
前言:授人以鱼不如授人以渔.先学会用,在学原理,在学创造,可能一辈子用不到这种能力,但是不能不具备这种能力。这篇文章主要是介绍算法入门Helloword之手写图片识别模型java中如何实现以及部分解释。目前大家对于人工智能-机器学习-神经网络的文章都是基于python语言的,对于擅长java的后端小伙伴想要去了解就不是特别友好,所以这里给大家介绍一下如何在java中实现,打开新世界的大门。以下为本人个人理解如有错误欢迎指正
一、目标:使用MNIST数据集训练手写数字图片识别模型
在实现一个模型的时候我们要准备哪些知识体系:
1.机器学习基础:包括监督学习、无监督学习、强化学习等基本概念。
2.数据处理与分析:数据清洗、特征工程、数据可视化等。
3.编程语言:如Python,用于实现机器学习算法。
4.数学基础:线性代数、概率统计、微积分等数学知识。
5.机器学习算法:线性回归、决策树、神经网络、支持向量机等算法。
6.深度学习框架:如TensorFlow、PyTorch等,用于构建和训练深度学习模型。
7.模型评估与优化:交叉验证、超参数调优、模型评估指标等。
8.实践经验:通过实际项目和竞赛积累经验,不断提升模型学习能力。
这里的机器学习HelloWorld是手写图片识别用的是TensorFlow框架
主要需要:
1.理解手写图片的数据集,训练集是什么样的数据(60000,28,28) 、训练集的标签是什么样的(1)
2.理解激活函数的作用
3.正向传递和反向传播的作用以及实现
4.训练模型和保存模型
5.加载保存的模型使用
二、java代码与python代码对比分析
因为python代码解释网上已经有很多了,这里不在重复解释
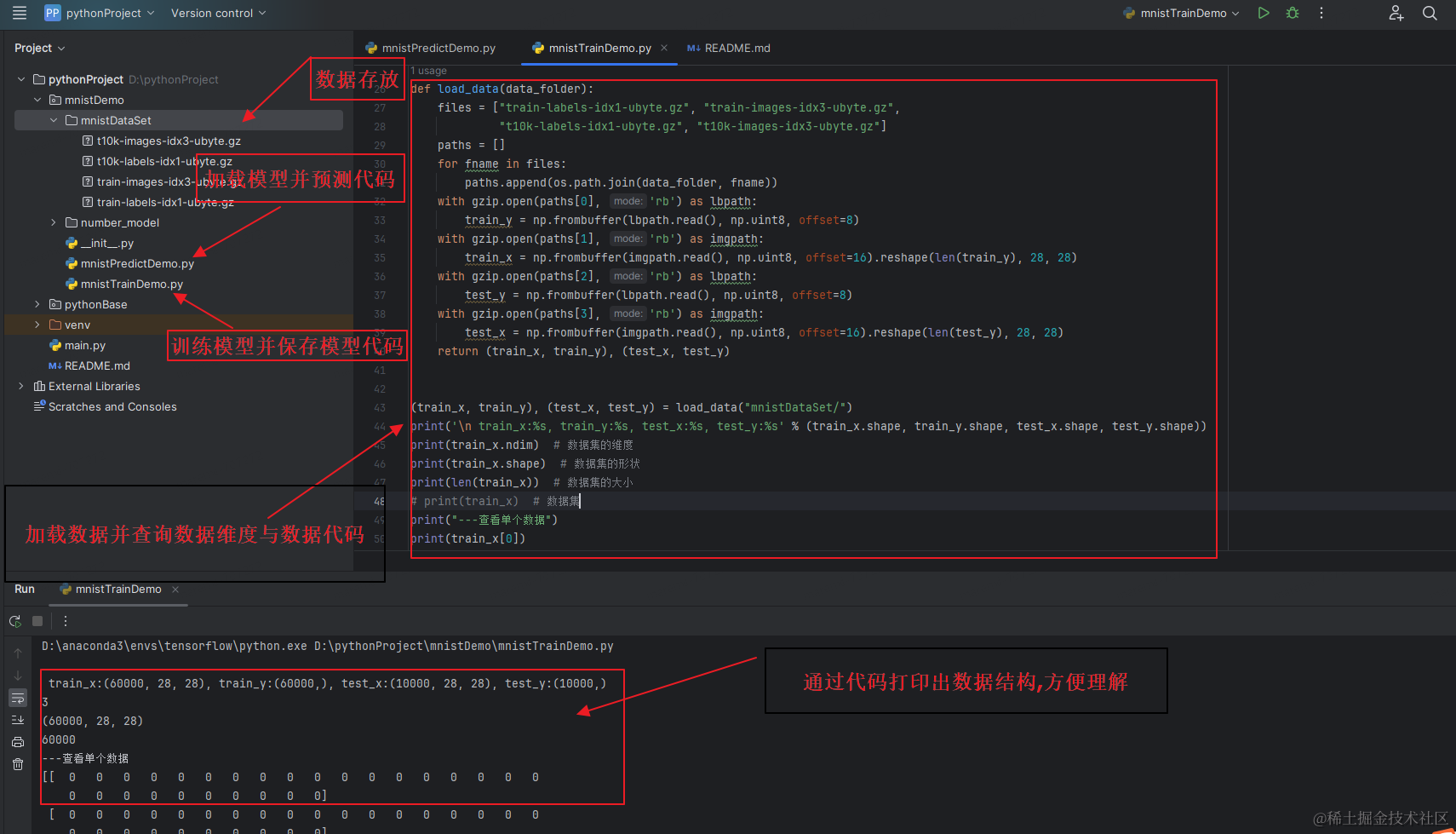
1.数据集的加载
python中
def load_data(dpata_folder):
files = ["train-labels-idx1-ubyte.gz", "train-images-idx3-ubyte.gz",
"t10k-labels-idx1-ubyte.gz", "t10k-images-idx3-ubyte.gz"]
paths = []
for fname in files:
paths.append(os.path.join(data_folder, fname))
with gzip.open(paths[0], 'rb') as lbpath:
train_y = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[1], 'rb') as imgpath:
train_x = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(train_y), 28, 28)
with gzip.open(paths[2], 'rb') as lbpath:
test_y = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[3], 'rb') as imgpath:
test_x = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(test_y), 28, 28)
return (train_x, train_y), (test_x, test_y)
(train_x, train_y), (test_x, test_y) = load_data("mnistDataSet/")
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s' % (train_x.shape, train_y.shape, test_x.shape, test_y.shape))
print(train_x.ndim) # 数据集的维度
print(train_x.shape) # 数据集的形状
print(len(train_x)) # 数据集的大小
print(train_x) # 数据集
print("---查看单个数据")
print(train_x[0])
print(len(train_x[0]))
print(len(train_x[0][1]))
print(train_x[0][6])
print("---查看单个数据")
print(train_y[3])
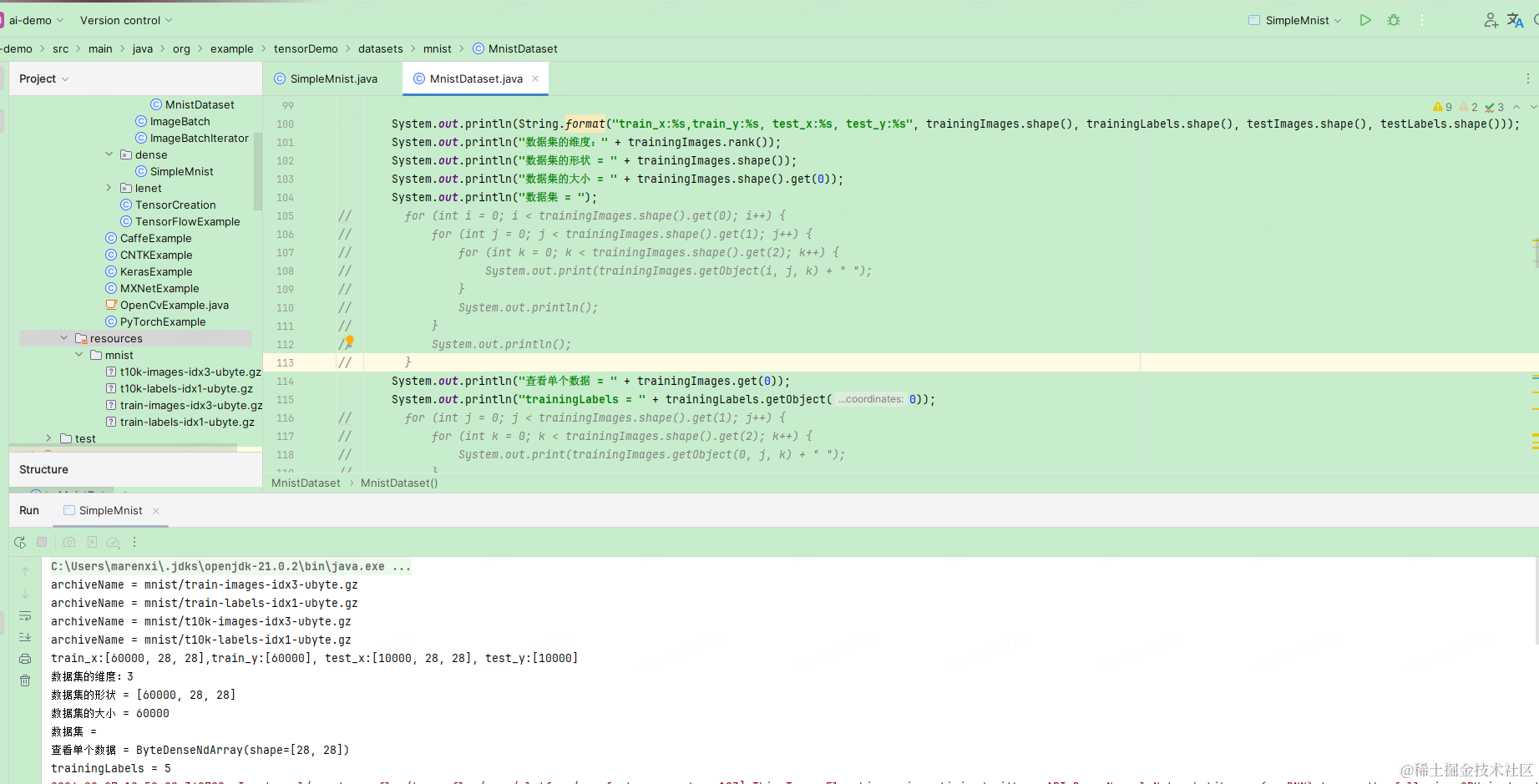
java中
SimpleMnist.class
private static final String TRAINING_IMAGES_ARCHIVE = "mnist/train-images-idx3-ubyte.gz";
private static final String TRAINING_LABELS_ARCHIVE = "mnist/train-labels-idx1-ubyte.gz";
private static final String TEST_IMAGES_ARCHIVE = "mnist/t10k-images-idx3-ubyte.gz";
private static final String TEST_LABELS_ARCHIVE = "mnist/t10k-labels-idx1-ubyte.gz";
//加载数据
MnistDataset validationDataset = MnistDataset.getOneValidationImage(3, TRAINING_IMAGES_ARCHIVE, TRAINING_LABELS_ARCHIVE,TEST_IMAGES_ARCHIVE, TEST_LABELS_ARCHIVE);MnistDataset.class
/**
* @param trainingImagesArchive 训练图片路径
* @param trainingLabelsArchive 训练标签路径
* @param testImagesArchive 测试图片路径
* @param testLabelsArchive 测试标签路径
*/
public static MnistDataset getOneValidationImage(int index, String trainingImagesArchive, String trainingLabelsArchive,String testImagesArchive, String testLabelsArchive) {
try {
ByteNdArray trainingImages = readArchive(trainingImagesArchive);
ByteNdArray trainingLabels = readArchive(trainingLabelsArchive);
ByteNdArray testImages = readArchive(testImagesArchive);
ByteNdArray testLabels = readArchive(testLabelsArchive);
trainingImages.slice(sliceFrom(0));
trainingLabels.slice(sliceTo(0));
// 切片操作
Index range = Indices.range(index, index + 1);// 切片的起始和结束索引
ByteNdArray validationImage = trainingImages.slice(range); // 执行切片操作
ByteNdArray validationLable = trainingLabels.slice(range); // 执行切片操作
if (index >= 0) {
return new MnistDataset(trainingImages,trainingLabels,validationImage,validationLable,testImages,testLabels);
} else {
return null;
}
} catch (IOException e) {
throw new AssertionError(e);
}
}
private static ByteNdArray readArchive(String archiveName) throws IOException {
System.out.println("archiveName = " + archiveName);
DataInputStream archiveStream = new DataInputStream(new GZIPInputStream(MnistDataset.class.getClassLoader().getResourceAsStream(archiveName))
);
archiveStream.readShort(); // first two bytes are always 0
byte magic = archiveStream.readByte();
if (magic != TYPE_UBYTE) {
throw new IllegalArgumentException(""" + archiveName + "" is not a valid archive");
}
int numDims = archiveStream.readByte();
long[] dimSizes = new long[numDims];
int size = 1; // for simplicity, we assume that total size does not exceeds Integer.MAX_VALUE
for (int i = 0; i < dimSizes.length; ++i) {
dimSizes[i] = archiveStream.readInt();
size *= dimSizes[i];
}
byte[] bytes = new byte[size];
archiveStream.readFully(bytes);
return NdArrays.wrap(Shape.of(dimSizes), DataBuffers.of(bytes, false, false));
}
/**
* Mnist 数据集构造器
*/
private MnistDataset(ByteNdArray trainingImages, ByteNdArray trainingLabels,ByteNdArray validationImages,ByteNdArray validationLabels,ByteNdArray testImages,ByteNdArray testLabels
