
这是作者在去年处理的一个关于进程保活的案例
一. 引言
1.1 保活概述
什么是保活?保活就是在用户主动杀进程,或者系统基于当前内存不足状态而触发清理进程后,该进程设法让自己免于被杀的命运或者被杀后能立刻重生的手段。
保活是”应用的蜜罐,系统的肿瘤“,应用高保活率给自己赢得在线时长,甚至做各种应用想做而用户不期望的行为,给系统带来的是不必要的耗电,以及系统额外的性能负担。
保活方案一直就层出不穷,APP开发们不断地绞尽脑汁让自己的应用能存活得时间更长, 主要思路有两个:
- 提升进程优先级,降低被杀概率
- 比如监听SCREEN_ON/OFF广播 启动一像素的透明Activity
- 启动空通知,提升fg-service
- 进程被杀后,重新拉起进程
- 监听系统或者第3方广播拉起进程。目前安全中心/Whetstone已拦截
- Native fork进程相互监听,监听到父进程被杀,则通过am命令启动进程。force-stop会杀整个进程组,几乎很难生效
1.2 保活案例
这是在2017年发现一款办公协作应用,在安全中心关闭TIM自启动功能的情况, 一键清理、强力清理等各大招都无法彻底杀掉TIM,系统的自启动拦截都没能阻止TIM的永生,这引起了我强烈的兴趣。
二. 初步分析
2.1 初识TIM
执行命令adb shell ps | grep tencent.tim,可见TIM共有4个进程, 其父进程都是Zygote
root@gityuan:/ # ps | grep tencent.tim
u0_a146 27965 551 1230992 43964 SyS_epoll_ 00f6df4bf0 S com.tencent.tim:Daemon
u0_a146 27996 551 1252492 54032 SyS_epoll_ 00f6df4bf0 S com.tencent.tim:MSF
u0_a146 28364 551 1348616 89204 SyS_epoll_ 00f6df4bf0 S com.tencent.tim:mail
u0_a146 31587 551 1406128 147976 SyS_epoll_ 00f6df4bf0 S com.tencent.tim 2.2 一键清理看现象,排查初步怀疑
以下是对TIM执行一键清理后的日志:
12-21 21:12:20.265 1053 1075 I am_kill : [0,4892,com.tencent.tim:Daemon,5,stop com.tencent.tim: from pid 4617]
12-21 21:12:20.272 1053 1075 I am_kill : [0,5276,com.tencent.tim:mail,2,stop com.tencent.tim: from pid 4617]
12-21 21:12:20.305 1053 1075 I am_kill : [0,4928,com.tencent.tim,2,stop com.tencent.tim: from pid 4617]
12-21 21:12:20.330 1053 1075 I am_kill : [0,4910,com.tencent.tim:MSF,0,stop com.tencent.tim: from pid 4617]
12-21 21:13:59.920 1053 1466 I am_proc_start: [0,5487,10146,com.tencent.tim:MSF,service,com.tencent.tim/com.tencent.mobileqq.app.DaemonMsfService]
12-21 21:13:59.984 1053 1604 I am_proc_start: [0,5516,10146,com.tencent.tim,content provider,com.tencent.tim/com.tencent.mqq.shared_file_accessor.ContentProviderImpl] Force-stop是系统提供的杀进程最为彻底的方式,详见文章Android进程绝杀技–forceStop。从日志可以发现一键清理后TIM的4个进程全部都已被Force-stop。但进程com.tencent.tim:MSF立刻就被DaemonMsfService服务启动过程而拉起。
问题1:安全中心已配置了禁止TIM的自启动, 并且安全中心和系统都有对进程自启动以及级联启动的严格限制,为何会有漏网之鱼?
怀疑1: 是否安全中心自启动没能有效限制,以及微信/QQ跟TIM有所级联,比如com.tencent.mobileqq.app.DaemonMsfService服务名中以com.tencent.mobileqq(QQ的包名)开头,经过dumpsys以及反复验证后排除了这种可能性,如下:
12-21 21:12:20.266 1053 1075 I AutoStartManagerService: MIUILOG- Reject RestartService packageName :com.tencent.tim uid : 10146
12-21 21:12:20.291 1053 1075 I AutoStartManagerService: MIUILOG- Reject RestartService packageName :com.tencent.tim uid : 10146
12-21 21:12:20.323 1053 1075 I AutoStartManagerService: MIUILOG- Reject RestartService packageName :com.tencent.tim uid : 10146
