现在国内人工智能发展得特别火,百度的文心一言ERNIE 4.0和阿里的通义千问Max都是很厉害的大语言模型。这俩在技术架构、应用场景和性能表现上各有各的厉害。这篇文章就打算好好比比它们俩,看看它们到底有啥不一样,帮开发者和企业用户选到最适合自己的技术。
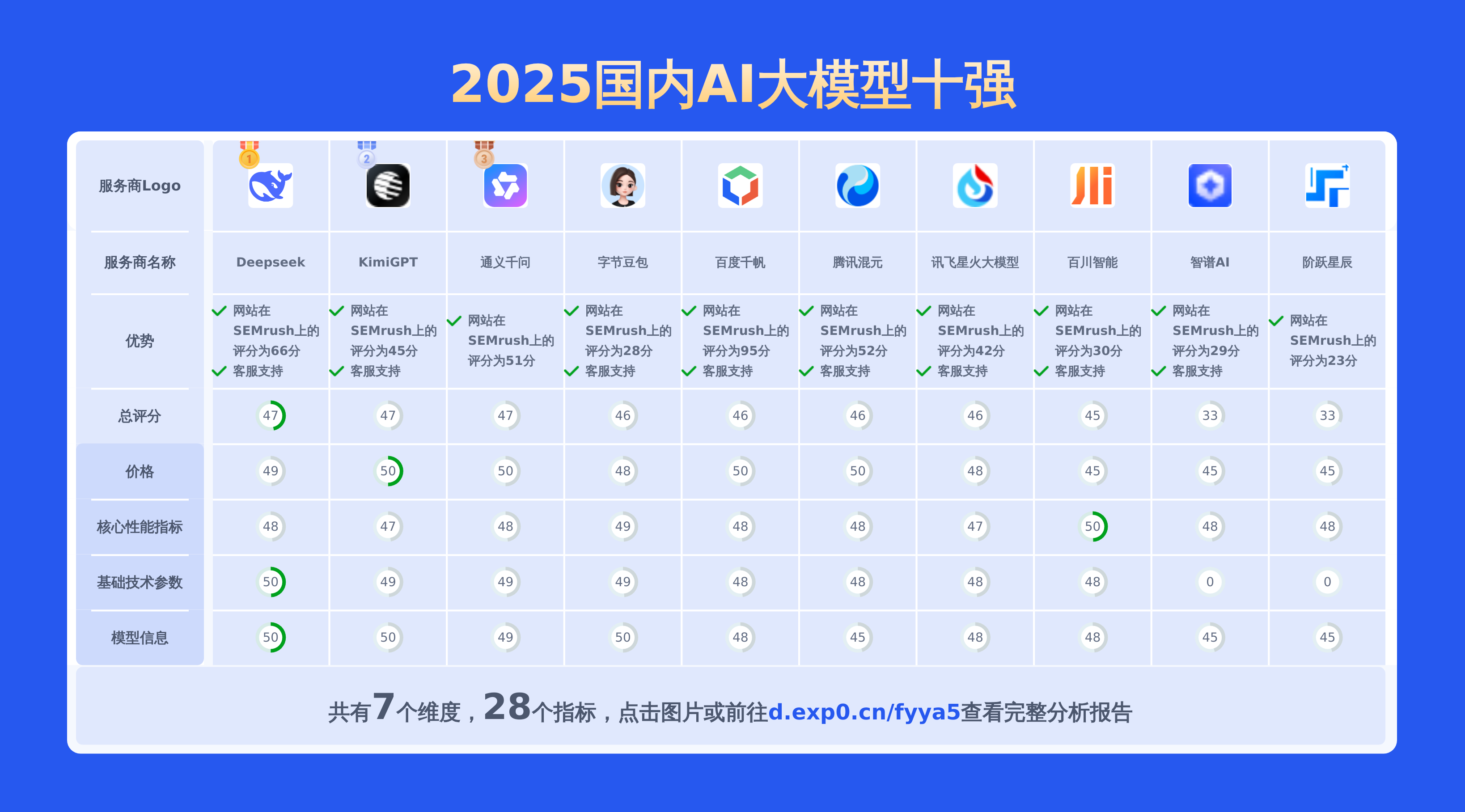
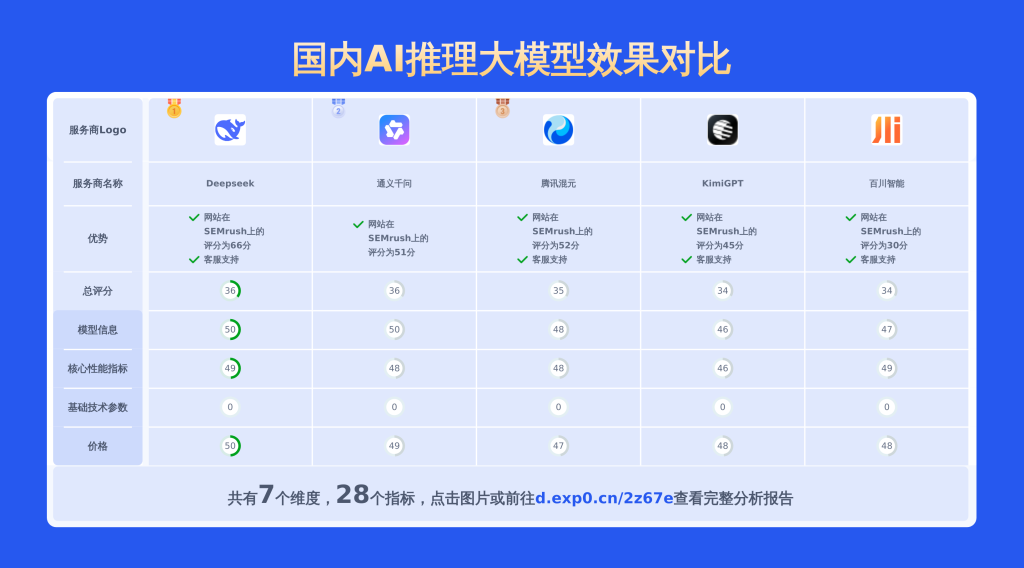
幂简集成精心整理了一份详尽的对比表格,全面覆盖国内主流开源AI大模型的核心性能指标、API产品特性、价格等关键信息。本文将重点从API产品表格和API接口效果两个角度进行分析,为您提供直观的比较视角,同时诚邀您查阅完整报表,获取更全面的洞察!
API产品规格
文心一言ERNIE 4.0
文心一言ERNIE 4.0是百度研发的旗舰级大语言模型,基于知识增强的ERNIE框架,在理解、生成、逻辑和记忆四大核心能力上实现突破性升级,综合性能对标GPT-4。其支持128K超长上下文输入,具备跨模态语义理解与多轮对话能力,可高效完成文本创作、代码生成、数学推理等复杂任务,并集成百度搜索插件确保信息时效性。该模型已应用于百度搜索、文库、地图等AI原生生态,企业用户可通过千帆平台API调用,个人用户可通过网页端及移动端体验智能交互服务。
通义千问Max
通义千问Max是阿里云自主研发的超大规模MoE(混合专家)语言模型,采用超过20万亿token的预训练数据和先进的后训练方案,在数学、编程、逻辑推理等复杂任务中表现卓越。其支持长达1000万token的上下文处理能力,可解析多格式文档,并具备多模态视觉理解能力,能分析图片、视频内容并提供解决方案。该模型在Arena-Hard、LiveBench等基准测试中超越DeepSeek-V3和GPT-4o等竞品,尤其擅长硬提示任务与长文本生成,广泛应用于智能客服、教育辅导、金融分析等领域,目前通过阿里云API及通义灵码等平台提供服务。
| 不可编辑 | 通义千问 | 百度千帆 |
|---|---|---|
| 模型信息 | ||
| API模型名称 | 通义千问-Max | ERNIE 4.0 |
