
1. 背景
我方有一应用,偶尔会出现GC时间过长(间隔约4小时),导致性能波动的问题(接口最长需要耗时3秒以上)。经排查为G1垃圾回收器参数配置不当 叠加 MySQL 链接超过闲置时间回收,产生大量的虚引用,导致G1在执行老年代混合GC,标记阶段耗时过长导致。以下为对此问题的分析及问题总结。
此外,此应用因为使用redis缓存为数据库缓存一段时间的热点数据,导致业务起量创建数据库链接后,会很容易被闲置,容易被数据库连接池判定为闲置过长而清理。
应用背景
JDK1.8 , mysql-connector-java-5.1.30, commons-dbcp-1.4, spring-4.3.20.RELEASE
硬件:8核16GB;
JVM启动参数概要:
-Xms9984m -Xmx9984m -XX:MaxMetaspaceSize=512m -XX:MetaspaceSize=512m -XX:MaxDirectMemorySize=512m -XX:ParallelGCThreads=8 -XX:CICompilerCount=4 -XX:ConcGCThreads=4 -server -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:SurvivorRatio=10 -XX:MaxTenuringThreshold=5 -XX:InitiatingHeapOccupancyPercent=45 -XX:G1ReservePercent=20 -XX:G1MixedGCLiveThresholdPercent=80 -XX:MaxGCPauseMillis=100 -XX:+ExplicitGCInvokesConcurrent -XX:+PrintGCDetails -XX:+PrintReferenceGC -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:/export/Logs/app/tomcat7-gc.logdbcp配置:
maxActive=20
initialSize=10
maxIdle=10
minIdle=5
minEvictableIdleTimeMillis=180000
timeBetweenEvictionRunsMillis=20000
validationQuery=select 1配置说明:
maxActive=20: 连接池中最多能够同时存在的连接数,配置为20。- `initialSize=10: 数据源初始化时创建的连接数,配置为10。
maxIdle=10: 连接池中最大空闲连接数,也就是说当连接池中的连接数超过10个时,多余的连接将会被释放,配置为10。minIdle=5: 连接池中最小空闲连接数,也就是说当连接池中的连接数少于5个时,会自动添加新的连接到连接池中,配置为5。- `minEvictableIdleTimeMillis=180000: 连接在连接池中最小空闲时间,这里配置为3分钟,表示连接池中的连接在空闲3分钟之后将会被移除,避免长时间占用资源。
timeBetweenEvictionRunsMillis=20000: 连接池中维护线程的运行时间间隔,单位毫秒。这里配置为20秒,表示连接池中会每隔20秒检查连接池中的连接是否空闲过长时间并且需要关闭。validationQuery=select 1: 验证连接是否有效的SQL语句,这里使用了一个简单的SELECT 1查询。
关键词
java G1GC , G1参数调优,G1 STW 耗时过长,com.mysql.jdbc.NonRegisteringDriver,ConnectionPhantomReference,PhantomReference, GC ref-proc spent too much time ,GC remark,Finalize Marking
2. 问题排查
可用率报警
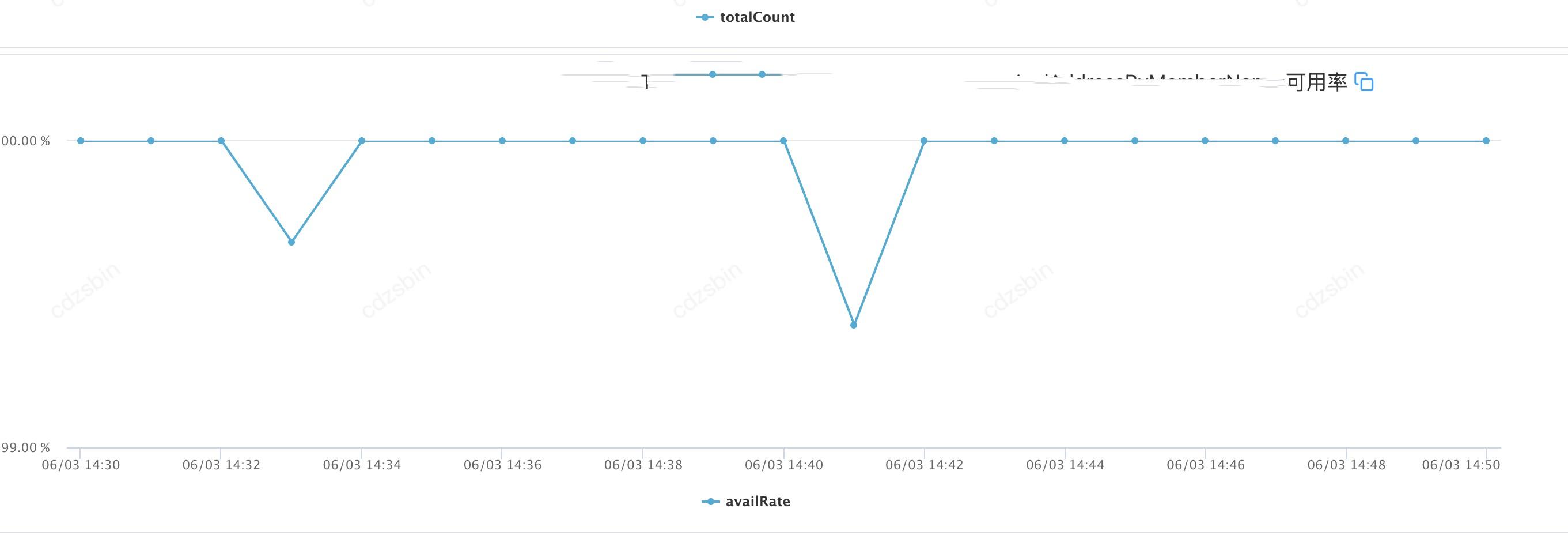
日志查询
查询本地日志,找到下游timeout的接口日志, 并找到相关IP为:11.#.#.201