12-21 21:12:20.323 1053 1075 I AutoStartManagerService: MIUILOG- Reject RestartService packageName :com.tencent.tim uid : 10146
12-21 21:12:20.331 1053 1075 I AutoStartManagerService: MIUILOG- Reject RestartService packageName :com.tencent.tim uid : 10146
12-21 21:12:20.332 1053 1075 I AutoStartManagerService: MIUILOG- Reject RestartService packageName :com.tencent.tim uid : 10146 怀疑2: 是否在TIM进程被杀后, 收到BinderDied后的死亡回调过程中将Service再次拉起,这个情况也很快就被排除, 因为force-stop这种冷面强力杀手, 并不会等到死亡回调再去清理进程相关信息,而是直接连根拔起,并不会走到AMS的死亡回调。
怀疑3: TIM设置了alarm机制,在callApp为空符合特征, 但经过分析这里就是普通的startService, 非startServiceInPackage(), 也排除了这种可能性
//启动DaemonAssistService时,callApp为空,只有通过PendingIntent方式才可能出现这种情况
12-21 21:56:54.653 3181 3195 I am_start_service: [-1,NULL,10146,com.tencent.tim:Daemon,com.tencent.tim/com.tencent.mobileqq.app.DaemonAssistService,{cmp=com.tencent.tim/com.tencent.mobileqq.app.DaemonAssistService}]
12-21 21:56:56.666 3181 3827 I am_start_service: [-1,NULL,10146,com.tencent.tim:MSF,com.tencent.tim/com.tencent.mobileqq.app.DaemonMsfService,{cmp=com.tencent.tim/com.tencent.mobileqq.app.DaemonMsfService}] 既然排除以上3种可能,直接上断点来看看吧
2.3 Android Studio断点分析
一上断点就发现了意外的一幕:
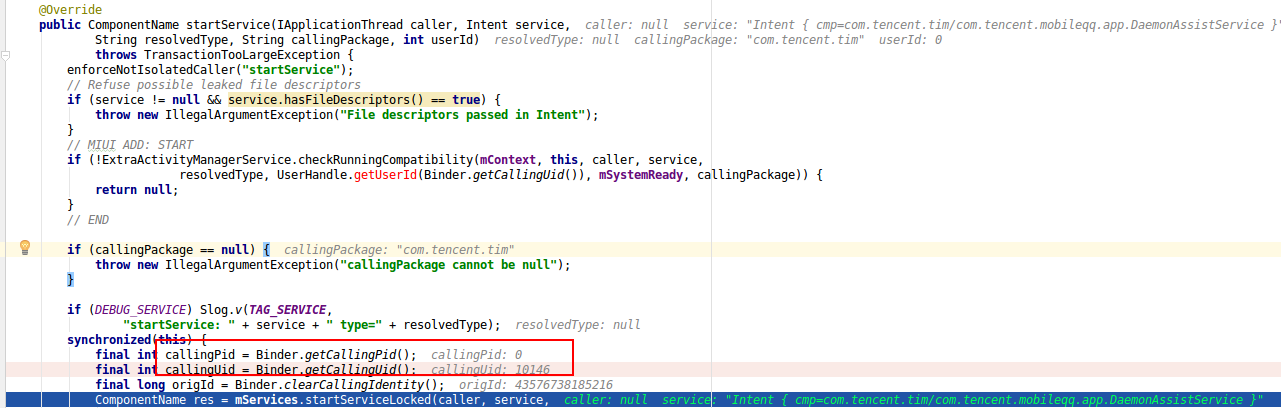
问题2:startService()的callingPid怎么可能等于0?
2.3.1 分析callingPid=0
为什么说上面是意外的一幕呢?这需要对binder底层原理有一定深入理解,才能看出一些端倪,那就是此处callingPid=0是不合理逻辑的。很多人可能不太理解为何就不合乎逻辑, 这要从Binder原理说起, startService()这个Binder call是属于同步binder调用, 对于binder调用过程,只有异步Binder调用的情况下callingPid=0才会为空, 因为不需要reply应答数据给发送binder请求的那一端。 但如果是同步的,则必须要给出callingPid,否则无法将应答数据回传给发送方。 这是由Binder Driver所决定的,见如下Binder Driver核心代码:
(1)Binder发起端:根据当前ONE_WAY来决定是否设置from线程
binder_transaction(...) {
...
if (!reply && !(tr->flags & TF_ONE_WAY))
t->from = thread;
else
t->from = NULL;
}
...
} (2)Binder接收端: 根据from线程是否为空, 来决定sender_pid是否为0. 这便是Java层所说的callingPid
binder_thread_read(...) {
...
t_from = binder_get_txn_from(t);
if (t_from) {
struct task_struct *sender = t_from->proc->tsk;
tr.sender_pid = task_tgid_nr_ns(sender,
task_active_pid_ns(current));
} else {
tr.sender_pid = 0;
}
...
} 上述代码表明: 同步的Binder调用的情况下则callingPid必定不等于0
下面告诉大家如何看一个Binder调用是否同步, 如下图最后一个参数代表的是FLAG_ONEWAY值,等于0则代表的是同步, 等于1则代表的是异步。
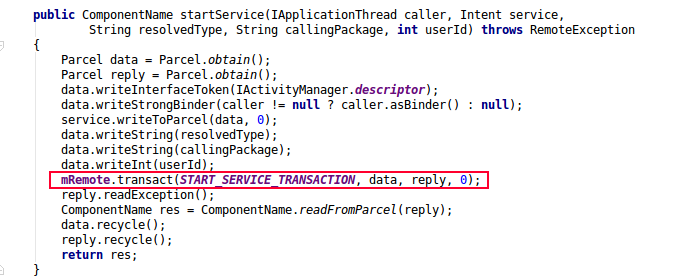
以上代码是framework的框架代码,startService最终都会调用到这里来,所以callingPid必然是不可能出现为0的情况,让我们看不透到底哪个进程把com.tencent.tim:Daemon拉起的。
2.3.2 揭秘
从前面的分析来看callingPid是不可能为0的, 但从结果来看的确是0, 出现矛盾就一定有反常规存在,难道是存在同步的Binder调用,也存在同时callingPid=0的case?答案是No.
