推荐
专栏
教程
课程
飞鹅
本次共找到806条
全文搜索
相关的信息
Karen110
•
4年前
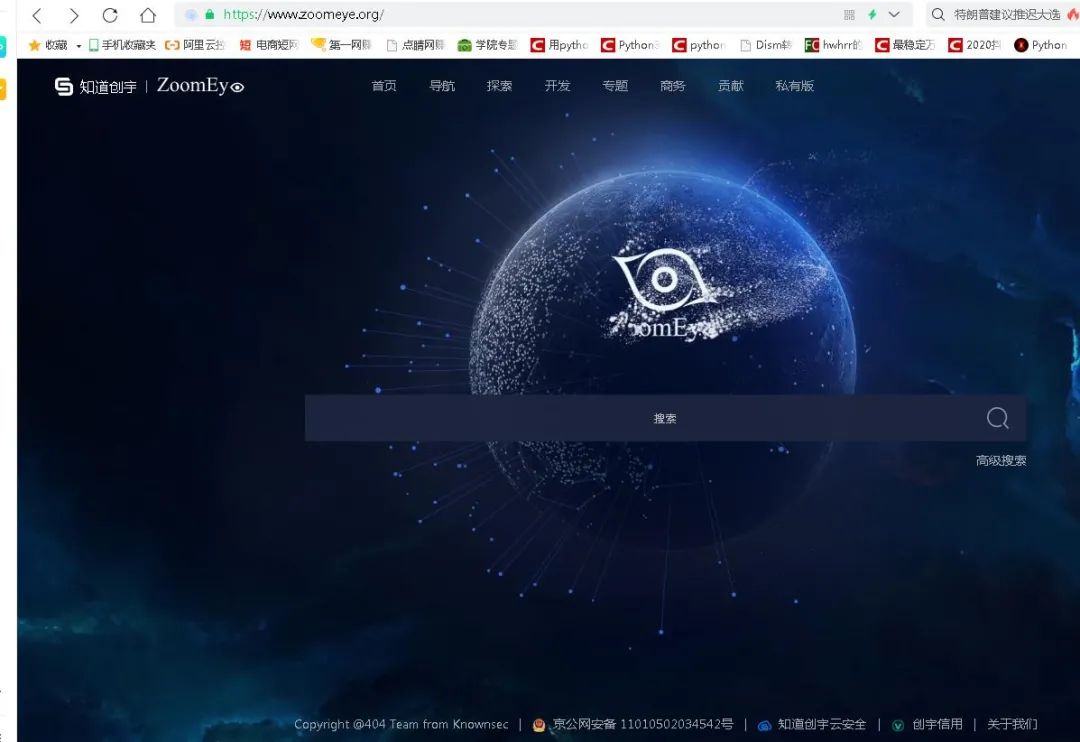
有了它,全球网络摄像头一览无余
大家好,我是IT共享者,人称皮皮。前言相信大家对于以前的网络摄像头泄露,各大宾馆开房视频频繁泄露,一定不会陌生了吧,当时,小编也在想,这些黑客是如何办到的了,本期小编就来为大家进行解密,揭开这层神秘的面纱。一、网站获取1.ZoomEy中文名叫钟馗之眼,是专门用来获取全球网络摄像头的网站解析库,界面很美而且简洁,如图:我们可以通过输入关键词来搜索相关
公众号: 奋飞安全
•
4年前
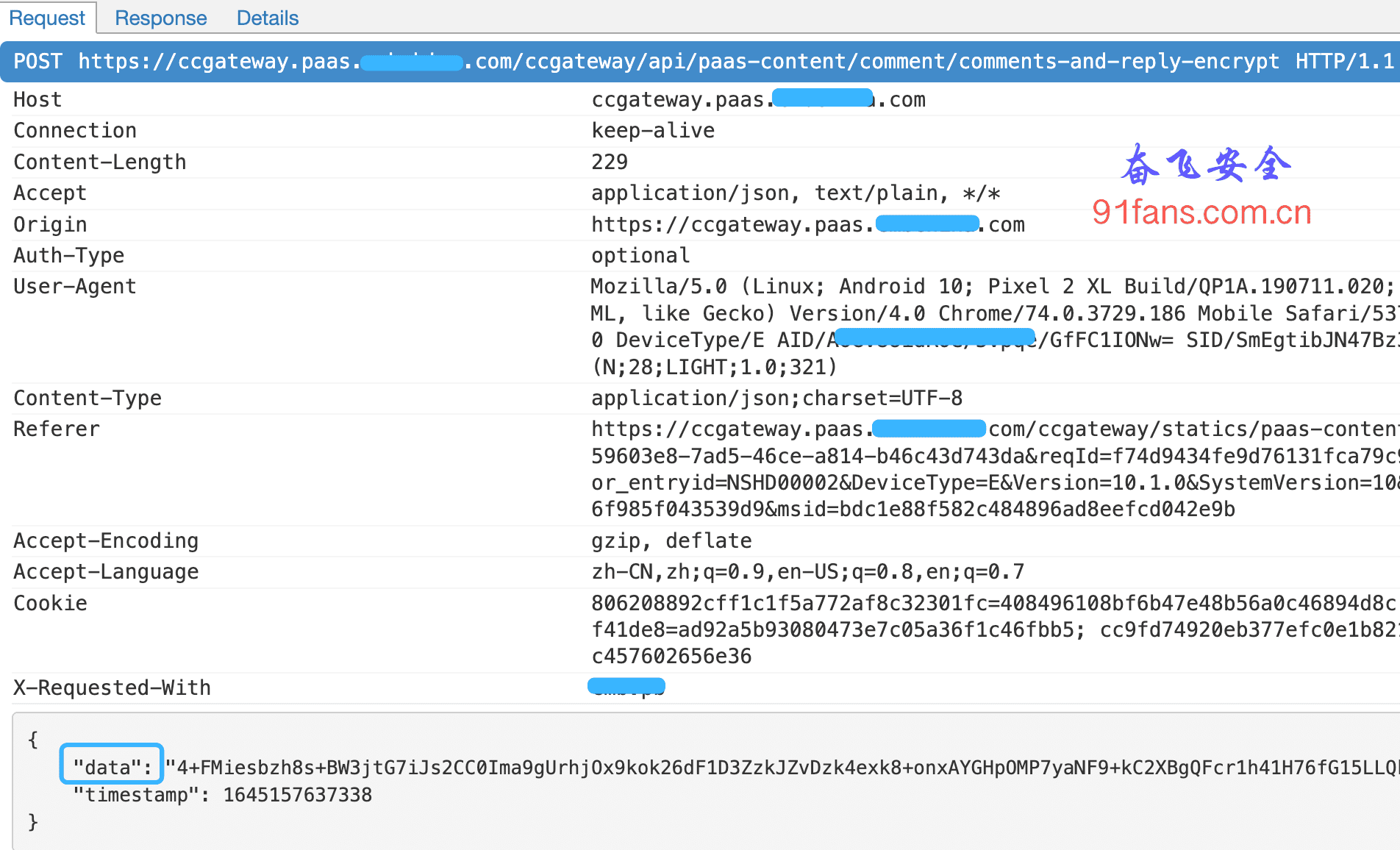
某神奇App data加密算法解析(一)
一、目标李老板:奋飞呀,我遇到一个超级牛掰的App,它请求的时候有个data参数加密,用尽了你介绍的所有的方法,都找不到它是如何加密的。奋飞:子曾经曰过,老板的嘴,骗人的鬼。有这么牛掰的App,那么我们这帮兄弟早就失业了。某神奇Appv10.1.0点社区随便打开一篇有评论的文章今天的目标就是这个data二、步骤搜索特征字符串目标是data,所以我
C_N_Candy
•
4年前
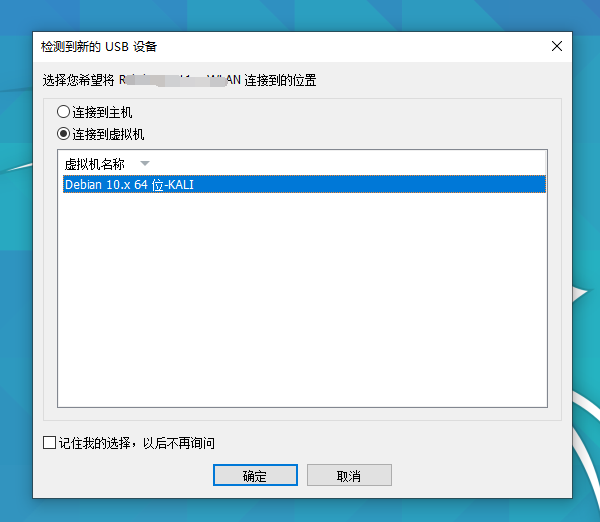
关于WIFI密码破解——握手包(详细图文教程)
前言:新搬的地方还没有安装WIFI,流量手机流量快烧完了,看着附近的WIFI,很是心动。于是上网搜索了一下教程进行试验,试验过程和结果,仅作为学习记录。试验环境:1.台式机2.Kali虚拟机3.无线网卡4.菜鸡一只试验过程:一、无线网卡安排1.主机USB接口直接怼入无线网卡,Kali虚拟机弹窗提示,选择连接到虚拟机,选中Kali,点击确定。(看