查看jvm监控
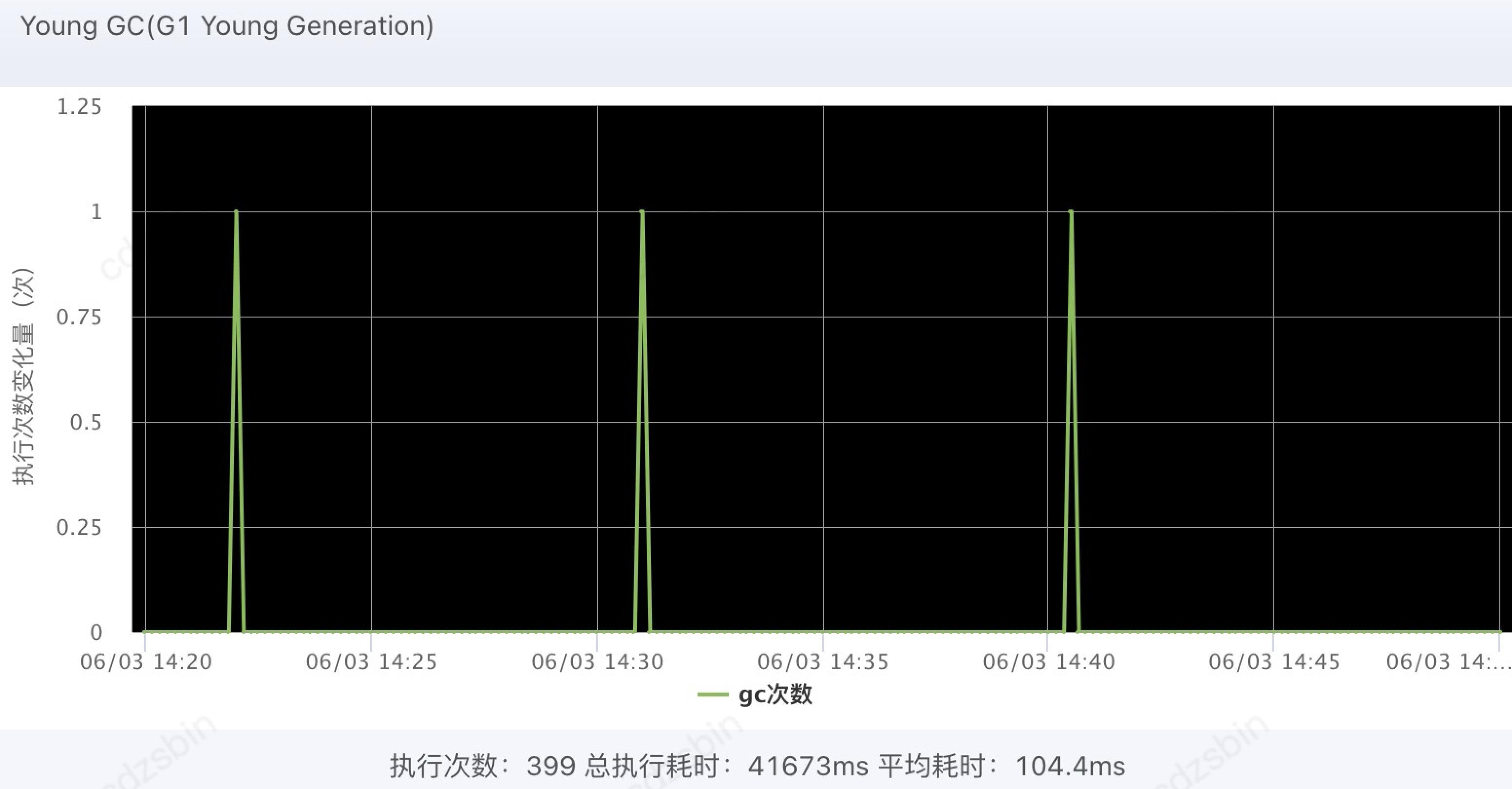
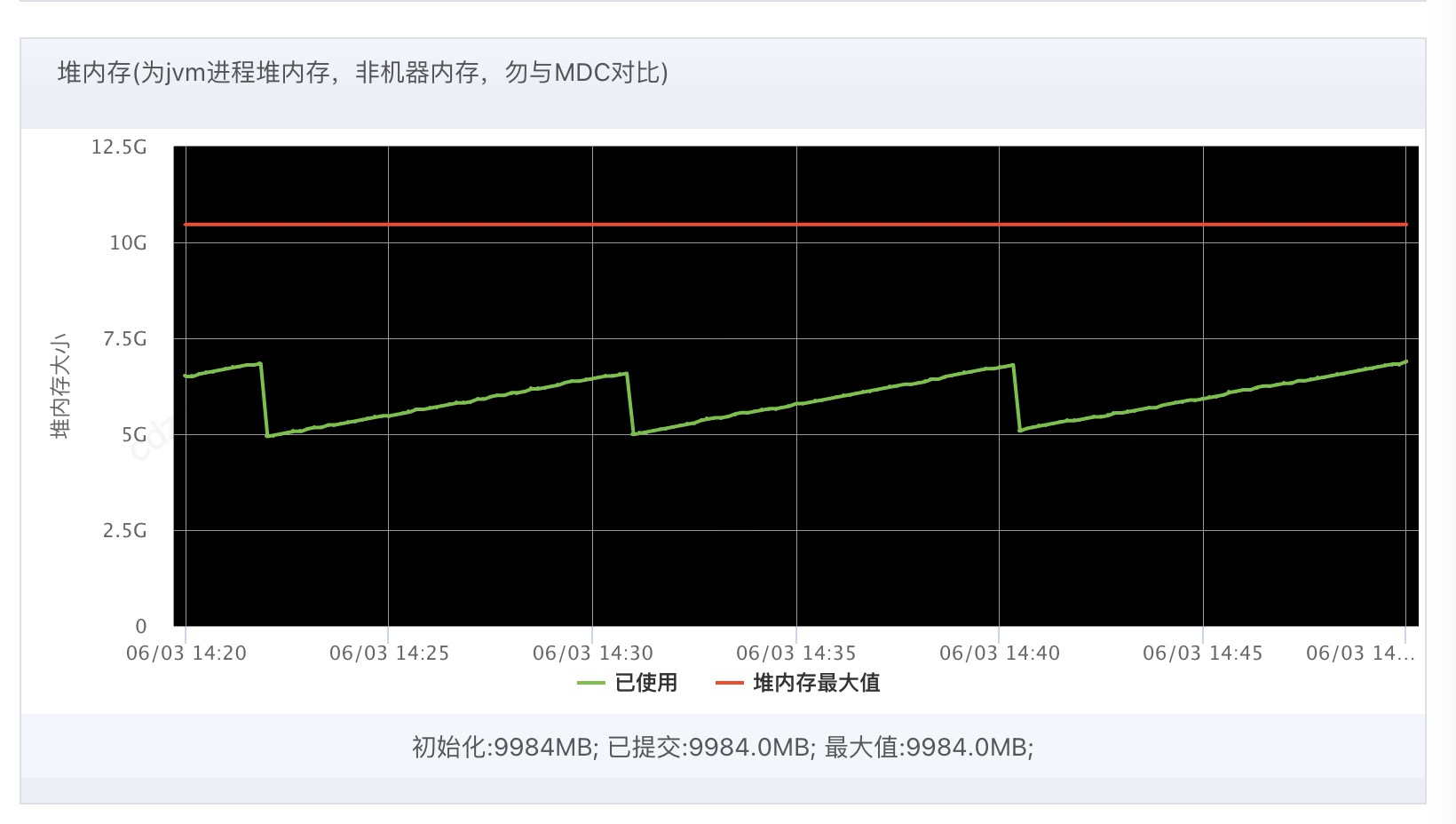
这里有个问题,因为系统工具ump对jvm 的监控,只关注young gc & full gc, 遗漏了G1的混合GC, 导致直接通过系统监控未及时发现GC过长的问题。到后面下载了gc日志,最终分析得到了 GC时间超过3.7秒的监控结果,这也是问题的根源。
3. 问题分析
GC日志分析
2023-06-03T14:40:31.391+0800: 184748.113: [GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.1017154 secs]
[Parallel Time: 70.3 ms, GC Workers: 6]
[GC Worker Start (ms): Min: 184748113.5, Avg: 184748113.6, Max: 184748113.6, Diff: 0.1]
[Ext Root Scanning (ms): Min: 1.9, Avg: 2.1, Max: 2.2, Diff: 0.3, Sum: 12.3]
[Update RS (ms): Min: 9.7, Avg: 9.9, Max: 10.4, Diff: 0.7, Sum: 59.6]
[Processed Buffers: Min: 12, Avg: 39.5, Max: 84, Diff: 72, Sum: 237]
[Scan RS (ms): Min: 0.1, Avg: 0.7, Max: 1.2, Diff: 1.1, Sum: 4.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 56.9, Avg: 57.5, Max: 57.7, Diff: 0.8, Sum: 344.8]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 6]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 70.1, Avg: 70.1, Max: 70.2, Diff: 0.1, Sum: 420.9]
[GC Worker End (ms): Min: 184748183.7, Avg: 184748183.7, Max: 184748183.7, Diff: 0.0]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.4 ms]
[Other: 31.0 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 30.1 ms]
[Ref Enq: 0.1 ms]
[Redirty Cards: 0.2 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.1 ms]
[Eden: 1760.0M(1760.0M)->0.0B(2080.0M) Survivors: 192.0M->224.0M Heap: 6521.7M(9984.0M)->4912.0M(9984.0M)]
Heap after GC invocations=408 (full 0):
garbage-first heap total 10223616K, used 5029872K [0x0000000570000000, 0x00000005720009c0, 0x00000007e0000000)
region size 32768K, 7 young (229376K), 7 survivors (229376K)
Metaspace used 112870K, capacity 115300K, committed 115968K, reserved 1150976K
class space used 12713K, capacity 13380K, committed 13568K, reserved 1048576K