) {
this.trainingImages = trainingImages;
this.trainingLabels = trainingLabels;
this.validationImages = validationImages;
this.validationLabels = validationLabels;
this.testImages = testImages;
this.testLabels = testLabels;
this.imageSize = trainingImages.get(0).shape().size();
System.out.println(String.format("train_x:%s,train_y:%s, test_x:%s, test_y:%s", trainingImages.shape(), trainingLabels.shape(), testImages.shape(), testLabels.shape()));
System.out.println("数据集的维度:" + trainingImages.rank());
System.out.println("数据集的形状 = " + trainingImages.shape());
System.out.println("数据集的大小 = " + trainingImages.shape().get(0));
System.out.println("查看单个数据 = " + trainingImages.get(0));
}
2.模型构建
python中
model = tensorflow.keras.Sequential()
model.add(tensorflow.keras.layers.Flatten(input_shape=(28, 28))) # 添加Flatten层说明输入数据的形状
model.add(tensorflow.keras.layers.Dense(128, activation='relu')) # 添加隐含层,为全连接层,128个节点,relu激活函数
model.add(tensorflow.keras.layers.Dense(10, activation='softmax')) # 添加输出层,为全连接层,10个节点,softmax激活函数
print("打印模型结构")
# 使用 summary 打印模型结构
print('\n', model.summary()) # 查看网络结构和参数信息
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['sparse_categorical_accuracy'])java中
SimpleMnist.class
Ops tf = Ops.create(graph);
// Create placeholders and variables, which should fit batches of an unknown number of images
//创建占位符和变量,这些占位符和变量应适合未知数量的图像批次
Placeholder<TFloat32> images = tf.placeholder(TFloat32.class);
Placeholder<TFloat32> labels = tf.placeholder(TFloat32.class);
// Create weights with an initial value of 0
// 创建初始值为 0 的权重
Shape weightShape = Shape.of(dataset.imageSize(), MnistDataset.NUM_CLASSES);
Variable<TFloat32> weights = tf.variable(tf.zeros(tf.constant(weightShape), TFloat32.class));
// Create biases with an initial value of 0
//创建初始值为 0 的偏置
Shape biasShape = Shape.of(MnistDataset.NUM_CLASSES);
Variable<TFloat32> biases = tf.variable(tf.zeros(tf.constant(biasShape), TFloat32.class));
// Predict the class of each image in the batch and compute the loss
//使用 TensorFlow 的 tf.linalg.matMul 函数计算图像矩阵 images 和权重矩阵 weights 的矩阵乘法,并加上偏置项 biases。
//wx+b
MatMul<TFloat32> matMul = tf.linalg.matMul(images, weights);
Add<TFloat32> add = tf.math.add(matMul, biases);
//Softmax 是一个常用的激活函数,它将输入转换为表示概率分布的输出。对于输入向量中的每个元素,Softmax 函数会计算指数,
//并对所有元素求和,然后将每个元素的指数除以总和,最终得到一个概率分布。这通常用于多分类问题,以输出每个类别的概率
Softmax<TFloat32> softmax = tf.nn.softmax(add);
// 创建一个计算交叉熵的Mean对象
Mean<TFloat32> crossEntropy =
tf.math.mean( // 计算张量的平均值
tf.math.neg( // 计算张量的负值
tf.reduceSum( // 计算张量的和
tf.math.mul(labels, tf.math.log(softmax)), //计算标签和softmax预测的对数乘积
tf.array(1) // 在指定轴上求和
)
),
tf.array(0) // 在指定轴上求平均值
);
// Back-propagate gradients to variables for training
//使用梯度下降优化器来最小化交叉熵损失函数。首先,创建了一个梯度下降优化器 optimizer,然后使用该优化器来最小化交叉熵损失函数 crossEntropy。
Optimizer optimizer = new GradientDescent(graph, LEARNING_RATE);
Op minimize = optimizer.minimize(crossEntropy);3.训练模型
python中
history = model.fit(train_x, train_y, batch_size=64, epochs=5, validation_split=0.2)java中
SimpleMnist.class
// Train the model
for (ImageBatch trainingBatch : dataset.trainingBatches(TRAINING_BATCH_SIZE)) {
try (TFloat32 batchImages = preprocessImages(trainingBatch.images());
TFloat32 batchLabels = preprocessLabels(trainingBatch.labels())) {
// 创建会话运行器
session.runner()
// 添加要最小化的目标
.addTarget(minimize)
// 通过feed方法将图像数据输入到模型中
.feed(images.asOutput(), batchImages)
// 通过feed方法将标签数据输入到模型中
.feed(labels.asOutput(), batchLabels)
// 运行会话
.run();
}
}4.模型评估
python中
test_loss, test_acc = model.evaluate(test_x, test_y)
model.evaluate(test_x, test_y, verbose=2) # 每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力
print('Test 损失: %.3f' % test_loss)
print('Test 精确度: %.3f' % test_acc)java中
SimpleMnist.class
// Test the model
ImageBatch testBatch = dataset.testBatch();
try (TFloat32 testImages = preprocessImages(testBatch.images());
TFloat32 testLabels = preprocessLabels(testBatch.labels());
// 定义一个TFloat32类型的变量accuracyValue,用于存储计算得到的准确率值
TFloat32 accuracyValue = (TFloat32) session.runner()
// 从会话中获取准确率值
.fetch(accuracy)
.fetch(predicted)
.fetch(expected)
// 将images作为输入,testImages作为数据进行喂养
.feed(images.asOutput(), testImages)
// 将labels作为输入,testLabels作为数据进行喂养
.feed(labels.asOutput(), testLabels)
// 运行会话并获取结果
.run()
// 获取第一个结果并存储在accuracyValue中
.get(0)) {
System.out.println("Accuracy: " + accuracyValue.getFloat());
}5.保存模型
python中
# 使用save_model保存完整模型
# save_model(model, '/media/cfs/用户ERP名称/ea/saved_model', save_format='pb')
save_model(model, 'D:\pythonProject\mnistDemo\number_model', save_format='pb')java中
SimpleMnist.class
// 保存模型