| 价格 | ||
| 免费试用 | 赠送100万Tokens额度 | |
| 有效期:百炼开通后180天内 | 100万tokens,有效期三个月。 | |
| 输入价格(缓存命中) | 0.0024元/1千tokens | 0.004元/ 1千tokens |
| 输入价格(缓存未命中) | 0.0024元/1千tokens | 0.004元/ 1千tokens |
| 输出价格 | 0.0096元/1千tokens | 0.016元/ 1千tokens |
| 基础技术参数 | ||
| 输入方式 | 文本/图片/视频链接 | 文本 |
| 输出方式 | 文本 | 文本 |
| 上下文长度(Token) | 32k | 5K |
| 上下文理解 | 支持跨模态关联推理 | 是 |
| 文档理解 | N/A | 是 |
| 是否支持流式输出 | 是 | 是 |
| 是否支持联网搜索 | 是 | 是 |
| 是否开源 | 否 | 否 |
| 多模态支持 | 支持文本+图像生成 | 否 |
点击查看完整的报告内容
FlagEval大模型基准测试
FlagEval(大模型评测开源体系)是由智源研究院推出的综合性大模型评估基准,旨在系统化测评大模型在语言理解、生成、推理、多模态等核心能力。其特点包括:1)覆盖50+评测维度(如数学、代码、伦理等),支持中英双语;2)采用动态迭代机制,适配技术演进;3)开源评测工具与数据,促进透明化研究。该基准已应用于百亿至万亿级参数模型测评,为产业界和学术界提供标准化评估框架。
下面表格中的数据是文心一言 ERNIE 4.0 和通义千问 Qwen-MaxTurbo在FlagEval中的评测表现数据:
| 模型名称 | 开闭源类型 | 综合评分 | 简单理解 | 知识运用 | 推理能力 | 数学能力 | 任务解决 | 安全与价值观 |
|---|---|---|---|---|---|---|---|---|
| ERNIE 4.0 Turbo | 闭源 | 77.26 | 77.23 | 83.54 | 65.48 | 77.78 | 70.84 | 92.86 |