}
[Times: user=0.45 sys=0.01, real=0.10 secs]
2023-06-03T14:40:31.493+0800: 184748.215: [GC concurrent-root-region-scan-start]
2023-06-03T14:40:31.528+0800: 184748.251: [GC concurrent-root-region-scan-end, 0.0359052 secs]
2023-06-03T14:40:31.528+0800: 184748.251: [GC concurrent-mark-start]
2023-06-03T14:40:31.623+0800: 184748.345: [GC concurrent-mark-end, 0.0942951 secs]
2023-06-03T14:40:31.624+0800: 184748.347: [GC remark 2023-06-03T14:40:31.624+0800: 184748.347: [Finalize Marking, 0.0003013 secs] 2023-06-03T14:40:31.625+0800: 184748.347: [GC ref-proc, 3.7471488 secs] 2023-06-03T14:40:35.372+0800: 184752.094: [Unloading, 0.0254883 secs], 3.7778434 secs]
[Times: user=3.88 sys=0.05, real=3.77 secs]
2023-06-03T14:40:35.404+0800: 184752.127: [GC cleanup 4943M->4879M(9984M), 0.0025357 secs]
[Times: user=0.01 sys=0.00, real=0.00 secs]
2023-06-03T14:40:35.407+0800: 184752.129: [GC concurrent-cleanup-start]
2023-06-03T14:40:35.407+0800: 184752.130: [GC concurrent-cleanup-end, 0.0000777 secs]
{Heap before GC invocations=409 (full 0):
garbage-first heap total 10223616K, used 6930416K [0x0000000570000000, 0x00000005720009c0, 0x00000007e0000000)
region size 32768K, 67 young (2195456K), 7 survivors (229376K)
Metaspace used 112870K, capacity 115300K, committed 115968K, reserved 1150976K
class space used 12713K, capacity 13380K, committed 13568K, reserved 1048576K根据日志分析,该G1垃圾回收器共进行了一次youngGC 和 一次并发标记。
young GC在14:40:31.391开始,暂停时间为0.1017154秒,是 young collection 和 initial-mark 阶段。并且6个 GC 工作线程并行执行了70.3毫秒。GC 过程中,有多个阶段的时间记录和详细信息。堆大小从6521M减少到4912M。
并发标记在14:40:31.493开始,并涉及并发扫描、标记和重标记等阶段。在清理阶段结束后,堆大小从4943M减少到4879M。
因此,该 G1 垃圾回收器在这段时间STW(Stop-The-World)的总时间为 0.10 + 3.77 = 3.87 秒。
Gceasy.io 分析的结果:
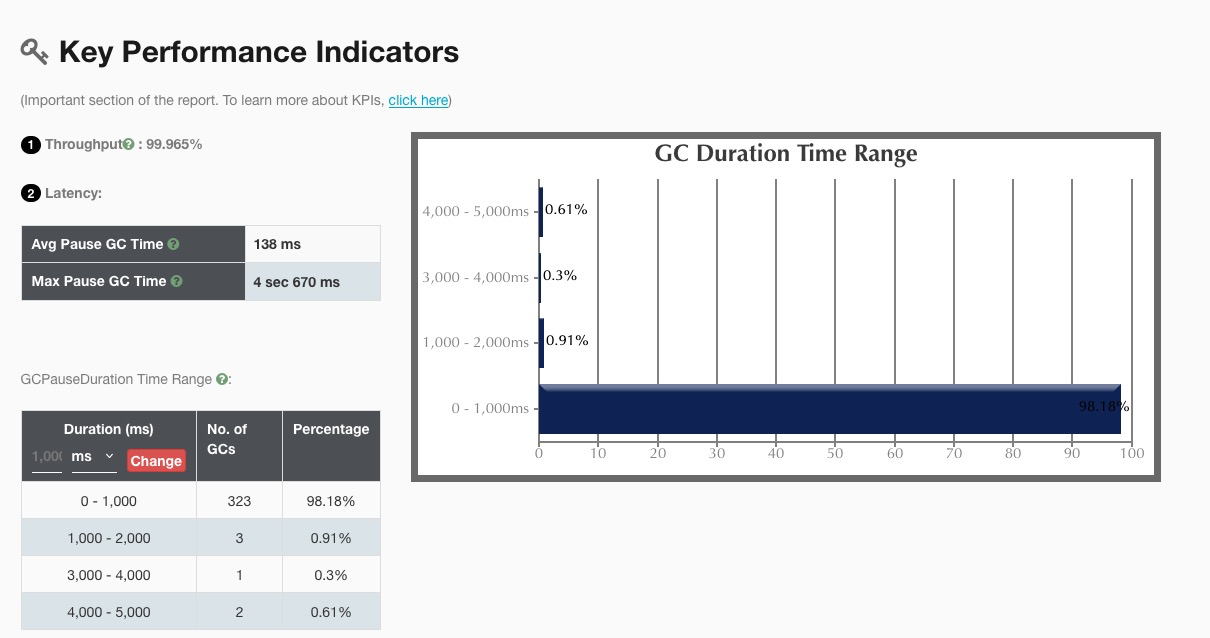
疑问1:youngGC后堆内存回收不明显?