SavedModelBundle.Exporter exporter = SavedModelBundle.exporter("D:\ai\ai-demo").withSession(session);
Signature.Builder builder = Signature.builder();
builder.input("images", images);
builder.input("labels", labels);
builder.output("accuracy", accuracy);
builder.output("expected", expected);
builder.output("predicted", predicted);
Signature signature = builder.build();
SessionFunction sessionFunction = SessionFunction.create(signature, session);
exporter.withFunction(sessionFunction);
exporter.export();6.加载模型
python中
# 加载.pb模型文件
global load_model
load_model = load_model('D:\pythonProject\mnistDemo\number_model')
load_model.summary()
demo = tensorflow.reshape(test_x, (1, 28, 28))
input_data = np.array(demo) # 准备你的输入数据
input_data = tensorflow.convert_to_tensor(input_data, dtype=tensorflow.float32)
predictValue = load_model.predict(input_data)
print("predictValue")
print(predictValue)
y_pred = np.argmax(predictValue)
print('标签值:' + str(test_y) + '\n预测值:' + str(y_pred))
return y_pred, test_y,java中
SimpleMnist.class
//加载模型并预测
public void loadModel(String exportDir) {
// load saved model
SavedModelBundle model = SavedModelBundle.load(exportDir, "serve");
try {
printSignature(model);
} catch (Exception e) {
throw new RuntimeException(e);
}
ByteNdArray validationImages = dataset.getValidationImages();
ByteNdArray validationLabels = dataset.getValidationLabels();
TFloat32 testImages = preprocessImages(validationImages);
System.out.println("testImages = " + testImages.shape());
TFloat32 testLabels = preprocessLabels(validationLabels);
System.out.println("testLabels = " + testLabels.shape());
Result run = model.session().runner()
.feed("Placeholder:0", testImages)
.feed("Placeholder_1:0", testLabels)
.fetch("ArgMax:0")
.fetch("ArgMax_1:0")
.fetch("Mean_1:0")
.run();
// 处理输出
Optional<Tensor> tensor1 = run.get("ArgMax:0");
Optional<Tensor> tensor2 = run.get("ArgMax_1:0");
Optional<Tensor> tensor3 = run.get("Mean_1:0");
TInt64 predicted = (TInt64) tensor1.get();
Long predictedValue = predicted.getObject(0);
System.out.println("predictedValue = " + predictedValue);
TInt64 expected = (TInt64) tensor2.get();
Long expectedValue = expected.getObject(0);
System.out.println("expectedValue = " + expectedValue);
TFloat32 accuracy = (TFloat32) tensor3.get();
System.out.println("accuracy = " + accuracy.getFloat());
}
//打印模型信息
private static void printSignature(SavedModelBundle model) throws Exception {
MetaGraphDef m = model.metaGraphDef();
SignatureDef sig = m.getSignatureDefOrThrow("serving_default");
int numInputs = sig.getInputsCount();
int i = 1;
System.out.println("MODEL SIGNATURE");
System.out.println("Inputs:");
for (Map.Entry<String, TensorInfo> entry : sig.getInputsMap().entrySet()) {
TensorInfo t = entry.getValue();
System.out.printf(
"%d of %d: %-20s (Node name in graph: %-20s, type: %s)\n",
i++, numInputs, entry.getKey(), t.getName(), t.getDtype());
}
int numOutputs = sig.getOutputsCount();
i = 1;
System.out.println("Outputs:");
for (Map.Entry<String, TensorInfo> entry : sig.getOutputsMap().entrySet()) {
TensorInfo t = entry.getValue();
System.out.printf(
"%d of %d: %-20s (Node name in graph: %-20s, type: %s)\n",
i++, numOutputs, entry.getKey(), t.getName(), t.getDtype());
}
}三、完整的python代码
本工程使用环境为
Python: 3.7.9
https://www.python.org/downloads/windows/
Anaconda: Python 3.11 Anaconda3-2023.09-0-Windows-x86_64
https://www.anaconda.com/download#downloads
tensorflow:2.0.0
直接从anaconda下安装
mnistTrainDemo.py
import gzip
import os.path
import tensorflow as tensorflow
from tensorflow import keras
# 可视化 image
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.models import save_model
# 加载数据
# mnist = keras.datasets.mnist
# mnistData = mnist.load_data() #Exception: URL fetch failure on https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz: None -- unknown url type: https
"""
这里可以直接使用
mnist = keras.datasets.mnist
mnistData = mnist.load_data() 加载数据,但是有的时候不成功,所以使用本地加载数据
"""
def load_data(data_folder):
files = ["train-labels-idx1-ubyte.gz", "train-images-idx3-ubyte.gz",
"t10k-labels-idx1-ubyte.gz", "t10k-images-idx3-ubyte.gz"]
paths = []
for fname in files:
paths.append(os.path.join(data_folder, fname))
with gzip.open(paths[0], 'rb') as lbpath:
train_y = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[1], 'rb') as imgpath:
train_x = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(train_y), 28, 28)
with gzip.open(paths[2], 'rb') as lbpath:
test_y = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[3], 'rb') as imgpath:
test_x = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(test_y), 28, 28)
return (train_x, train_y), (test_x, test_y)