从源码角度来看是没有这种可能性存在,后面再进一步追踪flags值的变化,从如下的flags=17,可以确定的是此处的startService的binder call是ONE_WAY的,这就可以确定的确是发起了异步的Binder调用,代码如下:
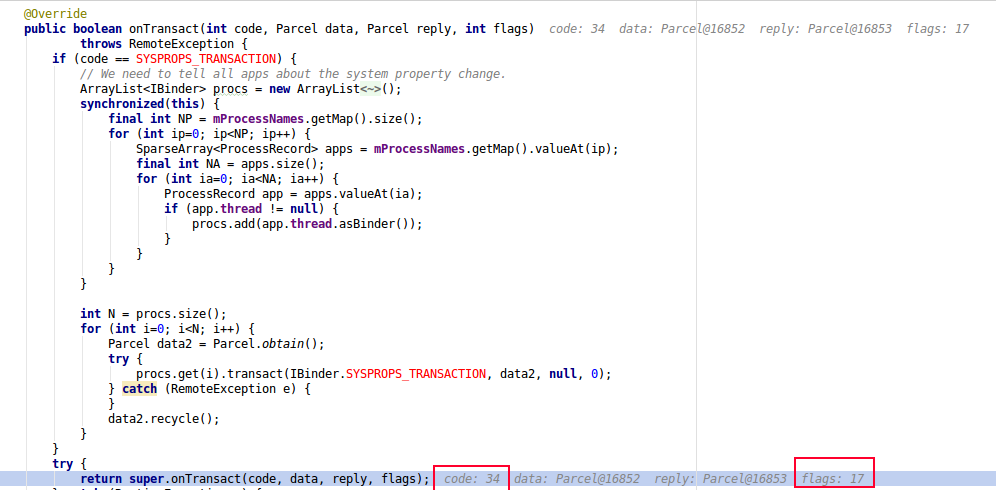
虽然callingPid=0,但从callUid=10146可以确定的一点是com.tencent.tim:Daemon进程是被来自TIM应用自身的某个进程所拉起的。
2.4 小结
通过前面的初步分析,先整理一下思路,有以下初步结论:
- TIM至少有4个进程,且都是由Zygote进程fork, 保活是通过startService被拉起
- 排除 安全中心的对TIM限制自启动功能失效的情况
- 排除 TIM进程被杀后的Binder死亡回调过程通过Service重新拉起进程
- 排除 alarm机制 拉起进程
- 从callingPid=0,可以得出TIM没有走常规的系统框架中提供的startService()接口来启动服务,而是自定义的方式
- 从callingUid=10146, 可以得出TIM救活自己的方式,是通过TIM自身,而非系统或者第三方应用拉起
到此不难得出一个猜想: 首先TIM应用能做到监听应用进程被杀的情况, 其次是TIM应用自身替换掉或者自定义一套Binder调用,主动跟Binder驱动进行数据交互。
三. 深入分析
3.1 寻求规律
TIM应用有4个进程,不断反复地尝试杀TIM每一个进程后,观察自启动的情况后。 发现了一个规律:com.tencent.tim:Daemon和com.tencent.tim:MSF进程任一被杀,都会先把对方进程拉起,然后跟着自杀后,再重启。
接下来就把范围锁定在这两个进程,然后来tracing信号处理情况。
3.2 从signal角度来分析
打开signal开关
root@gityuan:/ # echo 1 > /d/tracing/events/signal/enable
root@gityuan:/ # echo 1 > /d/tracing/tracing_on 执行如下命令抓取tracing log
root@cancro/: cat /d/tracing/trace_pipe 日志如下:
//通过adb shell kill -9 10649, 将com.tencent.tim:Daemon进程杀掉
sh-22775 [000] d..2 18844.276419: signal_generate: sig=9 errno=0 code=0 comm=cent.tim:Daemon pid=10649 grp=1 res=0
// 线程Thread-89 将tencent.tim:MSF进程也杀掉了
Thread-89-10712 [000] dn.2 18844.340735: signal_generate: sig=9 errno=0 code=0 comm=tencent.tim:MSF pid=10669 grp=1 res=0
Binder:14682_4-14845 [000] d..2 18844.340779: signal_deliver: sig=9 errno=0 code=0 sa_handler=0 sa_flags=0
Binder:14682_1-14694 [000] d..2 18844.341418: signal_deliver: sig=9 errno=0 code=0 sa_handler=0 sa_flags=0
Binder:14682_2-14697 [000] d..2 18844.345075: signal_deliver: sig=9 errno=0 code=0 sa_handler=0 sa_flags=0
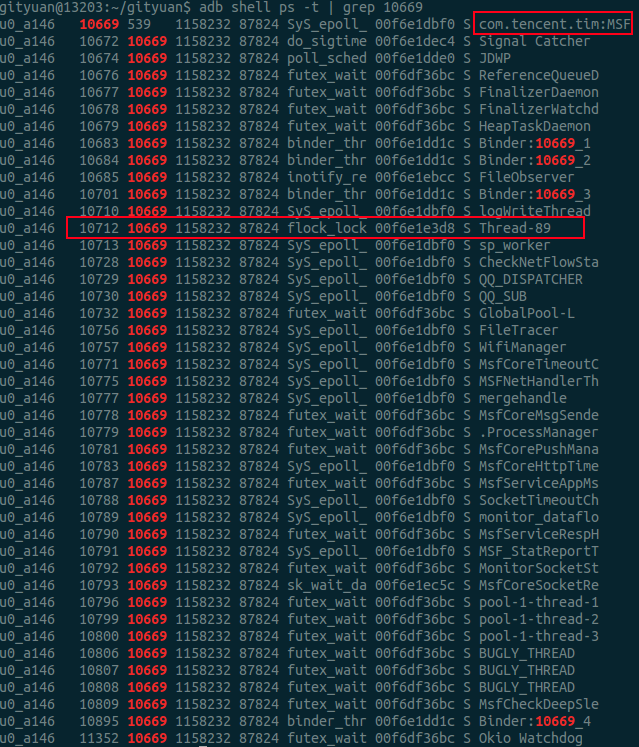
tencent.tim:MSF-14682 [000] dn.2 18844.345115: signal_deliver: sig=9 errno=0 code=0 sa_handler=0 sa_flags= 从这里,可以发现com.tencent.tim:Daemon进程是由于其中一个线程Thread-89所杀,但从名字来看Thread-xxx,很明显是系统自动生成的编号。
问题3:进程内的名叫“Thread-89”的线程具有什么特点,如何做到把进程杀掉?