后面会追溯到MySQL的链接池虚引用,本次GC只能先将链接实例GC掉, 而用于追踪connection实例回收的虚引用,会在下次GC才能被回收。

疑问2:G1的MaxGCPauseMillis是否严格遵守,为什么我配置了-XX:MaxGCPauseMillis=100 本次gc时间还是达到了3秒以上?
G1 的 -XX:MaxGCPauseMillis 参数表示 G1 GC 的最大 STW 时间,即如果单次 GC 暂停时间超过该值,则 G1 会尽可能地调整其行为以达到该目标。但是请注意,该参数是一个指导性的参数,不能保证绝对精度。
在实际应用中,由于应用程序和系统的负载情况、堆内存大小等因素的影响,GC 的发生和 STW 时间都可能会出现一定程度的波动和不确定性。因此,单次 GC 暂停时间超过 -XX:MaxGCPauseMillis 配置值是有可能发生的,而且这种情况在高负载或堆内存使用较高时更容易出现。
疑问3:监控中为啥出现了多次mixed GC, 而且间隔还如此的短
-XX:G1MixedGCCountTarget,默认为8,这个参数标识最后的混合回收阶段会执行8次,一次只回收掉一部分的Region,然后系统继续运行,过一小段时间之后,又再次进行混合回收,重复8次。执行这种间断的混合回收,就可以把每次的混合回收时间控制在我们需要的停顿时间之内了,同时达到垃圾清理的效果。清理了 7 次就已经满足了回收效果,所以没有继续 mixed GC。
以上是为了:MaxGCPauseMillis 停顿时间控制在期望范围内,所以会出现多次间隔很短连续的mixed GC.
dump分析
通过 MAT 工具分析发现,第一个可能的问题就是:com.mysql.jdbc.NonRegisteringDriver 占用比较大的内存,如下图:
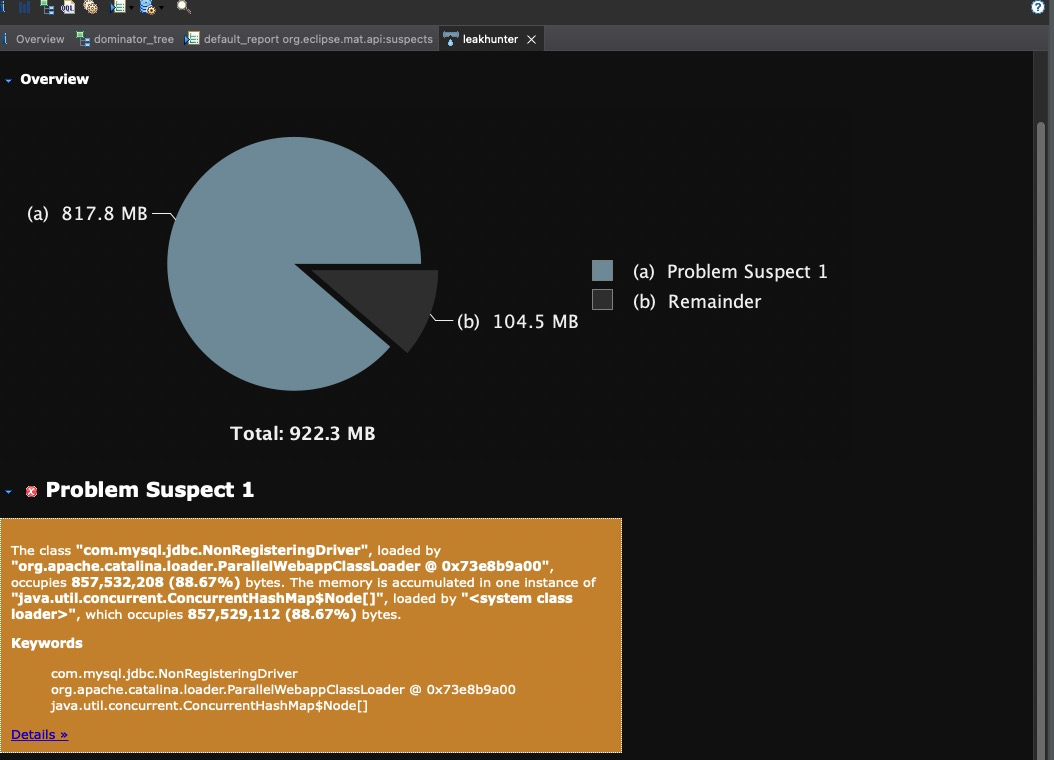
The class com.mysql.jdbc.NonRegisteringDriver, loaded by org.apache.catalina.loader.ParallelWebappClassLoader @ 0x73e8b9a00, occupies 857,532,208 (88.67%) bytes. The memory is accumulated in one instance of java.util.concurrent.ConcurrentHashMap$Node[], loaded by , which occupies 857,529,112 (88.67%) bytes.