(train_x, train_y), (test_x, test_y) = load_data("mnistDataSet/")
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s' % (train_x.shape, train_y.shape, test_x.shape, test_y.shape))
print(train_x.ndim) # 数据集的维度
print(train_x.shape) # 数据集的形状
print(len(train_x)) # 数据集的大小
print(train_x) # 数据集
print("---查看单个数据")
print(train_x[0])
print(len(train_x[0]))
print(len(train_x[0][1]))
print(train_x[0][6])
# 可视化image图片、一副image的数据
# plt.imshow(train_x[0].reshape(28, 28), cmap="binary")
# plt.show()
print("---查看单个数据")
print(train_y[0])
# 数据预处理
# 归一化、并转换为tensor张量,数据类型为float32. ---归一化也可能造成识别率低
# train_x, test_x = tensorflow.cast(train_x / 255.0, tensorflow.float32), tensorflow.cast(test_x / 255.0,
# tensorflow.float32),
# train_y, test_y = tensorflow.cast(train_y, tensorflow.int16), tensorflow.cast(test_y, tensorflow.int16)
# print("---查看单个数据归一后的数据")
# print(train_x[0][6]) # 30/255=0.11764706 ---归一化每个值除以255
# print(train_y[0])
# Step2: 配置网络 建立模型
'''
以下的代码判断就是定义一个简单的多层感知器,一共有三层,
两个大小为100的隐层和一个大小为10的输出层,因为MNIST数据集是手写0到9的灰度图像,
类别有10个,所以最后的输出大小是10。最后输出层的激活函数是Softmax,
所以最后的输出层相当于一个分类器。加上一个输入层的话,
多层感知器的结构是:输入层-->>隐层-->>隐层-->>输出层。
激活函数 https://zhuanlan.zhihu.com/p/337902763
'''
# 构造模型
# model = keras.Sequential([
# # 在第一层的网络中,我们的输入形状是28*28,这里的形状就是图片的长度和宽度。
# keras.layers.Flatten(input_shape=(28, 28)),
# # 所以神经网络有点像滤波器(过滤装置),输入一组28*28像素的图片后,输出10个类别的判断结果。那这个128的数字是做什么用的呢?
# # 我们可以这样想象,神经网络中有128个函数,每个函数都有自己的参数。
# # 我们给这些函数进行一个编号,f0,f1…f127 ,我们想的是当图片的像素一一带入这128个函数后,这些函数的组合最终输出一个标签值,在这个样例中,我们希望它输出09 。
# # 为了得到这个结果,计算机必须要搞清楚这128个函数的具体参数,之后才能计算各个图片的标签。这里的逻辑是,一旦计算机搞清楚了这些参数,那它就能够认出不同的10个类别的事物了。
# keras.layers.Dense(100, activation=tensorflow.nn.relu),
# # 最后一层是10,是数据集中各种类别的代号,数据集总共有10类,这里就是10 。
# keras.layers.Dense(10, activation=tensorflow.nn.softmax)
# ])
model = tensorflow.keras.Sequential()
model.add(tensorflow.keras.layers.Flatten(input_shape=(28, 28))) # 添加Flatten层说明输入数据的形状
model.add(tensorflow.keras.layers.Dense(128, activation='relu')) # 添加隐含层,为全连接层,128个节点,relu激活函数
model.add(tensorflow.keras.layers.Dense(10, activation='softmax')) # 添加输出层,为全连接层,10个节点,softmax激活函数
print("打印模型结构")
# 使用 summary 打印模型结构
# print(model.summary())
print('\n', model.summary()) # 查看网络结构和参数信息
'''
接着是配置模型,在这一步,我们需要指定模型训练时所使用的优化算法与损失函数,
此外,这里我们也可以定义计算精度相关的API。
优化器https://zhuanlan.zhihu.com/p/27449596
'''
# 配置模型 配置模型训练方法
# 设置神经网络的优化器和损失函数。# 使用Adam算法进行优化 # 使用CrossEntropyLoss 计算损失 # 使用Accuracy 计算精度
# model.compile(optimizer=tensorflow.optimizers.Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# adam算法参数采用keras默认的公开参数,损失函数采用稀疏交叉熵损失函数,准确率采用稀疏分类准确率函数
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['sparse_categorical_accuracy'])
# Step3:模型训练
# 开始模型训练
# model.fit(x_train, # 设置训练数据集
# y_train,
# epochs=5, # 设置训练轮数
# batch_size=64, # 设置 batch_size
# verbose=1) # 设置日志打印格式
# 批量训练大小为64,迭代5次,测试集比例0.2(48000条训练集数据,12000条测试集数据)
history = model.fit(train_x, train_y, batch_size=64, epochs=5, validation_split=0.2)
# STEP4: 模型评估
# 评估模型,不输出预测结果输出损失和精确度. test_loss损失,test_acc精确度
test_loss, test_acc = model.evaluate(test_x, test_y)
model.evaluate(test_x, test_y, verbose=2) # 每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力
# model.evaluate(test_dataset, verbose=1)
print('Test 损失: %.3f' % test_loss)
print('Test 精确度: %.3f' % test_acc)
# 结果可视化
print(history.history)
loss = history.history['loss'] # 训练集损失
val_loss = history.history['val_loss'] # 测试集损失
acc = history.history['sparse_categorical_accuracy'] # 训练集准确率
val_acc = history.history['val_sparse_categorical_accuracy'] # 测试集准确率
plt.figure(figsize=(10, 3))
plt.subplot(121)
plt.plot(loss, color='b', label='train')
plt.plot(val_loss, color='r', label='test')
plt.ylabel('loss')
plt.legend()
plt.subplot(122)
plt.plot(acc, color='b', label='train')
plt.plot(val_acc, color='r', label='test')
plt.ylabel('Accuracy')
plt.legend()
# 暂停5秒关闭画布,否则画布一直打开的同时,会持续占用GPU内存
# plt.ion() # 打开交互式操作模式
# plt.show()
# plt.pause(5)
# plt.close()
# plt.show()
# Step5:模型预测 输入测试数据,输出预测结果
for i in range(1):
num = np.random.randint(1, 10000) # 在1~10000之间生成随机整数
plt.subplot(2, 5, i + 1)
plt.axis('off')
plt.imshow(test_x[num], cmap='gray')
demo = tensorflow.reshape(test_x[num], (1, 28, 28))
y_pred = np.argmax(model.predict(demo))
plt.title('标签值:' + str(test_y[num]) + '\n预测值:' + str(y_pred))
# plt.show()
'''
保存模型
训练好的模型可以用于加载后对新输入数据进行预测,所以需要先进行保存已训练模型
'''
#使用save_model保存完整模型
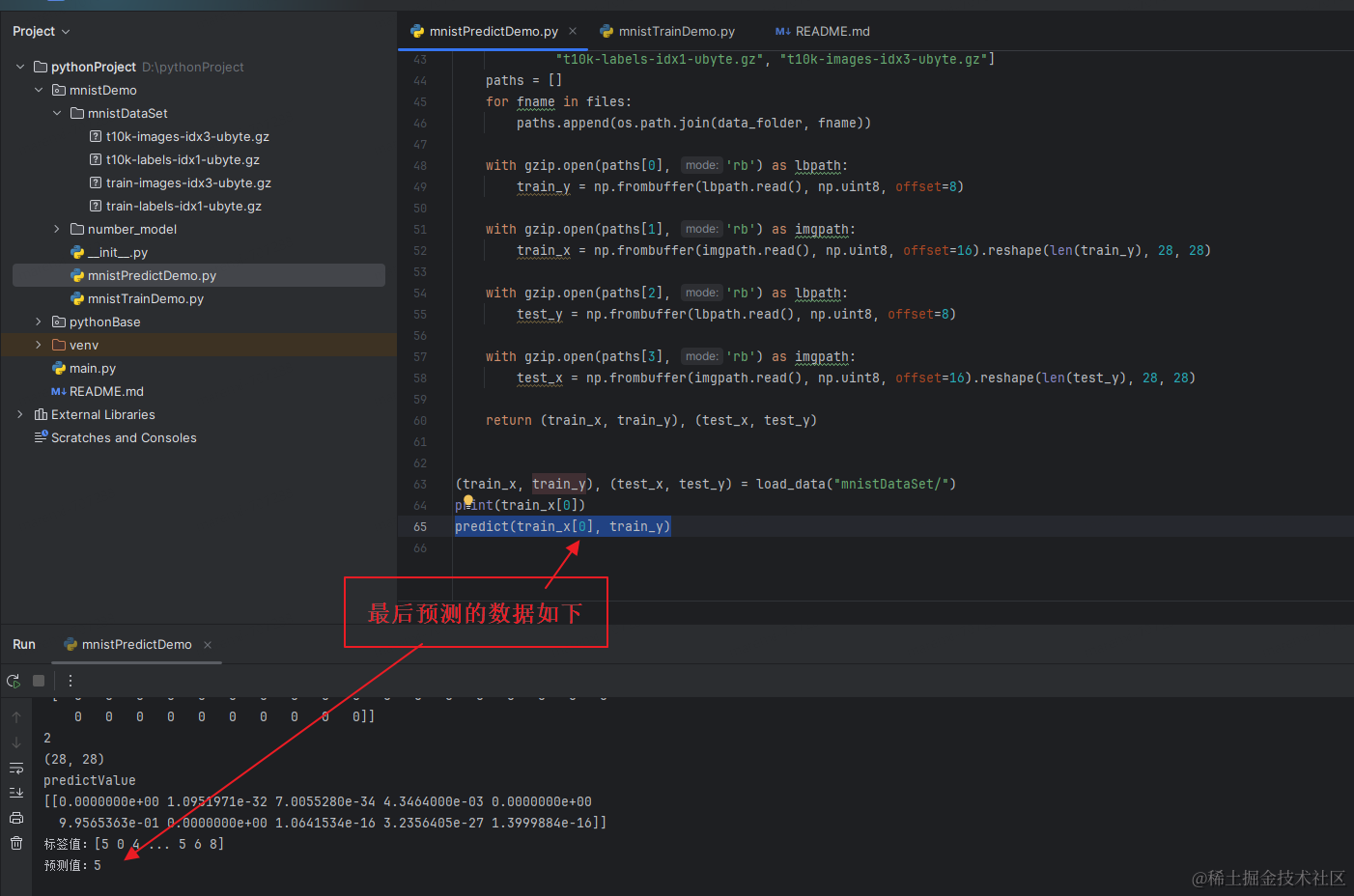
save_model(model, 'D:\pythonProject\mnistDemo\number_model', save_format='pb')mnistPredictDemo.py
import numpy as np
import tensorflow as tensorflow
import gzip
import os.path
from tensorflow.keras.models import load_model
# 预测
def predict(test_x, test_y):
test_x, test_y = test_x, test_y
'''
五、模型评估
