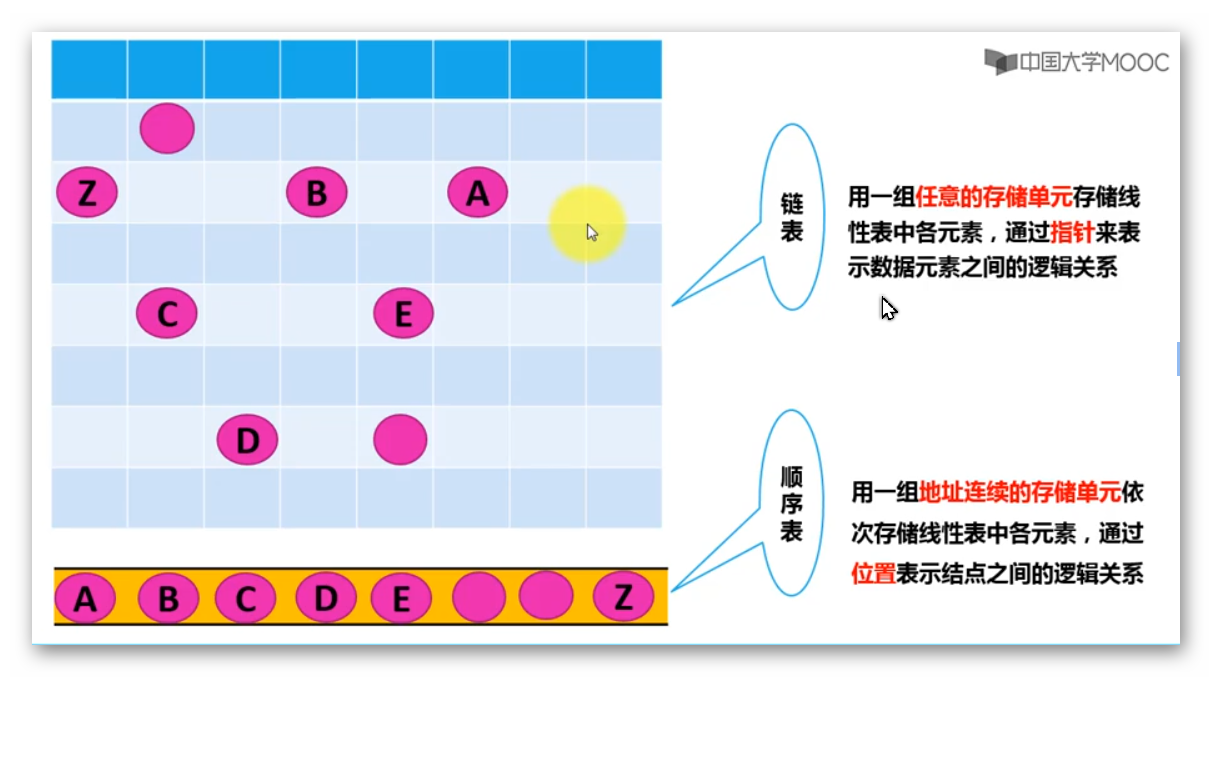
写在前面这个课是以前从来没接触过的东西,而且一直学web,太久没接触c语言了,第一节课看到for循环甚至有点陌生,学得有点吃力,所以必须整点笔记,记下相关概念、知识点和平时学习过程中的问题和思考,期末复习用第一章绪论数据结构研究:数据的逻辑结构(数据内部之间的构成方法)、数据的物理储存(数据在内存里面怎么存的)、数据的操作实现(用什么语言
九路
•
5年前
Oracle 程序员吐槽:永远不会再为 Oracle 工作了!
一位Oracle程序员在HackerNews上吐槽自己的工作,引起了热议,内容如下:Oracle数据库12.2。它有近2500万行C代码。这实在太恐怖了,简直难以想象!你做不到在不破坏成千上万个现有测试的情况下更改产品中的单单一行代码。好几代程序员在很紧的项目期限内编写了这些代码,代码中充斥着各种各样的垃圾内容。非常复杂的逻辑、内存管理和上下文
Souleigh ✨
•
5年前
实现深拷贝的多种方式
实现深拷贝的多种方式简单来说,深拷贝主要是将另一个对象的属性值拷贝过来之后,另一个对象的属性值并不受到影响,因为此时它自己在堆中开辟了自己的内存区域,不受外界干扰。浅拷贝主要拷贝的是对象的引用值,当改变对象的值,另一个对象的值也会发生变化。1.简单深拷贝(一层浅拷贝)①for循环拷贝//只复制第一层的浅拷贝javascriptfunc
Stella981
•
4年前
Mac安装Redis可视化工具
Redis是一个超精简的基于内存的键值对数据库(keyvalue),一般对并发有一定要求的应用都用其储存session,乃至整个数据库。不过它公自带一个最小化的命令行式的数据库管理工具,有时侯使用起来并不方便。不过Github上面已经有了很多图形化的管理工具,而且都针对REDIS做了一些优化,如自动折叠带schema的key等。RedisDesk
Stella981
•
4年前
Redis压缩列表
此篇文章是主要介绍Redis在数据存储方面的其中一种方式,压缩列表。本文会介绍1.压缩列表(ziplist)的使用场景2.如何达到节约内存的效果?3.压缩列表的存储格式4.连锁更新的问题 5.conf文件配置。在实践上的操作主要是对conf配置文件进行配置,具体上没有确切的一个值,更多是经验值。也有的项目会直接使用原本的默认值。此篇对于更好地理解
1
•••
144
145
146
•••
149