Keywords
com.mysql.jdbc.NonRegisteringDriver
org.apache.catalina.loader.ParallelWebappClassLoader @ 0x73e8b9a00
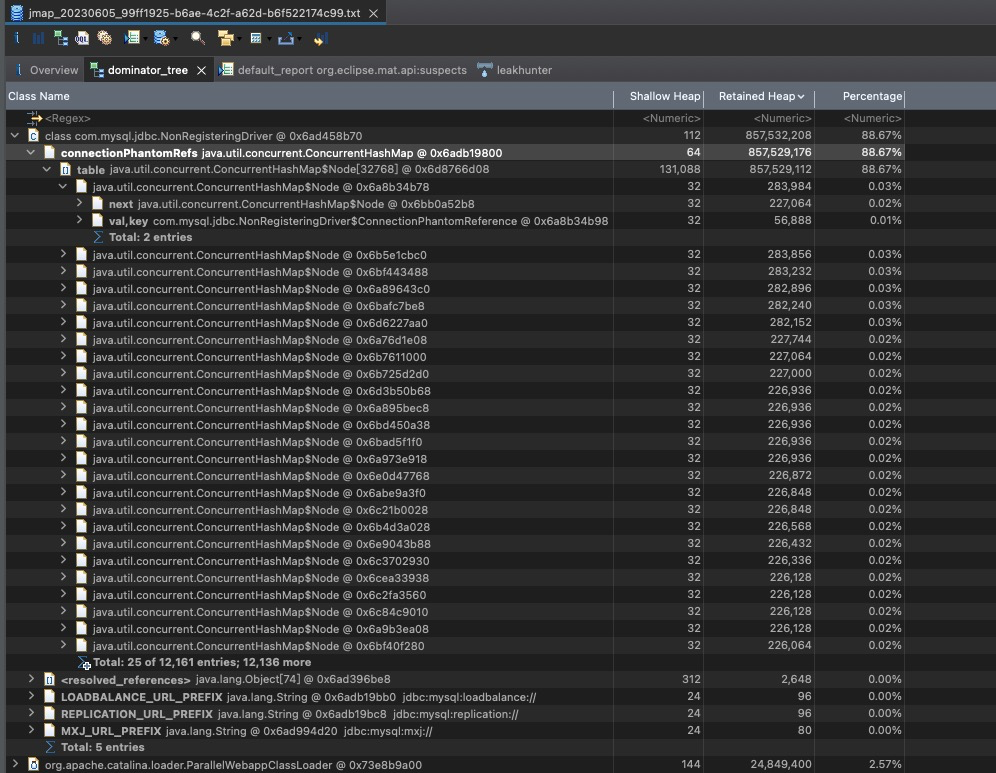
java.util.concurrent.ConcurrentHashMap$Node[]·然后看大对象列表,NonRegisteringDriver 对象确实占内存比较多,其中成员变量connectionPhantomRefs 占内存最多,里面存的是数据库连接的虚引用,其类型是 ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference>,占比居然有88%之多。
增加JVM参数,打印详细对象回收扫描日志
增加JVM参数: -XX:+PrintReferenceGC, 打印各种引用对象的详细回收时间:
PrintReferenceGC是JVM提供的一个参数,用于在进行垃圾回收时打印引用处理相关信息。当启用该参数后,JVM会在每次进行垃圾回收时将一些有关引用处理(Reference Processing)的信息输出到标准输出或指定的日志文件中。
具体来说,PrintReferenceGC参数可帮助开发人员和系统管理员更好地了解应用程序中各种类型引用被处理的情况,包括Soft Reference、Weak Reference、Phantom Reference等。这些信息对于诊断内存泄漏和调整垃圾回收器性能非常有用。
打印的详细的gc日志如下:
2023-06-04T10:28:52.886+0800: 24397.548: [GC concurrent-root-region-scan-start]
2023-06-04T10:28:52.941+0800: 24397.602: [GC concurrent-root-region-scan-end, 0.0545027 secs]
2023-06-04T10:28:52.941+0800: 24397.602: [GC concurrent-mark-start]
2023-06-04T10:28:53.198+0800: 24397.859: [GC concurrent-mark-end, 0.2565503 secs]
2023-06-04T10:28:53.199+0800: 24397.860: [GC remark 2023-06-04T10:28:53.199+0800: 24397.860: [Finalize Marking, 0.0004169 secs] 2023-06-04T10:28:53.199+0800: 24397.861: [GC ref-proc2023-06-04T10:28:53.199+0800: 24397.861: [SoftReference, 9247 refs, 0.0035753 secs]2023-06-04T10:28:53.203+0800: 24397.864: [WeakReference, 963 refs, 0.0003121 secs]2023-06-04T10:28:53.203+0800: 24397.865: [FinalReference, 60971 refs, 0.0693649 secs]2023-06-04T10:28:53.273+0800: 24397.934: [PhantomReference, 49828 refs, 20 refs, 4.5339260 secs]2023-06-04T10:28:57.807+0800: 24402.468: [JNI Weak Reference, 0.0000755 secs], 4.6213645 secs] 2023-06-04T10:28:57.821+0800: 24402.482: [Unloading, 0.0332897 secs], 4.6620392 secs]
[Times: user=4.60 sys=0.31, real=4.67 secs]
2023-06-04T10:28:57.863+0800: 24402.524: [GC cleanup 4850M->4850M(9984M), 0.0031413 secs]
[Times: user=0.01 sys=0.01, real=0.00 secs]
{Heap before GC invocations=68 (full 0):
garbage-first heap total 10223616K, used 7883923K [0x0000000570000000, 0x00000005720009c0, 0x00000007e0000000)
region size 32768K, 98 young (3211264K), 8 survivors (262144K)
Metaspace used 111742K, capacity 114304K, committed 114944K, reserved 1150976K
class space used 12694K, capacity 13362K, committed 13568K, reserved 1048576K翻译日志内容如下:
2023-06-04T10:28:52.886+0800: 24397.548: [GC concurrent-root-region-scan-start]:开始扫描并发根区域。
2023-06-04T10:28:52.941+0800: 24397.602: [GC concurrent-root-region-scan-end, 0.0545027 secs]:并发根区域扫描结束,持续时间为0.0545027秒。
2023-06-04T10:28:52.941+0800: 24397.602: [GC concurrent-mark-start]:开始并发标记过程。
2023-06-04T10:28:53.198+0800: 24397.859: [GC concurrent-mark-end, 0.2565503 secs]:并发标记过程结束,持续时间为0.2565503秒。
2023-06-04T10:28:53.199+0800: 24397.860: [GC remark]: G1执行remark阶段。
2023-06-04T10:28:53.199+0800: 24397.860: [Finalize Marking, 0.0004169 secs]:标记finalize队列中待处理对象,持续时间为0.0004169秒。
2023-06-04T10:28:53.199+0800: 24397.861: [GC ref-proc]: 进行引用处理。
2023-06-04T10:28:53.199+0800: 24397.861: [SoftReference, 9247 refs, 0.0035753 secs]:处理软引用,持续时间为0.0035753秒。
2023-06-04T10:28:53.203+0800: 24397.864: [WeakReference, 963 refs, 0.0003121 secs]:处理弱引用,持续时间为0.0003121秒。
2023-06-04T10:28:53.203+0800: 24397.865: [FinalReference, 60971 refs, 0.0693649 secs]:处理虚引用,持续时间为0.0693649秒。
2023-06-04T10:28:53.273+0800: 24397.934: [PhantomReference, 49828 refs, 20 refs, 4.5339260 secs]:处理final reference中的phantom引用,持续时间为4.5339260秒。
2023-06-04T10:28:57.807+0800: 24402.468: [JNI Weak Reference, 0.0000755 secs]:处理JNI weak引用,持续时间为0.0000755秒。
2023-06-04T10:28:57.821+0800: 24402.482: [Unloading, 0.0332897 secs]:卸载无用的类,持续时间为0.0332897秒。
[Times: user=4.60 sys=0.31, real=4.67 secs]:垃圾回收的时间信息,user表示用户态CPU时间、sys表示内核态CPU时间、real表示实际运行时间。
2023-06-04T10:28:57.863+0800: 24402.524: [GC cleanup 4850M->4850M(9984M), 0.0031413 secs]:执行cleanup操作,将堆大小从4850M调整为4850M,持续时间为0.0031413秒。其中PhantomReference耗时最长:
2023-06-04T10:28:53.273+0800: 24397.934: [PhantomReference, 49828 refs, 20 refs, 4.5339260 secs]:处理final reference中的phantom引用,持续时间为4.5339260秒。
源码追踪
MYSQL driver相关
注意,本源码基于当前依赖的mysql-connector-java-5.1.30.jar, 各版本的代码有一定差异性质;
涉及MySQL创建连接池的地方为:com.mysql.jdbc.NonRegisteringDriver#connect方法:
public Connection connect(String url, Properties info) throws SQLException {
//...省略部分代码
Properties props = null;
if ((props = this.parseURL(url, info)) == null) {
return null;
} else if (!"1".equals(props.getProperty("NUM_HOSTS"))) {
return this.connectFailover(url, info);
} else {
try {
// 获取连接主要在这里
com.mysql.jdbc.Connection newConn = ConnectionImpl.getInstance(this.host(props), this.port(props), props, this.database(props), url);
return newConn;
} catch (SQLException var6) {
throw var6;
} catch (Exception var7) {
SQLException sqlEx = SQLError.createSQLException(Messages.getString("NonRegisteringDriver.17") + var7.toString() + Messages.getString("NonRegisteringDriver.18"), "08001", (ExceptionInterceptor)null);
sqlEx.initCause(var7);
throw sqlEx;
}
}
}com.mysql.jdbc.ConnectionImpl构造器比较长,在完成参数构建后,在其结尾处,发现它调用了NonRegisteringDriver.trackConnection(this)。
public ConnectionImpl(String hostToConnectTo, int portToConnectTo, Properties info, String databaseToConnectTo, String url) throws SQLException {
......