需要先加载已训练模型,然后用其预测新的数据,计算评估指标
'''
# 模型加载
# 加载.pb模型文件
global load_model
# load_model = load_model('./saved_model')
load_model = load_model('D:\pythonProject\mnistDemo\number_model')
load_model.summary()
# make a prediction
print("test_x")
print(test_x)
print(test_x.ndim)
print(test_x.shape)
demo = tensorflow.reshape(test_x, (1, 28, 28))
input_data = np.array(demo) # 准备你的输入数据
input_data = tensorflow.convert_to_tensor(input_data, dtype=tensorflow.float32)
# test_x = tensorflow.cast(test_x / 255.0, tensorflow.float32)
# test_y = tensorflow.cast(test_y, tensorflow.int16)
predictValue = load_model.predict(input_data)
print("predictValue")
print(predictValue)
y_pred = np.argmax(predictValue)
print('标签值:' + str(test_y) + '\n预测值:' + str(y_pred))
return y_pred, test_y,
def load_data(data_folder):
files = ["train-labels-idx1-ubyte.gz", "train-images-idx3-ubyte.gz",
"t10k-labels-idx1-ubyte.gz", "t10k-images-idx3-ubyte.gz"]
paths = []
for fname in files:
paths.append(os.path.join(data_folder, fname))
with gzip.open(paths[0], 'rb') as lbpath:
train_y = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[1], 'rb') as imgpath:
train_x = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(train_y), 28, 28)
with gzip.open(paths[2], 'rb') as lbpath:
test_y = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[3], 'rb') as imgpath:
test_x = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(test_y), 28, 28)
return (train_x, train_y), (test_x, test_y)
(train_x, train_y), (test_x, test_y) = load_data("mnistDataSet/")
print(train_x[0])
predict(train_x[0], train_y)四、完整的java代码
tensorflow 需要的java 版本对应表: https://github.com/tensorflow/java/#tensorflow-version-support
本工程使用环境为
jdk版本:openjdk-21
pom依赖如下:
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow-core-platform</artifactId>
<version>0.6.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow-framework</artifactId>
<version>0.6.0-SNAPSHOT</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>tensorflow-snapshots</id>
<url>https://oss.sonatype.org/content/repositories/snapshots/</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>数据集创建和解析类
MnistDataset.class
package org.example.tensorDemo.datasets.mnist;
import org.example.tensorDemo.datasets.ImageBatch;
import org.example.tensorDemo.datasets.ImageBatchIterator;
import org.tensorflow.ndarray.*;
import org.tensorflow.ndarray.buffer.DataBuffers;
import org.tensorflow.ndarray.index.Index;
import org.tensorflow.ndarray.index.Indices;
import java.io.DataInputStream;
import java.io.IOException;
import java.util.zip.GZIPInputStream;
import static org.tensorflow.ndarray.index.Indices.sliceFrom;
import static org.tensorflow.ndarray.index.Indices.sliceTo;
public class MnistDataset {
public static final int NUM_CLASSES = 10;
private static final int TYPE_UBYTE = 0x08;
/**
* 训练图片字节类型的多维数组
*/
private final ByteNdArray trainingImages;
/**
* 训练标签字节类型的多维数组
*/
private final ByteNdArray trainingLabels;
/**
* 验证图片字节类型的多维数组
*/
public final ByteNdArray validationImages;
/**
* 验证标签字节类型的多维数组
*/
public final ByteNdArray validationLabels;
/**
* 测试图片字节类型的多维数组
*/
private final ByteNdArray testImages;
/**
* 测试标签字节类型的多维数组
*/
private final ByteNdArray testLabels;
/**
* 图片的大小
*/
private final long imageSize;
/**
* Mnist 数据集构造器
*/
private MnistDataset(
ByteNdArray trainingImages,
ByteNdArray trainingLabels,
ByteNdArray validationImages,
ByteNdArray validationLabels,
ByteNdArray testImages,
ByteNdArray testLabels
) {
this.trainingImages = trainingImages;
this.trainingLabels = trainingLabels;
this.validationImages = validationImages;
this.validationLabels = validationLabels;
this.testImages = testImages;
this.testLabels = testLabels;
//第一个图像的形状,并返回其尺寸大小。每一张图片包含28X28个像素点 所以应该为784
this.imageSize = trainingImages.get(0).shape().size();
// System.out.println("imageSize = " + imageSize);
// System.out.println(String.format("train_x:%s,train_y:%s, test_x:%s, test_y:%s", trainingImages.shape(), trainingLabels.shape(), testImages.shape(), testLabels.shape()));
// System.out.println("数据集的维度:" + trainingImages.rank());
// System.out.println("数据集的形状 = " + trainingImages.shape());
// System.out.println("数据集的大小 = " + trainingImages.shape().get(0));
// System.out.println("数据集 = ");
// for (int i = 0; i < trainingImages.shape().get(0); i++) {
// for (int j = 0; j < trainingImages.shape().get(1); j++) {
// for (int k = 0; k < trainingImages.shape().get(2); k++) {
// System.out.print(trainingImages.getObject(i, j, k) + " ");
// }
// System.out.println();
// }
// System.out.println();
// }
// System.out.println("查看单个数据 = " + trainingImages.get(0));
// for (int j = 0; j < trainingImages.shape().get(1); j++) {
