推荐
专栏
教程
课程
飞鹅
本次共找到4226条
上采样
相关的信息
Souleigh ✨
•
4年前
你可能不知道的 Create React App 的一些技巧
在本文中,我们将探讨提供的鲜为人知但非常有用的功能。让我们开始吧!在HTTPS而不是HTTP上提供应用程序有时我们需要在HTTPS上测试我们的应用程序,以在部署到生产之前检查所有API是否正常工作。Createreactapp提供了一种简单的方法来做到这一点。.env在您的项目文件夹中创建一个(dotenv)文件并HTTPStrue在其
Stella981
•
4年前
Python 使用VS Code进行调试
VSCode是一款非常好用的编辑器,现在我基本上所有的开发任务都在VSCode上完成。它的代码调试工具其实也非常强大,但是许多人都不知道该怎么用,今天就来学习怎么用它调试Python代码吧。1.准备既然是用VSCode调试Python代码,那当然你得先安装好Python啦,如果你还没有安装,可以看这篇文章:超详细Pyt
Stella981
•
4年前
Spring Cloud微服务开发笔记2——Eureka集群搭建
上一篇博文中,我们介绍了如何搭建一个Eureka服务的架构,但是服务提供者我们只用了一个单例,完全不能体现高并发高可用。本文我们尝试在上一篇文章示例Eureka项目的基础上继续完善,让它可以做到一个集群的部署。Eureka集群架构我们先看一下我们这次示例打算改造成的架构图:!(https://static.oschina
Stella981
•
4年前
Android手机GPU真弱
因为要为自己的引擎做跨平台准备,第一准备跨的就是Android,特地用OpenGLES2重写了渲染底层,写了个简单的Demo测试了下性能.显示一个左右走动的帧序列动画精灵(2D)(非骨骼动画),再电脑上同屏30000个无压力(取决于显卡),放到我的2013年旗舰机型的Android4.3机型上,同屏300个就降到了30FPS以下,出现卡顿
Wesley13
•
4年前
Hadoop Streaming 实战: 文件分发与打包
如果程序运行所需要的可执行文件、脚本或者配置文件在Hadoop集群的计算节点上不存在,则首先需要将这些文件分发到集群上才能成功进行计算。Hadoop提供了自动分发文件和压缩包的机制,只需要在启动Streaming作业时配置相应的参数。1\.–file将本地文件分发到计算结点2\.–cacheFile文件已经存放在HDFS中,希望计算时