NonRegisteringDriver.trackConnection(this);
}其中追踪任务的注册如下:这段MySQL driver源码的作用是实现对MySQL数据库连接的跟踪。
public class NonRegisteringDriver {
//省略部分代码...
// 连接虚引用指向map的容器声明
protected static final ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference> connectionPhantomRefs = new ConcurrentHashMap();
// 将连接放入追踪容器中
protected static void trackConnection(com.mysql.jdbc.Connection newConn) {
ConnectionPhantomReference phantomRef = new ConnectionPhantomReference((ConnectionImpl)newConn, refQueue);
connectionPhantomRefs.put(phantomRef, phantomRef);
}
//省略部分代码...
}第一行代码声明了一个名为connectionPhantomRefs的ConcurrentHashMap容器,该容器用于存储ConnectionPhantomReference实例。
第二个方法trackConnection的作用是将新连接添加到connectionPhantomRefs映射中。它接受一个com.mysql.jdbc.Connection对象作为参数,创建一个新的ConnectionPhantomReference实例,并使用它和引用队列(refQueue)将其添加到connectionPhantomRefs映射中。
总的来说,这两个代码片段旨在通过使用虚引用来实现跟踪连接到MySQL数据库的机制。虚引用用于跟踪已被JVM垃圾回收的对象,允许程序在对象从内存中删除后执行特定任务。
连接虚引用为静态内部类
这段代码是 MySQL 驱动程序的一部分,用于清理底层网络资源并确保在 MySQL 连接对象被垃圾回收时释放这些资源。
static class ConnectionPhantomReference extends PhantomReference<ConnectionImpl> {
private NetworkResources io;
ConnectionPhantomReference(ConnectionImpl connectionImpl, ReferenceQueue<ConnectionImpl> q) {
super(connectionImpl, q);
try {
this.io = connectionImpl.getIO().getNetworkResources();
} catch (SQLException var4) {
}
}
void cleanup() {
if (this.io != null) {
try {
this.io.forceClose();
} finally {
this.io = null;
}
}
}
}这段 MySQL driver 源码中的 ConnectionPhantomReference 类是一个继承自 PhantomReference<ConnectionImpl> 的静态内部类,其中 ConnectionImpl 是 MySQL 连接的实现类。该类的作用是在连接对象被垃圾回收时清理底层网络资源。
ConnectionPhantomReference 构造函数接受 ConnectionImpl 对象和一个引用队列作为参数,并调用父类 PhantomReference 的构造函数来创建虚引用。它还通过调用 ConnectionImpl 的 getIO().getNetworkResources() 方法获取与连接关联的网络资源。如果获取失败,则不会抛出异常。
cleanup() 方法用于在连接对象被垃圾回收后清理网络资源。它检查 io 属性是否为空,如果不为空,则调用 forceClose() 方法来强制关闭底层网络资源,最终将 io 属性设置为 null。整个过程确保连接对象被垃圾回收时,底层网络资源也被正确地释放。
MySQL为什么要使用虚引用来解决IO资源回收问题?
MySQL 使用虚引用来解决 IO 资源回收问题,主要是因为 JDBC 连接对象在关闭连接时无法保证其底层网络资源会被立即释放。这可能会导致底层网络资源长时间占用,最终导致应用程序出现性能下降或者资源耗尽的情况。
使用虚引用的好处在于,它允许程序在对象从内存中删除后执行特定任务。 MySQL 驱动程序利用 Java 提供的引用队列机制,将 JDBC 连接对象的虚引用加入到队列中。一旦连接对象被垃圾回收,JVM 会将它加入到引用队列中等待进一步处理。此时,MySQL 驱动程序通过监视引用队列并清理底层网络资源,确保这些资源在连接对象被垃圾回收时被正确地释放,从而避免了底层网络资源长时间占用的问题。
使用虚引用的优点在于可以实现更精细的内存管理和资源回收,提高应用程序的可靠性和性能。
那MySQL是怎样执行最终的IO资源回收的呢,是使用了定时任务还是异步守护线程?
MySQL 在执行最终的 IO 资源回收时,使用了异步守护线程来清理底层网络资源。
MySQL 驱动程序将 JDBC 连接对象的虚引用加入到引用队列中后,会创建一个专门的守护线程来监视该引用队列。当连接对象被垃圾回收并加入到引用队列中后,守护线程会从引用队列中获取该连接对象的虚引用,并在后台线程中执行与连接相关的底层网络资源清理工作。
具体来说,守护线程在每次迭代中从引用队列中获取一组虚引用,并调用虚引用的 cleanup() 方法来清理底层网络资源。如果成功清理,则将其从映射表中删除;否则,保留虚引用以便下一次迭代。
由于清理操作是在后台线程中进行的,因此不会阻塞应用程序的主线程。同时,使用异步守护线程还可以避免定时任务可能带来的性能开销和不必要的 CPU 使用率。
MySQL 使用异步守护线程来执行 IO 资源回收工作,这种方式可以确保底层网络资源的及时释放,并且不会对应用程序的性能产生负面影响。
以下是 MySQL 驱动程序中执行 IO 资源回收的守护线程的相关代码:
public class NonRegisteringDriver implements java.sql.Driver {
//省略代码...
//在MySQL driver中守护线程创建及启动...
static {
AbandonedConnectionCleanupThread referenceThread = new AbandonedConnectionCleanupThread();
referenceThread.setDaemon(true);
referenceThread.start();
}
//省略代码...