// for (int k = 0; k < trainingImages.shape().get(2); k++) {
// System.out.print(trainingImages.getObject(0, j, k) + " ");
// }
// System.out.println();
// }
// System.out.println("查看单个数据大小 = " + trainingImages.get(0).size());
// System.out.println("查看trainingImages三维数组下的第一个元素的第二个二维数组大小 = " + trainingImages.get(0).get(1).size());
// System.out.println("查看trainingImages三维数组下的第一个元素的第7个二维数组的第8个元素 = " + trainingImages.getObject(0, 6, 8));
// System.out.println("trainingLabels = " + trainingLabels.getObject(1));
}
/**
* @param validationSize 验证的数据
* @param trainingImagesArchive 训练图片路径
* @param trainingLabelsArchive 训练标签路径
* @param testImagesArchive 测试图片路径
* @param testLabelsArchive 测试标签路径
*/
public static MnistDataset create(int validationSize, String trainingImagesArchive, String trainingLabelsArchive,
String testImagesArchive, String testLabelsArchive) {
try {
ByteNdArray trainingImages = readArchive(trainingImagesArchive);
ByteNdArray trainingLabels = readArchive(trainingLabelsArchive);
ByteNdArray testImages = readArchive(testImagesArchive);
ByteNdArray testLabels = readArchive(testLabelsArchive);
if (validationSize > 0) {
return new MnistDataset(
trainingImages.slice(sliceFrom(validationSize)),
trainingLabels.slice(sliceFrom(validationSize)),
trainingImages.slice(sliceTo(validationSize)),
trainingLabels.slice(sliceTo(validationSize)),
testImages,
testLabels
);
}
return new MnistDataset(trainingImages, trainingLabels, null, null, testImages, testLabels);
} catch (IOException e) {
throw new AssertionError(e);
}
}
/**
* @param trainingImagesArchive 训练图片路径
* @param trainingLabelsArchive 训练标签路径
* @param testImagesArchive 测试图片路径
* @param testLabelsArchive 测试标签路径
*/
public static MnistDataset getOneValidationImage(int index, String trainingImagesArchive, String trainingLabelsArchive,
String testImagesArchive, String testLabelsArchive) {
try {
ByteNdArray trainingImages = readArchive(trainingImagesArchive);
ByteNdArray trainingLabels = readArchive(trainingLabelsArchive);
ByteNdArray testImages = readArchive(testImagesArchive);
ByteNdArray testLabels = readArchive(testLabelsArchive);
trainingImages.slice(sliceFrom(0));
trainingLabels.slice(sliceTo(0));
// 切片操作
Index range = Indices.range(index, index + 1);// 切片的起始和结束索引
ByteNdArray validationImage = trainingImages.slice(range); // 执行切片操作
ByteNdArray validationLable = trainingLabels.slice(range); // 执行切片操作
if (index >= 0) {
return new MnistDataset(
trainingImages,
trainingLabels,
validationImage,
validationLable,
testImages,
testLabels
);
} else {
return null;
}
} catch (IOException e) {
throw new AssertionError(e);
}
}
private static ByteNdArray readArchive(String archiveName) throws IOException {
System.out.println("archiveName = " + archiveName);
DataInputStream archiveStream = new DataInputStream(
//new GZIPInputStream(new java.io.FileInputStream("src/main/resources/"+archiveName))
new GZIPInputStream(MnistDataset.class.getClassLoader().getResourceAsStream(archiveName))
);
//todo 不知道怎么读取和实际的内部结构
archiveStream.readShort(); // first two bytes are always 0
byte magic = archiveStream.readByte();
if (magic != TYPE_UBYTE) {
throw new IllegalArgumentException(""" + archiveName + "" is not a valid archive");
}
int numDims = archiveStream.readByte();
long[] dimSizes = new long[numDims];
int size = 1; // for simplicity, we assume that total size does not exceeds Integer.MAX_VALUE
for (int i = 0; i < dimSizes.length; ++i) {
dimSizes[i] = archiveStream.readInt();
size *= dimSizes[i];
}
byte[] bytes = new byte[size];
archiveStream.readFully(bytes);
return NdArrays.wrap(Shape.of(dimSizes), DataBuffers.of(bytes, false, false));
}
public Iterable<ImageBatch> trainingBatches(int batchSize) {
return () -> new ImageBatchIterator(batchSize, trainingImages, trainingLabels);
}
public Iterable<ImageBatch> validationBatches(int batchSize) {
return () -> new ImageBatchIterator(batchSize, validationImages, validationLabels);
}
public Iterable<ImageBatch> testBatches(int batchSize) {
return () -> new ImageBatchIterator(batchSize, testImages, testLabels);
}
public ImageBatch testBatch() {
return new ImageBatch(testImages, testLabels);
}
public long imageSize() {
return imageSize;
}
public long numTrainingExamples() {
return trainingLabels.shape().size(0);
}
public long numTestingExamples() {
return testLabels.shape().size(0);
}
public long numValidationExamples() {
return validationLabels.shape().size(0);
}
public ByteNdArray getValidationImages() {
return validationImages;
}
public ByteNdArray getValidationLabels() {
return validationLabels;
}
}SimpleMnist.class
package org.example.tensorDemo.dense;