Wesley13
•
4年前
java 数据结构(五):数据结构简述
1.数据结构概述数据结构(DataStructure是一门和计算机硬件与软件都密切相关的学科,它的研究重点是在计算机的程序设计领域中探讨如何在计算机中组织和存储数据并进行高效率的运用,涉及的内容包含:数据的逻辑关系、数据的存储结构、排序算法(Algorithm)、查找(或搜索)等。2.数据结构与算法的理解程序能否快速而高效地完成预定的任务,
Wesley13
•
4年前
SEO题记
昨天和好朋友小聚,他最近研究SEO,深受启发。简要总结如下:用一句话独特的话描述你的网站。搜索引擎显示你的网站的时候,只会显示非常短的一句话(约一百多个字符)。要想让别人注意,必须要用一句特别独特、高度概括、并且要非常准确的话来说明你的网站。并作为首页的Title外链尽量多的让外部的网站给你做链接。而且尽量做具有针对
helloworld_83280341
•
3年前
安全私密的聊天系统可免费使用可转让可定制
安全私密的聊天系统可免费使用可转让可定制超级稳定的聊天通信系统可在线免费使用可聊天、红包、转账、超级大群超过20台服务器承载均衡保证超级大群永不丢包,保证不卡顿用过才知好注册超级方便,国内国外均可注册使用,支持充值提现,支持多人语音视频想下载只需appstore搜索“兔八”免费下载使用安卓版本请前往以下地址下载:tuba2007.com对于系统源码和
Stella981