}
public class AbandonedConnectionCleanupThread extends Thread {
private static boolean running = true;
private static Thread threadRef = null;
public AbandonedConnectionCleanupThread() {
super("Abandoned connection cleanup thread");
}
public void run() {
threadRef = this;
while (running) {
try {
Reference<? extends ConnectionImpl> ref = NonRegisteringDriver.refQueue.remove(100);
if (ref != null) {
try {
((ConnectionPhantomReference) ref).cleanup();
} finally {
NonRegisteringDriver.connectionPhantomRefs.remove(ref);
}
}
} catch (Exception ex) {
// no where to really log this if we're static
}
}
}
public static void shutdown() throws InterruptedException {
running = false;
if (threadRef != null) {
threadRef.interrupt();
threadRef.join();
threadRef = null;
}
}
}这段代码是 MySQL 驱动程序中的一个类 AbandonedConnectionCleanupThread,该类继承自 Java 的 Thread 类。其作用是定期清理连接对象的底层网络资源,防止出现资源泄露和内存溢出等问题。在该类的 run() 方法中,循环检查是否有虚引用需要清理。如果存在,则调用 cleanup() 方法来清理虚引用所关联的底层网络资源,并从 NonRegisteringDriver.connectionPhantomRefs 映射中删除该虚引用。
在 MySQL 驱动程序中,connectionPhantomRefs 映射表的键和值都是 ConnectionPhantomReference 类型的对象,即使用同一个对象作为键和值。
这样做的主要原因是,在虚引用被加入到引用队列中时,需要从映射表中删除对应的虚引用。如果将虚引用对象作为键,那么在删除虚引用时,需要遍历整个映射表才能找到该虚引用对象并将其删除,这会造成不必要的性能开销。
相反,如果将虚引用对象作为值,那么只需要使用该虚引用对象自身来删除映射表中的条目,就可以提高删除效率。在 trackConnection() 方法中,创建一个新的 ConnectionPhantomReference 对象,并将其作为键和值存储到 connectionPhantomRefs 映射表中。这样,在虚引用被加入到引用队列中时,只需从映射表中删除该虚引用对象自身即可,无需遍历整个映射表。
总之,使用同一个对象作为映射表的键和值,可以更有效地删除映射表中的条目,提高性能和效率。
PS: java.lang.ref.ReferenceQueue#remove(long) 介绍
java.lang.ref.ReferenceQueue#remove(long) 方法的作用是从队列中移除已经被回收的 Reference 对象,若队列中没有任何元素,则该方法会一直等待直到有元素加入或者经过指定时间后返回 null。
该方法的参数为超时时间,单位为毫秒。如果在指定的超时时间内没有元素加入队列,则该方法返回 null。如果超时时间为 0,则该方法立即返回,并且不会等待任何元素加入队列。
通常情况下,程序不需要调用这个方法。Java 虚拟机会自动调用该方法来处理已经被回收的对象。只有在特定的情况下,如手动管理内存时才需要手动调用该方法。
这里使用java.lang.ref.ReferenceQueue主要作用是在Connection被垃圾回收器回收后, 能通过remove(timeout) 获取已经被回收的引用队列,然后进行后置处理。
推断
因为目前在NonRegisteringDriver的静态成员变量:connectionPhantomRefs, 有几万个对象, 证明在这段时间积累了大量的数据库链接connection实例进入以下生命周期:
创建 --> 闲置 ---> 回收;
疑点1:
因为前面连接闲置时间为db.minEvictableIdleTimeMillis=180000(3分钟), 可能是造成问题的关键。正常的MySQL链接闲置时间默认为8小时。
疑点2:
此外,因为该应用有多个数据源,且部分数据进行了分库,导致和数据库的连接数较多,而且访问请求也不均匀,这就导致了高峰期创建大量数据库连接池,低峰期又被回收。使com.mysql.jdbc.NonRegisteringDriver#connectionPhantomRefs 中的对象越来越多,而且大部分进入老年代,需要fullGC或者G1 的mixedGC才能进行回收。
4. 解决方案
方案1:调整JVM参数
虽然问题的根源是MySQL的链接失效,造成虚引用在gc的remark阶段耗时较长。但是我们的G1参数配置也存在问题:其中参数1的调整是本次减少GC时间的关键。
参数1:ParallelRefProcEnabled (并行引用处理开启)
经过核查应用确认为G1GC 参数配置不当,未开启ParallelRefProcEnabled(并行引用处理)JDK8需要手动开启,JDK9+已默认开启。 导致G1 Final Remark阶段使用单线程标记(G1混合GC的时候,STW约为2~3秒);
解决方案:
开启ParallelRefProcEnabled(并行引用处理)功能后,ParallelGCThreads=8 启用8线程标记;
参数2:ParallelGCThreads (并行 GC 线程数)
ParallelGCThreads参数是一个用于指定G1垃圾回收器并行垃圾收集线程数的参数。与其他Java垃圾回收器不同,G1垃圾回收器可以同时执行多个垃圾回收线程来加速垃圾回收速度。
在Java 8中,默认情况下,G1垃圾回收器的ParallelGCThreads参数设置为与CPU核心数量相同的值,最大为8。如果您的机器有更多的CPU核心,则可以通过手动调整该参数来提高并行垃圾回收的效率。例如,如果您的机器有8个核心,则可以将ParallelGCThreads设置为8或更高的值。
需要注意的是,过高的ParallelGCThreads值可能会导致处理器争用和上下文切换,从而影响应用程序的性能。因此,在进行调整时,应根据机器规格和实际负载进行测试和优化,以找到最佳参数配置。建议保持默认值,并在实测结果反馈之后再进行适当的调整。
另外,还可以使用-XX:+UseDynamicNumberOfGCThreads参数让G1自动适配并行线程数。这样,线程数量会根据系统负载自动增减,从而获得更好的性能
解决方案:
机器为8核,最开始只配置了6C,故而将并行GC线程数量增加到8,或者不不配置,默认为核心数8;
参数3:G1MixedGCLiveThresholdPercent (G1混合垃圾回收器存活阈值百分比)
G1MixedGCLiveThresholdPercent是一个用于控制G1垃圾回收器混合垃圾回收的参数,它决定混合垃圾回收器在何时执行。这个值指某一个标记为old region的区域中存活对象百分达到此阈值后,会被G1 mixed GC回收处理;
如果将该值设置得太低,则可能导致频繁的混合垃圾回收,从而影响应用程序的性能;如果将其设置得太高,则可能会导致老年代中的垃圾增加,造成堆内存占用过高,单次STW延长。
默认值: 85%;
解决方案:
因为前期设置为80, 本次调整为60 , 虽然增加混合GC触发的频率,但是因为此时对象更少,需要消耗的时间也变短;
参数4: MaxTenuringThreshold (对象晋升到老年代的最大年龄)
MaxTenuringThreshold是一个用于控制对象在Survivor区域中存活的时间阈值的参数,它指定了对象在经过多少次Minor GC后可以晋升到老年代。具体来说,如果某个对象在Survivor区域中存活了足够长的时间(即经过足够多次的Minor GC),则会被移动到老年代中。
在Java 8中,默认情况下,MaxTenuringThreshold参数设置为15,即对象必须在Survivor区域中存活15次Minor GC才能晋升到老年代。如果将其设置为0,则表示所有的对象都可以在第一次Minor GC时晋升到老年代;如果将其设置为较大的值,则表示只有存活时间比较长的对象才能晋升到老年代。