import org.example.tensorDemo.datasets.ImageBatch;
import org.example.tensorDemo.datasets.mnist.MnistDataset;
import org.tensorflow.*;
import org.tensorflow.framework.optimizers.GradientDescent;
import org.tensorflow.framework.optimizers.Optimizer;
import org.tensorflow.ndarray.ByteNdArray;
import org.tensorflow.ndarray.Shape;
import org.tensorflow.op.Op;
import org.tensorflow.op.Ops;
import org.tensorflow.op.core.Placeholder;
import org.tensorflow.op.core.Variable;
import org.tensorflow.op.linalg.MatMul;
import org.tensorflow.op.math.Add;
import org.tensorflow.op.math.Mean;
import org.tensorflow.op.nn.Softmax;
import org.tensorflow.proto.framework.MetaGraphDef;
import org.tensorflow.proto.framework.SignatureDef;
import org.tensorflow.proto.framework.TensorInfo;
import org.tensorflow.types.TFloat32;
import org.tensorflow.types.TInt64;
import java.io.IOException;
import java.util.Map;
import java.util.Optional;
public class SimpleMnist implements Runnable {
private static final String TRAINING_IMAGES_ARCHIVE = "mnist/train-images-idx3-ubyte.gz";
private static final String TRAINING_LABELS_ARCHIVE = "mnist/train-labels-idx1-ubyte.gz";
private static final String TEST_IMAGES_ARCHIVE = "mnist/t10k-images-idx3-ubyte.gz";
private static final String TEST_LABELS_ARCHIVE = "mnist/t10k-labels-idx1-ubyte.gz";
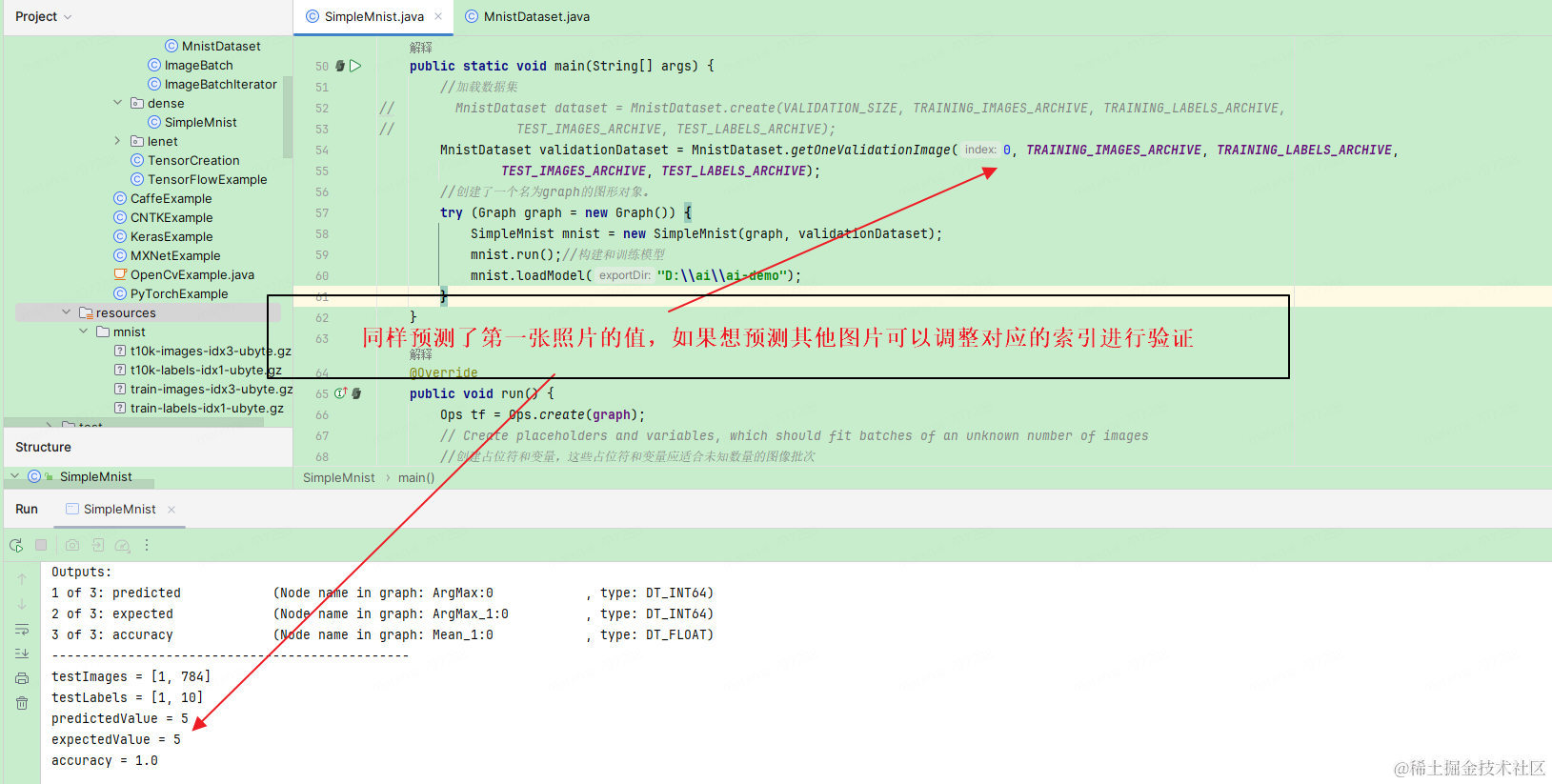
public static void main(String[] args) {
//加载数据集
// MnistDataset dataset = MnistDataset.create(VALIDATION_SIZE, TRAINING_IMAGES_ARCHIVE, TRAINING_LABELS_ARCHIVE,
// TEST_IMAGES_ARCHIVE, TEST_LABELS_ARCHIVE);
MnistDataset validationDataset = MnistDataset.getOneValidationImage(3, TRAINING_IMAGES_ARCHIVE, TRAINING_LABELS_ARCHIVE,
TEST_IMAGES_ARCHIVE, TEST_LABELS_ARCHIVE);
//创建了一个名为graph的图形对象。
try (Graph graph = new Graph()) {
SimpleMnist mnist = new SimpleMnist(graph, validationDataset);
mnist.run();//构建和训练模型
mnist.loadModel("D:\ai\ai-demo");
}
}
@Override
public void run() {
Ops tf = Ops.create(graph);
// Create placeholders and variables, which should fit batches of an unknown number of images
//创建占位符和变量,这些占位符和变量应适合未知数量的图像批次
Placeholder<TFloat32> images = tf.placeholder(TFloat32.class);
Placeholder<TFloat32> labels = tf.placeholder(TFloat32.class);
// Create weights with an initial value of 0
// 创建初始值为 0 的权重
Shape weightShape = Shape.of(dataset.imageSize(), MnistDataset.NUM_CLASSES);
Variable<TFloat32> weights = tf.variable(tf.zeros(tf.constant(weightShape), TFloat32.class));
// Create biases with an initial value of 0
//创建初始值为 0 的偏置
Shape biasShape = Shape.of(MnistDataset.NUM_CLASSES);
Variable<TFloat32> biases = tf.variable(tf.zeros(tf.constant(biasShape), TFloat32.class));
// Predict the class of each image in the batch and compute the loss
//使用 TensorFlow 的 tf.linalg.matMul 函数计算图像矩阵 images 和权重矩阵 weights 的矩阵乘法,并加上偏置项 biases。
//wx+b
MatMul<TFloat32> matMul = tf.linalg.matMul(images, weights);
Add<TFloat32> add = tf.math.add(matMul, biases);
//Softmax 是一个常用的激活函数,它将输入转换为表示概率分布的输出。对于输入向量中的每个元素,Softmax 函数会计算指数,
//并对所有元素求和,然后将每个元素的指数除以总和,最终得到一个概率分布。这通常用于多分类问题,以输出每个类别的概率
//激活函数
Softmax<TFloat32> softmax = tf.nn.softmax(add);
// 创建一个计算交叉熵的Mean对象
//损失函数
Mean<TFloat32> crossEntropy =
tf.math.mean( // 计算张量的平均值
tf.math.neg( // 计算张量的负值
tf.reduceSum( // 计算张量的和
tf.math.mul(labels, tf.math.log(softmax)), //计算标签和softmax预测的对数乘积
tf.array(1) // 在指定轴上求和
)
),
tf.array(0) // 在指定轴上求平均值
);
// Back-propagate gradients to variables for training
//使用梯度下降优化器来最小化交叉熵损失函数。首先,创建了一个梯度下降优化器 optimizer,然后使用该优化器来最小化交叉熵损失函数 crossEntropy。
//梯度下降 https://www.cnblogs.com/guoyaohua/p/8542554.html
Optimizer optimizer = new GradientDescent(graph, LEARNING_RATE);
Op minimize = optimizer.minimize(crossEntropy);
// Compute the accuracy of the model
//使用 argMax 函数找出在给定轴上张量中最大值的索引,
Operand<TInt64> predicted = tf.math.argMax(softmax, tf.constant(1));
Operand<TInt64> expected = tf.math.argMax(labels, tf.constant(1));
//使用 equal 函数比较模型预测的标签和实际标签是否相等,再用 cast 函数将布尔值转换为浮点数,最后使用 mean 函数计算准确率。
Operand<TFloat32> accuracy = tf.math.mean(tf.dtypes.cast(tf.math.equal(predicted, expected), TFloat32.class), tf.array(0));
// Run the graph
try (Session session = new Session(graph)) {
// Train the model
for (ImageBatch trainingBatch : dataset.trainingBatches(TRAINING_BATCH_SIZE)) {
try (TFloat32 batchImages = preprocessImages(trainingBatch.images());
TFloat32 batchLabels = preprocessLabels(trainingBatch.labels())) {
System.out.println("batchImages = " + batchImages.shape());
System.out.println("batchLabels = " + batchLabels.shape());
// 创建会话运行器
session.runner()
// 添加要最小化的目标
.addTarget(minimize)
// 通过feed方法将图像数据输入到模型中
.feed(images.asOutput(), batchImages)
// 通过feed方法将标签数据输入到模型中