从下面的截图,可以看出MSF进程的这个特殊的线程当前在执行flock_lock操作,这个明显是一个文件加锁的操作, 这个方法很快就引起了我的注意。同理Daemon进程也有一个这样的线程, 离真相有近了一步。

再来看看调用栈情况
Cmd line: com.tencent.tim:Daemon
"Thread-89" prio=10 tid=12 Native
| group="main" sCount=1 dsCount=0 obj=0x32c07460 self=0xf3382000
| sysTid=10712 nice=-8 cgrp=bg_non_interactive sched=0/0 handle=0xee824930
| state=S schedstat=( 44972457 14188383 124 ) utm=1 stm=3 core=0 HZ=100
| stack=0xee722000-0xee724000 stackSize=1038KB
| held mutexes=
kernel: __switch_to+0x74/0x8c
kernel: flock_lock_file_wait+0x2a4/0x318
kernel: SyS_flock+0x19c/0x1a8
kernel: el0_svc_naked+0x20/0x28
native: #00 pc 000423d4 /system/lib/libc.so (flock+8)
native: #01 pc 0000195d /data/app/com.tencent.tim-1/lib/arm/libdaemon_acc.so (_Z9lock_filePc+64)
...
native: #29 pc 0000191f /data/app/com.tencent.tim-1/lib/arm/libdaemon_acc.so (_Z9lock_filePc+2)
native: #30 pc 0000191d /data/app/com.tencent.tim-1/lib/arm/libdaemon_acc.so (_Z9lock_filePc)
native: #31 pc 0000191b /data/app/com.tencent.tim-1/lib/arm/libdaemon_acc.so (_Z18notify_and_waitforPcS_+102)
...
native: #63 pc 000018d1 /data/app/com.tencent.tim-1/lib/arm/libdaemon_acc.so (_Z18notify_and_waitforPcS_+28)
at com.libwatermelon.WaterDaemon.doDaemon2(Native method)
at com.libwatermelon.strategy.WaterStrategy2$2.run(WaterStrategy2.java:111) 从这个线程的调用栈中的名字, notify_and_waitfor让我想到了这极有可能用于监听文件来获知进程是否存活。 为了进一步观察这个特殊线程的工作使命, 这里还不需要GDB, 祭出strace大招应该就差不多
3.3 利用strace分析
root@gityuan:/ # strace -CttTip 22829 -CttTip 22793
结果如下:

flock基础知识简介:
flock是Linux文件锁,用于多个进程同时操作同一个文件时,通过加锁机制保证数据的完整,flock使用场景之一,便是用于检测进程是否存在。flock属于建议性的锁,而非强制性锁,只是进程可以直接操作正被另一个进程用flock锁住的文件, 原因在于flock只检测文件是否加锁,内核并不会强制阻塞其他进程的读写操作,这便是建议性锁的内核策略。
方法原型: int flock(int fd, int operation)
第一个参数是文件描述符,第二参数指定锁的类型,有以下3个可选值:
- LOCK_SH: 共享锁, 同一时间运行多个进程同时持有该共享锁
- LOCK_EX: 排它锁,只允许一个进程持有该锁
- LOCK_UN: 移除该进程的该文件所持有的锁
从strace可以推测出:com.tencent.tim:MSF进程的监控线程执行排它锁LOCK_EX类型的flock,尝试去获取某个文件,而该文件已被com.tencent.tim:Daemon进程所持有,所以MSF进程会被阻塞知道锁的释放,而一旦Daemon进程被杀,系统就会回收所有资源(包括文件),这是Linux内核负责完成的。
当Daemon进程的文件被回收,就会释放flock, 从而MSF进程可以获取该锁,从而吐出“lock file success”的信息。 MSF得知Daemon进程被杀,然后执行一行ioctl(11, BINDER_WRITE_READ, 0xffffffffee823ed0) = 0 <0.000867> ,
这个应该就是TIM进程自身实现了一套执行startService的Binder调用,向Binder驱动发送 BINDER_WRITE_READ的ioctl命令。 再然后发送kill SIGKILL将自身MSF进程杀掉,同样的道理可以再次被拉起。
分析到这里,看执行了writev操作, 应该就是Log操作, 有一个关键词到Watermelon吸引了我的注意力, 搜索Watermelon关键词,果然找到新的一片天地。
3.4 TIM日志
//旧的MSF进程
24538 24562 D Watermelon: lock file success >> /data/user/0/com.tencent.tim/app_indicators/indicator_p2
24538 24562 E Watermelon: Watch >>>>Daemon<<<<< Daed !!