需要注意的是,如果将MaxTenuringThreshold参数设置得过小,则可能导致频繁的晋升和回收操作,从而影响应用程序的性能;如果将其设置得过大,则可能会导致Survivor区域中的空间不足,从而强制进行Full GC操作,同样也会影响应用程序的性能。
建议在实际应用程序场景中进行测试和优化,以找到最佳的MaxTenuringThreshold值。通常,该值应该设置在8-15之间,并且应根据应用程序的内存使用情况和GC日志进行调整。
解决方案:
因为前期设置为5, 本次调整为15 ,或者不需要配置,默认为15;
调整后的JVM参数
-Xms9984m -Xmx9984m -XX:MaxMetaspaceSize=512m -XX:MetaspaceSize=512m -XX:MaxDirectMemorySize=512m -XX:ParallelGCThreads=8 -XX:CICompilerCount=4 -XX:ConcGCThreads=4 -server -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC -XX:SurvivorRatio=10 -XX:InitiatingHeapOccupancyPercent=45 -XX:G1ReservePercent=20 -XX:G1MixedGCLiveThresholdPercent=60 -XX:MaxGCPauseMillis=100 -XX:+ExplicitGCInvokesConcurrent -XX:+ParallelRefProcEnabled -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintReferenceGC -XX:+PrintHeapAtGC -Xloggc:/export/Logs/app/tomcat7-gc.log 方案2: 优化MySQL的虚引用问题
调整连接池参数
在诸多连接池中,发现一个参数配置错误,有一个数据库的db.minEvictableIdleTimeMillis=180000(3分钟),适当调大连接的闲置时间到30Min;
将DBCP连接池参数minIdle调小,减少闲置线程的数量(在整个连接都不活跃的情况下),也可以起到一定作用;
但是这个方式,治标不治本, 因为虚引用还在一直产生。
优化MySQL driver虚引用
A. 反射暴力清理
虚引用往往做为一种兜底策略,避免用户忘记释放资源,引发内存泄露(在未使用连接池的如java初学者手撸的数据库链接管理代码往往是有用的)。我们使用DBCP或其它池化技术已经会严谨处理资源的释放,可以不采用兜底策略,直接删除中 connectionPhantomRefs 中的虚引用,使对象不可达,在 GC 时直接回收,从而减少 PhantomReference 的处理时间。
// 每两小时清理 connectionPhantomRefs,减少对 mixed GC 的影响
SCHEDULED_EXECUTOR.scheduleAtFixedRate(() -> {
try {
Field connectionPhantomRefs = NonRegisteringDriver.class.getDeclaredField("connectionPhantomRefs");
connectionPhantomRefs.setAccessible(true);
Map map = (Map) connectionPhantomRefs.get(NonRegisteringDriver.class);
if (map.size() > 50) {
map.clear();
}
} catch (Exception e) {
log.error("connectionPhantomRefs clear error!", e);
}
}, 2, 2, TimeUnit.HOURS);以上代码通过反射定时清理掉NonRegisteringDriver静态变量connectionPhantomRefs,即信任DBCP在链接回收的时候,会自动严谨处理资源释放。MySQL driver自带的安全防护全部定时清空,相当于禁用此功能。
特别说明: A方案无安全性问题,可放心采纳;
B. 升级MySQL jdbc driver到8.0.22+,开启disableAbandonedConnectionCleanup
Oracle应该是接收了大量开发人员的反馈,意识到了此功能可能造成GC严重过长的问题,在高版本中已经可以通过配置选择性关闭此非必要拖尾功能。 mysql-connector-java 版本(8.0.22+)的代码对数据库连接的虚引用有新的处理方式,其增加了开关,可以手动关闭此功能。
其版本8.0.22介绍增加此参数即是为了解决JVM 虚引用相关问题,但是默认是未启用,需要手动开启:
https://dev.mysql.com/doc/relnotes/connector-j/8.0/en/news-8-0-22.html
When using Connector/J, the AbandonedConnectionCleanupThread thread can now be disabled completely by setting the new system property com.mysql.cj.disableAbandonedConnectionCleanup to true when configuring the JVM. The feature is for well-behaving applications that always close all connections they create. Thanks to Andrey Turbanov for contributing to the new feature. (Bug #30304764, Bug #96870) 有了这个配置,就可以在启动参数上设置属性:
java -jar app.jar -Dcom.mysql.cj.disableAbandonedConnectionCleanup=true 或者在代码里设置属性:
System.setProperty(PropertyDefinitions.SYSP_disableAbandonedConnectionCleanup,"true");当 com.mysql.cj.disableAbandonedConnectionCleanup=true 时,生成数据库连接时就不会生成虚引用,对 GC 就没有任何影响了。
是否升级MySQL的驱动版本,根据实际情况取舍,以上A/B方案都能解决该问题。
总结
G1参数调优总结
- ParallelGCThreads 主要为并发标记相关线程,其本身处理时候也会STW, 最好全部占用CPU内核,如机器为8核,则该值最好设置为8;
- ConcGCThreads 为并发标记线程数量,其标记的时候,业务线程可以不STW, 可以使用部分核心,剩余部分核心用于跑业务线程;我们这里配置为CPU核心数量的一半4;
- MaxGCPauseMillis 只是一个期望值(GC会尽可能保证),并不能严格遵守,尤其是在标记阶段,会受到堆内存对象数量的影响,故而不能太过依赖此值觉得STW的实际时间;如我方配置的100ms, 实际出现3~4秒的机会也比较多;
- ParallelRefProcEnabled 如果你搜索的各种资料提醒你这个开关是默认开启的,那你要特别注意了; JDK8版本此功能是默认关闭的,在JDK9+之后才是默认开启。故而JDK8需要手动开启,保险起见,无论什么版本都配置该值;
- G1垃圾回收器基本上不会出现fullGC, 在youngGC 和 mixedGC(mixedGC频次也不高)就完成了垃圾回收。如果出现了fullGC, 反而应该排查是否有异常。
- 本文未对G1垃圾回收器之过程及原理进行详细分析,请参考其它文章进行理解;
MySQL虚引用问题总结
- MySQL 链接驱动如果在8.0.22版本以下,只能通过反射主动清理此非必要拖尾功能(一般成熟的数据库连接池功能都能安全释放链接相关资源)。
- MySQL驱动8.0.22+版本, 可以通过配置手动关闭此功能;
结果说明
经过以上调整后(MySQL的虚引用问题一并解决后),gc时间能较好的控制在100ms以内,平均耗时26ms。 mixed gc频率大幅度减少, 主要为youngGC。
参考资料
com.mysql.jdbc.NonRegisteringDriver 内存泄漏
infoq-Tips for Tuning the Garbage First Garbage Collector
Java Garbage Collection handbook
PPPHUANG- MySQL 驱动中虚引用 GC 耗时优化与源码分析
作者:京东零售 张世彬
来源:京东云开发者社区