.feed(labels.asOutput(), batchLabels)
// 运行会话
.run();
}
}
// Test the model
ImageBatch testBatch = dataset.testBatch();
try (TFloat32 testImages = preprocessImages(testBatch.images());
TFloat32 testLabels = preprocessLabels(testBatch.labels());
// 定义一个TFloat32类型的变量accuracyValue,用于存储计算得到的准确率值
TFloat32 accuracyValue = (TFloat32) session.runner()
// 从会话中获取准确率值
.fetch(accuracy)
.fetch(predicted)
.fetch(expected)
// 将images作为输入,testImages作为数据进行喂养
.feed(images.asOutput(), testImages)
// 将labels作为输入,testLabels作为数据进行喂养
.feed(labels.asOutput(), testLabels)
// 运行会话并获取结果
.run()
// 获取第一个结果并存储在accuracyValue中
.get(0)) {
System.out.println("Accuracy: " + accuracyValue.getFloat());
}
// 保存模型
SavedModelBundle.Exporter exporter = SavedModelBundle.exporter("D:\ai\ai-demo").withSession(session);
Signature.Builder builder = Signature.builder();
builder.input("images", images);
builder.input("labels", labels);
builder.output("accuracy", accuracy);
builder.output("expected", expected);
builder.output("predicted", predicted);
Signature signature = builder.build();
SessionFunction sessionFunction = SessionFunction.create(signature, session);
exporter.withFunction(sessionFunction);
exporter.export();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static final int VALIDATION_SIZE = 5;
private static final int TRAINING_BATCH_SIZE = 100;
private static final float LEARNING_RATE = 0.2f;
private static TFloat32 preprocessImages(ByteNdArray rawImages) {
Ops tf = Ops.create();
// Flatten images in a single dimension and normalize their pixels as floats.
long imageSize = rawImages.get(0).shape().size();
return tf.math.div(
tf.reshape(
tf.dtypes.cast(tf.constant(rawImages), TFloat32.class),
tf.array(-1L, imageSize)
),
tf.constant(255.0f)
).asTensor();
}
private static TFloat32 preprocessLabels(ByteNdArray rawLabels) {
Ops tf = Ops.create();
// Map labels to one hot vectors where only the expected predictions as a value of 1.0
return tf.oneHot(
tf.constant(rawLabels),
tf.constant(MnistDataset.NUM_CLASSES),
tf.constant(1.0f),
tf.constant(0.0f)
).asTensor();
}
private final Graph graph;
private final MnistDataset dataset;
private SimpleMnist(Graph graph, MnistDataset dataset) {
this.graph = graph;
this.dataset = dataset;
}
public void loadModel(String exportDir) {
// load saved model
SavedModelBundle model = SavedModelBundle.load(exportDir, "serve");
try {
printSignature(model);
} catch (Exception e) {
throw new RuntimeException(e);
}
ByteNdArray validationImages = dataset.getValidationImages();
ByteNdArray validationLabels = dataset.getValidationLabels();
TFloat32 testImages = preprocessImages(validationImages);
System.out.println("testImages = " + testImages.shape());
TFloat32 testLabels = preprocessLabels(validationLabels);
System.out.println("testLabels = " + testLabels.shape());
Result run = model.session().runner()
.feed("Placeholder:0", testImages)
.feed("Placeholder_1:0", testLabels)
.fetch("ArgMax:0")
.fetch("ArgMax_1:0")
.fetch("Mean_1:0")
.run();
// 处理输出
Optional<Tensor> tensor1 = run.get("ArgMax:0");
Optional<Tensor> tensor2 = run.get("ArgMax_1:0");
Optional<Tensor> tensor3 = run.get("Mean_1:0");
TInt64 predicted = (TInt64) tensor1.get();
Long predictedValue = predicted.getObject(0);
System.out.println("predictedValue = " + predictedValue);
TInt64 expected = (TInt64) tensor2.get();
Long expectedValue = expected.getObject(0);
System.out.println("expectedValue = " + expectedValue);
TFloat32 accuracy = (TFloat32) tensor3.get();
System.out.println("accuracy = " + accuracy.getFloat());
}
private static void printSignature(SavedModelBundle model) throws Exception {
MetaGraphDef m = model.metaGraphDef();
SignatureDef sig = m.getSignatureDefOrThrow("serving_default");
int numInputs = sig.getInputsCount();
int i = 1;
System.out.println("MODEL SIGNATURE");
System.out.println("Inputs:");
for (Map.Entry<String, TensorInfo> entry : sig.getInputsMap().entrySet()) {
TensorInfo t = entry.getValue();
System.out.printf(
"%d of %d: %-20s (Node name in graph: %-20s, type: %s)\n",
i++, numInputs, entry.getKey(), t.getName(), t.getDtype());
}
int numOutputs = sig.getOutputsCount();
i = 1;
System.out.println("Outputs:");
for (Map.Entry<String, TensorInfo> entry : sig.getOutputsMap().entrySet()) {
TensorInfo t = entry.getValue();
System.out.printf(
"%d of %d: %-20s (Node name in graph: %-20s, type: %s)\n",
i++, numOutputs, entry.getKey(), t.getName(), t.getDtype());
}
System.out.println("-----------------------------------------------");
}
}五、最后两套代码运行结果
六、待完善点
1、这里并没有对提供web服务输入图片以及图片数据二值话等进行处理。有兴趣的小伙伴可以自己进行尝试
2、并没有使用卷积神经网络等,只是用了wx+b和激活函数进行跳跃,以及阶梯下降算法和交叉熵
3、没有进行更多层级的设计等