24538 24562 E Watermelon: java_callback:onDaemonDead
24538 24562 V Watermelon: onDaemonDead
24576 24576 D Watermelon: lock file success >> /data/user/0/com.tencent.tim/app_indicators/indicator_d1
24576 24576 E Watermelon: Watch >>>>Daemon<<<<< Daed !!
24576 24576 E Watermelon: process exit
//新daemon进程
25103 25103 V Watermelon: initDaemon processName=com.tencent.tim:Daemon
25103 25103 E Watermelon: onDaemonAssistantCreate
25134 25134 D Watermelon: start daemon24=/data/user/0/com.tencent.tim/app_bin/daemon2
//app_d进程
25137 25137 D Watermelon: pipe read datasize >> 316 <<
25137 25137 D Watermelon: indicator_self_path >> /data/user/0/com.tencent.tim/app_indicators/indicator_d1
25137 25137 D Watermelon: observer_daemon_path >> /data/user/0/com.tencent.tim/app_indicators/observer_p1
25137 25137 I Watermelon: sIActivityManager==NULL
25137 25137 I Watermelon: BpActivityManager init
//新daemon
25103 25120 D Watermelon: start try to lock file >> /data/user/0/com.tencent.tim/app_indicators/indicator_p2
25103 25120 D Watermelon: lock file success >> /data/user/0/com.tencent.tim/app_indicators/indicator_p2
25137 25137 I Watermelon: BpActivityManager init end
//app_d进程
25137 25137 D Watermelon: start try to lock file >> /data/user/0/com.tencent.tim/app_indicators/indicator_d1
25137 25137 D Watermelon: lock file success >> /data/user/0/com.tencent.tim/app_indicators/indicator_d1
//新MSF进程
25119 25119 V Watermelon: initDaemon processName=com.tencent.tim:MSF
25119 25119 V Watermelon: mConfigurations.PERSISTENT_CONFIG.PROCESS_NAME=com.tencent.tim:MSF
25119 25119 E Watermelon: onPersistentCreate
25153 25153 D Watermelon: start daemon24=/data/user/0/com.tencent.tim/app_bin/daemon2
25119 25144 D Watermelon: pipe write len=324
25159 25159 D Watermelon: pipe read datasize >> 324 <<
25159 25159 D Watermelon: indicator_self_path >> /data/user/0/com.tencent.tim/app_indicators/indicator_p1
25159 25159 D Watermelon: observer_daemon_path >> /data/user/0/com.tencent.tim/app_indicators/observer_d1
25159 25159 I Watermelon: sIActivityManager==NULL
25159 25159 I Watermelon: BpActivityManager init
25119 25144 D Watermelon: start try to lock file >> /data/user/0/com.tencent.tim/app_indicators/indicator_d2
25119 25144 D Watermelon: lock file success >> /data/user/0/com.tencent.tim/app_indicators/indicator_d2
25159 25159 I Watermelon: BpActivityManager init end
//各进程进入监听就绪状态
25159 25159 D Watermelon: start try to lock file >> /data/user/0/com.tencent.tim/app_indicators/indicator_p1
25159 25159 D Watermelon: lock file success >> /data/user/0/com.tencent.tim/app_indicators/indicator_p1
25119 25144 E Watermelon: Watched >>>>OBSERVER<<<< has been ready...
25119 25144 D Watermelon: start try to lock file >> /data/user/0/com.tencent.tim/app_indicators/indicator_p2
25159 25159 E Watermelon: Watched >>>>OBSERVER<<<< has been ready...
25159 25159 D Watermelon: start try to lock file >> /data/user/0/com.tencent.tim/app_indicators/indicator_d1
25137 25137 E Watermelon: Watched >>>>OBSERVER<<<< has been ready...
25137 25137 D Watermelon: start try to lock file >> /data/user/0/com.tencent.tim/app_indicators/indicator_p1
25103 25120 E Watermelon: Watched >>>>OBSERVER<<<< has been ready...
25103 25120 D Watermelon: start try to lock file >> /data/user/0/com.tencent.tim/app_indicators/indicator_d2 再从其中的截取核心片段:
25159 25159 I Watermelon: BpActivityManager init
25119 25144 D Watermelon: start try to lock file >> /data/user/0/com.tencent.tim/app_indicators/indicator_d2
25119 25144 D Watermelon: lock file success >> /data/user/0/com.tencent.tim/app_indicators/indicator_d2 不难看出:
- TIM自身通过向servicemanager查询来获取AMS的代理BpActivityManager, 然后自己去写startService通信过程的数据
- TIM通过两个进程通过flock来相互监听对方进程存活状态
- 监听的文件有比如:/data/user/0/com.tencent.tim/app_indicators/indicator_d2
3.5 indicator文件
进一步查看TIM所监听的路径下/data/user/0/com.tencent.tim/app_indicators/, 发现有4个监听文件:

问题4:为何需要4个indicator文件?