•
4年前
MindManager,818“烧走”拖延症
这是一个关于重度拖延症的故事。2016年底,临近年末各类的总结报告层出不穷,你开始在网上搜索总结报告该怎么写,而大段的文字却看的你头晕脑胀,突然!(http://p3.pstatp.com/large/37c80000d1a0463da383)这样一份年终计划出现了......虽然作为一个重度拖延症,事情能拖一天是一天嘛你还是马上把图
Stella981
•
4年前
Linux
初识vi/vim文本编辑器1.vi和vim相同,都是文本编辑器,在vi模式下可以查看文本,编辑文本,是Linux最常用的命令,vi模式下分为三部分,第一部分一般模式,在一般模式中可以进行搜索字符等按键操作,按下i,o,a任意一个字符就可以进入编辑模式,按ESC回到一般模式,编辑模式下可以对
Stella981
•
4年前
ElasticSearch底层原理浅析
基本概念索引(Index)ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的
想天浏览器
•
3年前
想天浏览器:推荐几款好用的桌面浏览器
1:想天浏览器基于Chromium内核,一款团队协作与浏览器结合的桌面浏览器,支持全局搜索;云端标签分组空间;团队的创建、显示,同步创建一个团队沟通群聊与社区圈子;下载助手;;支持消息中心;标签组管理功能;密码管理功能;用户脚本管理;强大的导航管理;DIY桌面功能等丰富的功能,不仅如此想天浏览器还有很多实用的插件,可以帮助你拦截广告、翻译网页等,为你带来高效
1
•••
74
75
76
•••
81