Java程序在运行过程中,会产生大量的内存垃圾(一些没有引用指向的内存对象都属于内存垃圾,因为这些对象已经失去标记,程序用不了它们了,对程序而言它们已经废弃),为了确保程序运行时的性能,java虚拟机在程序运行的过程中不断地进行自动的垃圾回收(GC),这就是我们的垃圾回收机制,关于垃圾回收我总结了一下几种:
标记–清除算法(Mark-Sweep)
为每个对象存储一个标记位,记录对象的状态(活着或是死亡)。
分为两个阶段,一个是标记阶段,这个阶段内,为每个对象更新标记位,检查对象是否死亡;第二个阶段是清除阶段,该阶段对死亡的对象进行清除,执行 GC 操作。
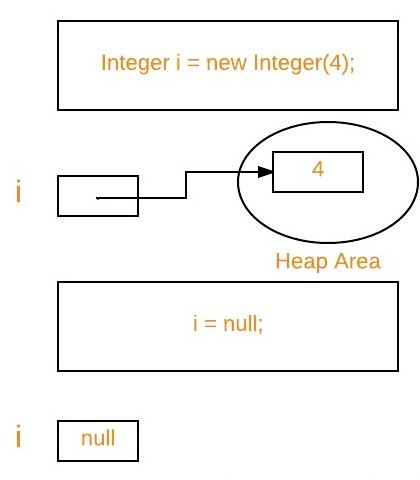
引用计数算法(Reference counting)
每个对象在创建的时候,就给这个对象绑定一个计数器。每当有一个引用指向该对象时,计数器加一;每当有一个指向它的引用被删除时,计数器减一。这样,当没有引用指向该对象时,该对象死亡,计数器为0,这时就应该对这个对象进行垃圾回收操作
复制算法(Reference counting)
该算法将内存平均分成两部分,然后每次只使用其中的一部分,当这部分内存满的时候,将内存中所有存活的对象复制到另一个内存中,然后将之前的内存清空,只使用这部分内存,循环下去。这个算法与标记-整理算法的区别在于,该算法不是在同一个区域复制,而是将所有存活的对象复制到另一个区域内
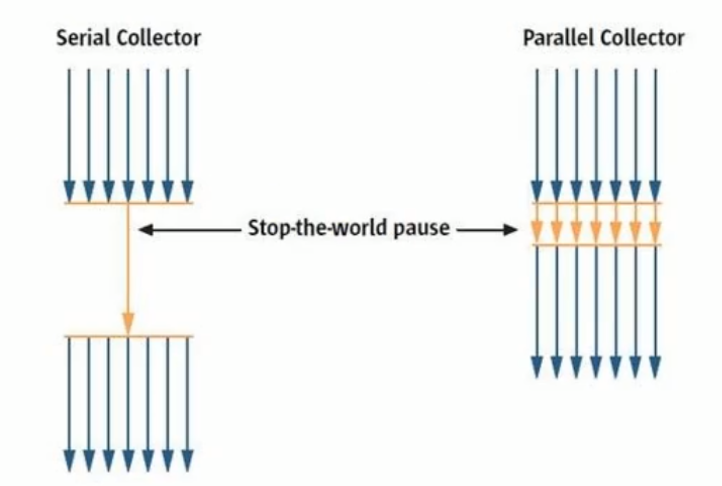
JVM不同的版本垃圾回收机制不一样
jdk1.7和1.8新版本和老版本区别
jdk1.7和1.8旧版本Parallel Old
jdk1.7和1.8新版本Parallel Scavenge
Parallel Old 收集器
Parallel Scavenge收集器的老年代版,使用多线程与标记–整理算法。这个收集器在jdk1.6中才开始提供的,直到Parallel Old 收集器出现后,“吞吐量优先”收集器终于有了比较名副其实的应用组合,在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge加 Parallel Old收集器
Parallel Scavenge收集器
Parallel Scavenge收集器是一个新生代的手机器,使用的是复制算法的收集器,而且也是多线程的收集器,Parallel Scavenge收集器,目标达到一个可控制的吞吐量,使用-XX:MaxGcPauseMillus参数控制垃圾停顿时间,使用-XX:GCTimeRatio参数控制吞吐量;
Parallel Scavenge收集器设置-XX:UseAdaptiveSizePolicy参数,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大吞吐量(GC自使用的调节策略); 当然自适应调节策略也是Parallel Scavenge收集器和ParNew收集器一个重要的区别!