进一步延伸:通过查看flock,再次发现新大陆,原来除了Daemon和MSF进程各有一个监听文件的线程, 还有两个由init进程作为父进程的app_d进程也监听文件
gityuan@13203:~/gityuan$ adb shell ps -t | grep -i flock
u0_a146 10668 10649 1143304 85876 flock_lock 00f6e1e3d8 S Thread-85
u0_a146 10712 10669 1158552 89664 flock_lock 00f6e1e3d8 S Thread-89
u0_a146 10687 1 12768 564 flock_lock 00f73113d8 S app_d
u0_a146 10717 1 12768 560 flock_lock 00f74353d8 S app_d 不难发现,以上几个进程/线程的uid=10146,进一步通过ps命名查找。
再一次刷新对TIM应用的认识: 原来TIM有6个进程,其中还有2个是挂在init进程下,名字跟tencent没有关系,差点错过了这两个特殊的进程

这两个app_d进程其实也是做着同样的相互监听的工作, 应该是备选方案。当有概率恰巧Daemon和MSF进程同时被杀而来不及互保的情况下,那么可以走紧急通道app_d 将TIM进程拉起。可谓是暗藏玄机, 6个进程中有4个进程可以相互保活, 以保证TIM进程永生。
问题5: 这4个进程到达是什么如何相互监听的呢?
通过不断分析被杀与重启前后的规律与特征,得出进程与监听文件的关系图:
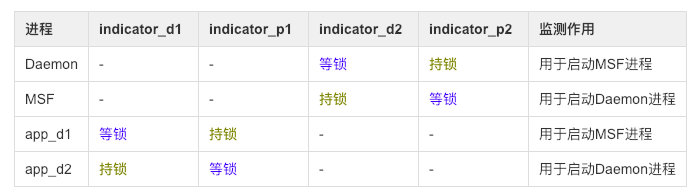
进一步揭露面纱,得到如下结论:
- Daemon与MSF两进程等待对方所持有的锁,两个app_d进程相互等待对方所持有的锁
- app_d1进程被杀, 则app_d2观察后通过拉起DaemonMsfService服务来启动MSF进程,然后跟着被杀
- app_d2进程被杀,则app_d1观察后通过拉起DaemonAssistService服务来启动Daemon进程,然后跟着被杀
- Daemon与MSF两进程, 如果杀掉其中一个,则另个一个进程观察后通过拉起服务方式来启动对方进程,然后跟着被杀;然后app_d两个进程也跟着重启
另外,猜想:监测indicator_p1和indicator_p2的两个进程有关联,indicator_d1和indicator_d2的进程有关联,后面会验证。
到这里又有出现新的疑问,Daemon进程死后,MSF进程通过flock能监测到该事件,可是app_d进程又是如何得知的呢? app_d得知之后,又为何要再次自杀重启?
3.6 从cgroup角度来分析
root@gityuan:/acct/uid_10146/pid_10649 # cat cgroup.procs
10649 //Daemon
10687 //app_d
root@gityuan:/acct/uid_10146/pid_10669 # cat cgroup.procs
10669 //MSF
10717 //app_d 从而,进一步获取更多关于TIM深层次的关联,通过查看cgroup发现,Daemon和app_d1是同一个group的, MSF和app_d2是同一个group的。
问题6: app_d到底是如何创建出来?又是如何成为init进程的子进程的?
从进程创建与退出的角度来看看来看
// 5170(MSF进程) --> 5192 --> 5201(退出) --> 5211(存活)
tencent.tim:MSF-5170 [001] ...1 55659.446062: sched_process_fork: comm=tencent.tim:MSF pid=5170 child_comm=tencent.tim:MSF child_pid=519
Thread-300-5192 [000] ...1 55659.489621: sched_process_fork: comm=Thread-300 pid=5192 child_comm=Thread-300 child_pid=5201
<...>-5201 [003] ...1 55659.501074: sched_process_exec: filename=/data/user/0/com.tencent.tim/app_bin/daemon2 pid=5201 old_pid=5201
daemon2-5201 [009] ...1 55659.533492: sched_process_fork: comm=daemon2 pid=5201 child_comm=daemon2 child_pid=5211
daemon2-5201 [009] ...1 55659.535169: sched_process_exit: comm=daemon2 pid=5201 prio=120
daemon2-5201 [009] d..3 55659.535341: signal_generate: sig=17 errno=0 code=262145 comm=Thread-300 pid=5192 grp=1 res=1 说明:其中一个app_d进程是由MSF进程,通过两次fork,然后父进程退出,从而成为了孤儿进程,然后托孤给init进程,这是Linux进程机制所保证的。 同理,另一个app_d进程是由Daemon进程所fork。到这里,那么总算是认清的app_d的由来。 app_d是由于cgroup关联所以可以得知Daemon进程的情况。 关于重启的原因是为了重新建立互动的关系
问题7:为何单杀daemon,会牵连app_d进程被杀,这是什么原理?
解答:从杀进程的日志上来是调用killProcessGroup()杀进程,可事实上adb只调用kill -9 pid的方式,单杀一个进程,怎么就牵连了app_d进程。 这是由于当daemon进程被杀后,死亡回调会回来后,在binderDied()的过程执行了killProcessGroup()。
如果从Linux内核层面,研究过Binder死亡回调机制的童鞋,到这里还就会有想到一个新的疑问如下:
问题8:app_d是由daemon进程间接fork出来的, 会共享binder fd,所以即便daemon进程被杀,死亡回调也不会触发,这又是何触发的呢?