Easter79
•
4年前
Tensorflow的gRPC编程(一)
首先了解什么叫RPC,为什么要RPC,RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。比如说,一个方法可能是这样定义的:EmployeegetEmployeeByName(StringfullN
Wesley13
•
4年前
Java多线程并发常用类实例之:Condition
作为一个示例,假定有一个绑定的缓冲区,它支持 put 和 take 方法。如果试图在空的缓冲区上执行 take 操作,则在某一个项变得可用之前,线程将一直阻塞;如果试图在满的缓冲区上执行 put 操作,则在有空间变得可用之前,线程将一直阻塞。我们喜欢在单独的等待set中保存 put 线程和 take 线程,这样就可
Easter79
•
4年前
Spring和Mybatis集成,如何批量insert update?以及一些通用Dao的设想
之所以写这篇文章,主要是给新手提供一些mybatis使用的技巧和思路现在国内很多项目都使用了mybatis作为ORM框架我们在实际的使用过程中基本上都会遇到批量insertupdate等操作在网上搜索一些文章,大多数都是在说使用mybatisforEach标签迭代等。。。实际上这种做法是存在很多问题的,比如SQL过长..等限制于是乎我
Stella981
•
4年前
Kubernetes 现终于成熟了,不在是大厂的标配
过去几年,以Docker、Kubernetes为代表的容器技术已发展为一项通用技术,BAT、滴滴、京东、头条等大厂,都争相把容器和K8S项目作为技术重心,试图“放长线钓大鱼”。就说阿里吧,目前基本所有业务都跑在云上,其中有一半已迁移到自己定制Kubernetes集群上。据说,今年计划完成100%基于K8S集群的业务部署。而服务网格这块
GoCoding
•
3年前
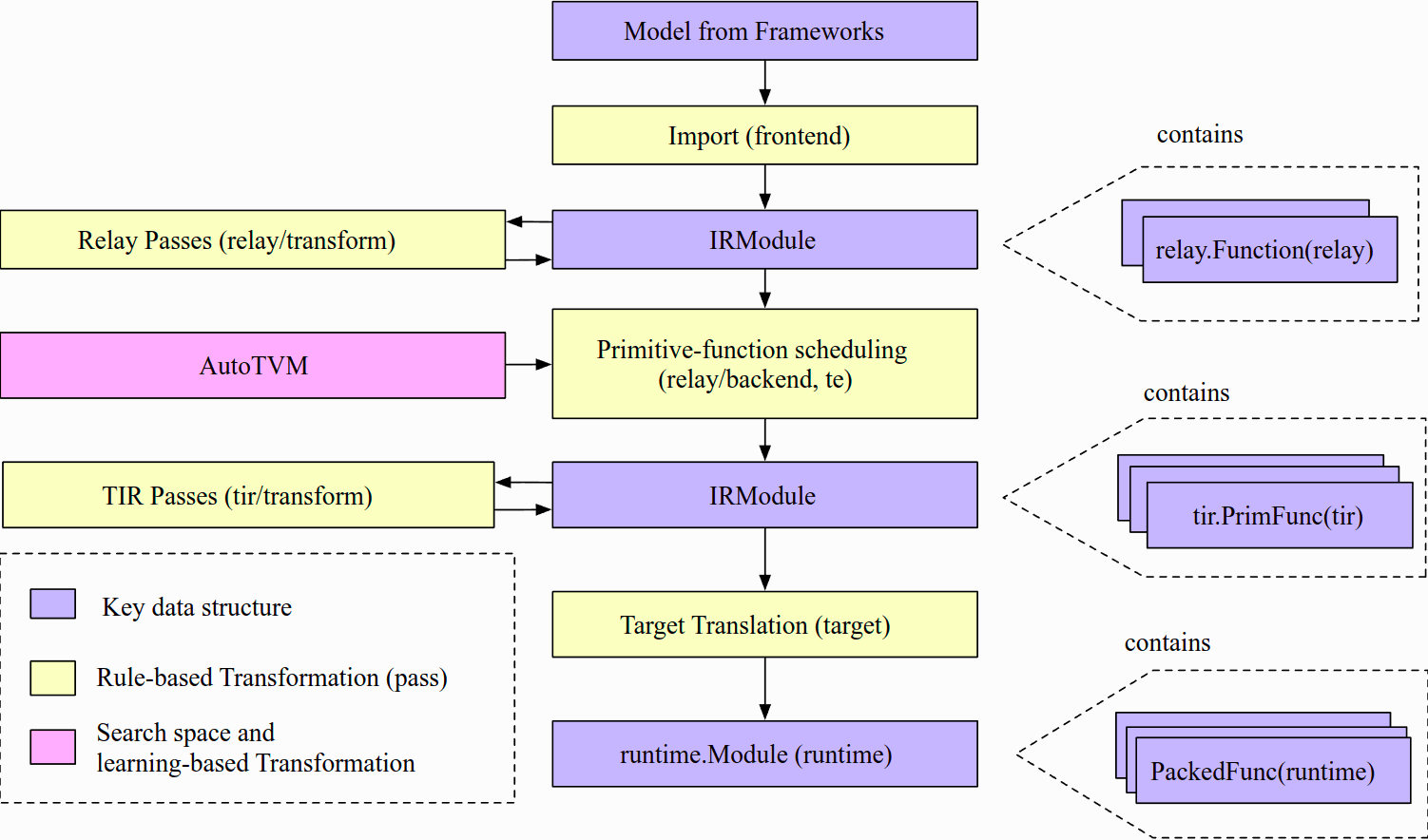
TVM 加速模型,优化推断
TVM是一个开源深度学习编译器,可适用于各类CPUs,GPUs及其他专用加速器。它的目标是使得我们能够在任何硬件上优化和运行自己的模型。不同于深度学习框架关注模型生产力,TVM更关注模型在硬件上的性能和效率。本文只简单介绍TVM的编译流程,及如何自动调优自己的模型。更深入了解,可见TVM官方内容:文档:https://tvm.apach
1
•••
80
81
82
•••
423