推荐
专栏
教程
课程
飞鹅
本次共找到3687条
关系型数据库
相关的信息
helloworld_94734536
•
4年前
数据存储-大数据的三种存储方式
互联网时代各种存储框架层出不穷,眼花缭乱,比如传统的关系型数据库:Oracle、MySQL;新兴的NoSQL:HBase、Cassandra、Redis;全文检索框架:ES、Solr等。如何为自己的业务选取合适的存储方案,相信大家都思考过这个问题,本文简单聊聊我对Mysql、HBase、ES的理解,希望能和大家一起探讨进步,有不对的地方还请指出。MySQL:
kelly
•
4年前
磁盘读写与数据库的关系
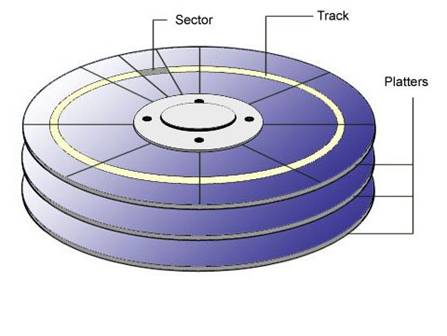
一磁盘物理结构(1)盘片:硬盘的盘体由多个盘片叠在一起构成。(https://imghelloworld.osscnbeijing.aliyuncs.com/ca8257beee4683c9331279708f8136d1.
Stella981
•
4年前
Hive SQL使用过程中的奇怪现象
hive是基于Hadoop的一个数据仓库工具,用来进行数据的ETL,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能。HiveSQL是一种类SQL语言,与关系型数据库所支持的SQL语法存在微小的差异。本文对比MySQL和Hive所支持的SQL语法,发现相同的SQL语句在
Stella981
•
4年前
Elasticsearch从入门到放弃:瞎说Mapping
前面我们聊了Elasticsearch的索引、搜索和分词器,今天再来聊另一个基础内容——Mapping。Mapping在Elasticsearch中的地位相当于关系型数据库中的schema,它可以用来定义索引中字段的名字、定义字段的数据类型,还可以用来做一些字段的配置。从Elasticsearch7.0开始,Mapping中不在乎需要
Wesley13
•
4年前
Java面试题
91,什么是ORM? 对象关系映射(ObjectRelationalMapping,简称ORM)是一种为了解决程序的面向对象模型与数据库的关系模型互不匹配问题的技术; 简单的说,ORM是通过使用描述对象和数据库之间映射的元数据(在Java中可以用XML或者是注解),将程序中的对象自动持久化到关系数据库中或者将
Easter79
•
4年前
TiDB 在金融行业关键业务场景的实践(上篇)
TiDB作为一款高效稳定的开源分布式数据库,在国内外的银行、证券、保险、在线支付和金融科技行业得到了普遍应用,并在约20多种不同的金融业务场景中支撑着用户的关键计算。本篇文章将为大家介绍分布式关系型数据库TiDB在金融行业关键应用领域的实践。金融关键业务场景银行的业务系统非常复杂,包括从核心上的账户、账务、结算等业务到外围
Stella981
•
4年前
JPA、Hibernate框架、通用mapper
JPA是描述对象关系表的映射关系,将运行期实体对象持久化到数据库中,提出以面向对象方式操作数据库的思想。Hibernate框架核心思想是ORM实现自动的关系映射。缺点:由于关联操作提出Hql语法。执行CRUD时产生大量冗余的sql,性能较低mybatis继承Hibernate优点,使用通用mapper插件实现JPA的思想操作数据库通用map
Wesley13
•
4年前
MongoDB 安装及文档的基本操作
!(https://oscimg.oschina.net/oscnet/upd8eda6ee91df47c0b9dc9005b1f5b85acd1.JPEG)前言MongoDB是一个基于分布式文件存储的半结构化的非关系型数据库。在海量数据中,可以较高性能的处理存取操作。它是以BSON格式进行数据存储(类似JSON格式,但类型更为
Wesley13
•
4年前
CTF 常见操作总结
一般流程1.首先看header,veiwsource,目录扫描2.有登陆,尝试sql注入&爆破3.有数据库,必然sql注入?普通sql注入1.判断是否存在回显异常尝试单双引号2.查是字符型?数值型?若1'成功查询,则是字符型若失败则是数值型3.确定字段数1'
Stella981
•
4年前
ElasticSearch底层原理浅析
基本概念索引(Index)ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的
1
•••
14
15
16
•••
369