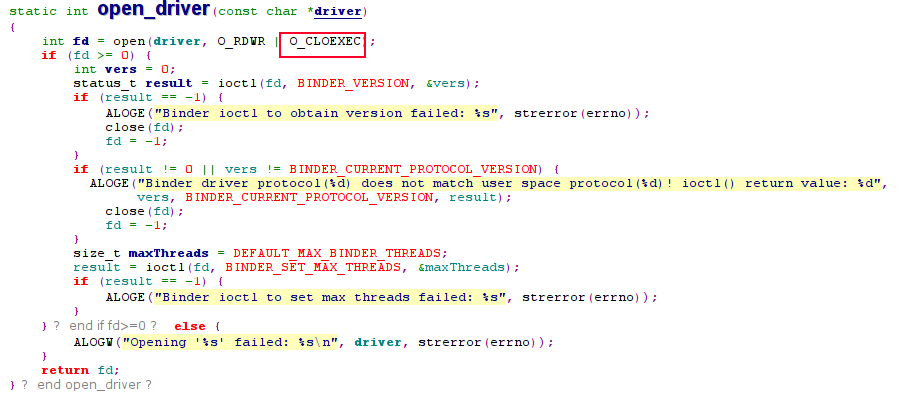
解答:由于app_d进程被fork后,马上执行了exec()系的函数, 而在ProcessState打开Binder驱动的时候, 有一个非常重要的flag, 那就是O_CLOEXEC。
采用O_CLOEXEC方式打开的问题,当新创建的进程调用exec()函数成功后,文件描述符会自动关闭, 代码如下:
3.7 剖根问底
问题9:TIM到底对Binder框架做了什么级别的修改?这4个互保进程,既然callingPid=0,有没有办法知道到底是由谁拉起谁的?
前面既然说了,TIM强行修改了ONEWAY的方式。可以去掉该flags, 为了调试,这里就针对TIM,并且code=34(即START_SERVICE_TRANSACTION), 并且修改flag的case下:
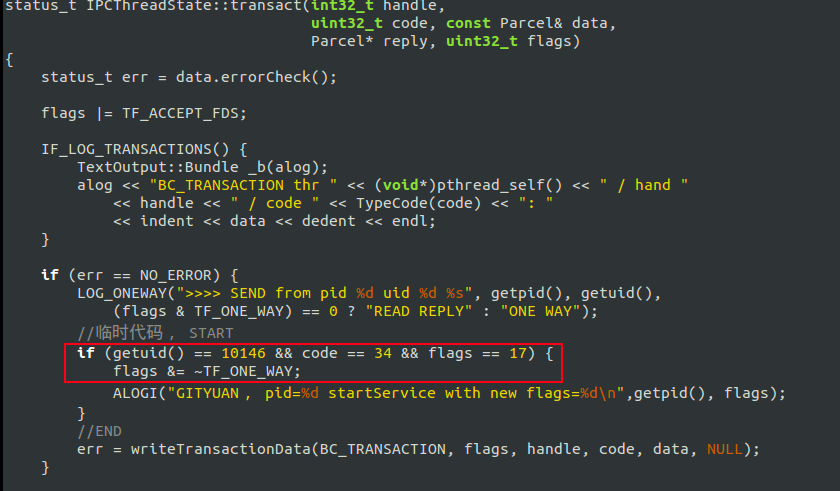
从实验结果来看,通过修改IPCThreadState.cpp代码, 完成control住了 TIM的所有修改, 这里可以说明:
TIM分别在Java层和Native层,主动向ServiceManager进程查询AMS后,获取BpActivityManager代理对象,然后继续使用框架中的IPCThreadState跟Binder驱动交互,并没有替换掉libbinder.so。
其实,还可以更高级的玩法,连IPCThreadState这些框架通信代码也不使用, 彻底地去自定义Binder交互代码,类似于servicemanager的方式。可以自己封装ioctl(),直接talkWithDriver。TIM保活还有改进空间, 提供保活变种方案,这样的话,上面的调试代码也拦截不了其对flags修改为ONEWAY的过程。 即使如此,一切都在Control之中, 完全可以在Binder Driver中拦截再定位其策略, 玩得再高级也主要活动在用户态, 内核态的策略还是相对安全的, 此所谓“魔高一座,道高一尺”。
另外,通过增加上面的临时代码,再次多次实验对比,可以得出如下关系图:
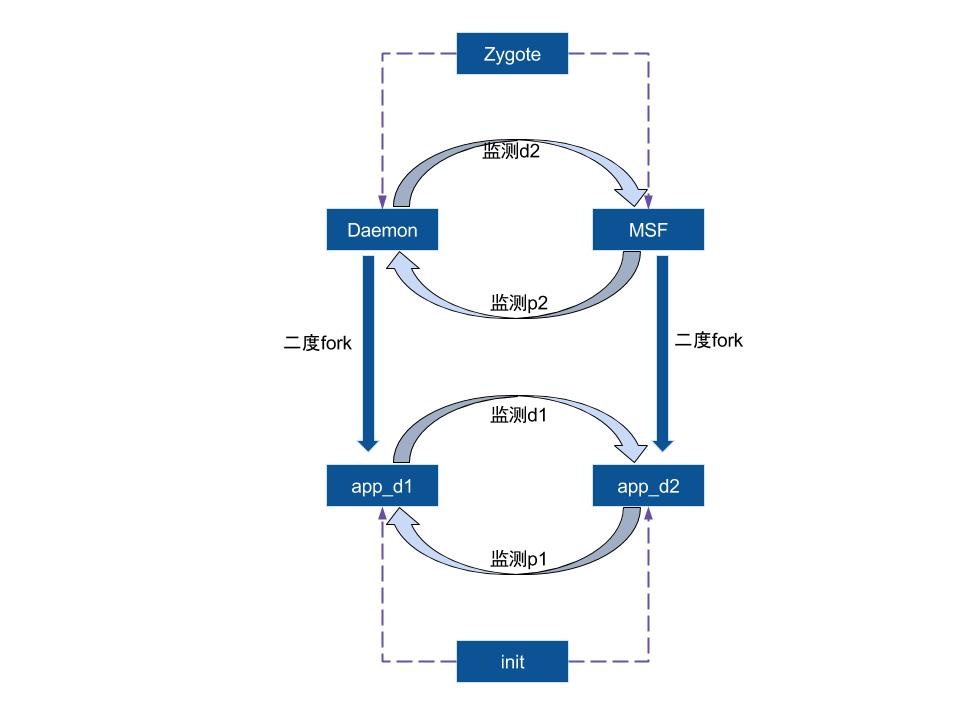
二度fork是指前面介绍了,fork后再fork,然后托孤,无论如何跟最初的进程都属于同一个group,有着级联被杀关系。
- 杀掉Daemon进程,则MSF进程观察到会去拉起Daemon进程; 同时app_d1因为同一个group而被杀,则app_d2进程观察到也拉起Daemon进程,这就是双保险;
- 杀掉app_d1进程, 则app_d2进程观察到会拉起MSF进程;
- 直接force-stop进程, 则6个进程都会被杀,只是杀的过程并非所有进程同一时刻点被杀,而是有前后顺序,所以造成能自启。
3.8 分析思路归纳
- 先有了初步分析过程中对一些常规套路的可能性的排除,并嗅到callingPid=0的异常举动
- 沿着蛛丝马迹,不断反复尝试杀进程,从中寻找更多的规律,不断地向自己提出疑问
- 结合signal,strace, traces,ps,binder,linux,kill等技能 不断地解答自己的疑惑
解系统层的问题,更像是侦探破案的感觉,要有敏锐的嗅觉,抓住蛛丝马迹,加上”大胆猜想,小心验证“ , 终究能找到案件的真相。 此所谓”点动成线,线动成面,面动成体“, 从零星的点滴勾画出全方面立体化的真相。
归纳下,主要提出过这些疑惑:
问题1:安全中心已配置了禁止TIM的自启动, 并且安全中心和Whetstone都有对进程自启动以及级联启动的严格限制, 为何会有漏网之鱼?
问题2:startService()的callingPid怎么可能等于0?
问题3:进程内的名叫“Thread-89”的线程具有什么特点,如何做到把进程杀掉?
问题4:为何需要4个indicator文件?
问题5: 这4个进程到达是什么如何相互监听的呢?
问题6: app_d到底是如何创建出来?又是如何成为init进程的子进程的?
问题7:为何单杀daemon,会牵连app_d进程被杀,这是什么原理?
问题8:app_d是由daemon进程间接fork出来的, 会共享binder fd,所以即便daemon进程被杀,死亡回调也不会触发,这又是何触发的呢?
问题9:TIM到底对Binder框架做了什么级别的修改?这4个互保进程,既然callingPid=0,有没有办法知道到底是由谁拉起谁的?
四. 总结
保活技术点
- 通过flock的文件排它锁方式来监听进程存活状态
- 先采用一对普通的进程Daemon和MSF相互监听文件的方式来获得对方进程是否存活的状态;
- 同时再采用一对退孤给init进程的app_d进程相互监听文件的方式来获得对方进程是否存活的状态; 而这两个进程都有间接由Daemon和MSF进程所fork而来;双重保险
- 不采用系统框架中startService的Binder框架代码,而是自身在Native层通过自己去查询获取BpActivityManager代理对象, 然后自己实现startService接口,并修改为ONEWAY的binder调用,既增加分析问题的难度,也进一步隐藏自身策略;
- 当监听进程死亡,则通过自身实现的StartService的Binder call去拉起对方进程,系统对于这种方式启动进程并没有拦截机制。
这种flock的方式至少比网上常说的通过循环监听的方式,要强很多;比往常的互保更厉害的是TIM共有6个进程(说明:使用过程也还会创建一些进程),其中4个进程,形成两组互动进程,其中一组利用Linux进程托孤原理,可谓是隐藏得很深来互保,进一步确保进程永生; 当然,进程收到signal信号后,如果恰巧这四个进程在同一个时刻点退出,那么还是有概率会被杀。 不走系统框架代码,自己去实现启动服务的binder call也是一大亮点,不过还有更高级的玩法,直接封装ioctl跟驱动交互。之前针对这个问题,做过反保活方案,后来为了某些功能缘故又放开对这个的限制,这里就不再继续展开了。
本文转自 http://gityuan.com/2018/02/24/process-keep-forever/,如有侵权,请联系删除。