| Qwen-Max | 闭源 | 71.50 | 76.73 | 85.44 | 72.62 | 66.83 | 68.55 | 75.66 |
数据来源参照FlagEval大语言模型评测能力榜单
总体结论
- ERNIE 4.0 Turbo在推理能力、数据敏感(隐私)和安全性价值方面表现突出,适合需要高安全性和推理能力的场景。
- Qwen-Max在简单理解和知识运用方面更强,适合处理简单任务和知识密集型任务。
- 如果需要平衡各方面能力,ERNIE 4.0 Turbo可能更具优势,尤其是在安全性和推理需求较高的场景中。
API接口效果比较
提示词
写一封工作汇报邮件
文心一言 ERNIE 4.0 Turbo
主题:工作汇报 - XXXX年XX月
尊敬的领导:
您好!以下是我对XXXX年XX月份的工作汇报,请查阅。
一、工作总结:
项目进展:在本月,我主要负责了XX项目的推进工作。通过与团队成员的紧密合作,我们成功完成了项目A的前期调研和需求分析,并制定了详细的实施方案。目前,项目已顺利进入开发阶段。
团队协作:在团队协作方面,我积极与各部门沟通,确保项目资源的合理分配。同时,我还组织了多次团队会议,及时解决项目过程中出现的问题,提高了团队整体的工作效率。
个人能力提升:为了更好地完成工作任务,我在本月参加了多场专业培训课程,提升了自己在项目管理、沟通协调等方面的能力。这些新知识和技能将有助于我在未来的工作中取得更好的成绩。
二、下一步工作计划:
继续推进XX项目的开发工作,确保按照既定时间表完成项目交付。
加强与客户的沟通,及时了解客户需求变化,确保项目成果符合客户期望。
持续关注行业动态,为公司业务发展提供有益的建议和意见。
三、需协调与支持事项:
鉴于XX项目即将进入关键阶段,希望公司能给予更多的人力支持,以确保项目的顺利进行。
为了提高团队整体技能水平,建议公司定期组织相关培训活动。
感谢您的关注与支持!如有任何疑问或建议,请随时与我联系。
祝工作顺利!
[您的名字]
[您的职位]
[公司名称]
[日期]
点击试用验证更多模型效果,您可以体验不同AI模型的强大能力。
通义千问 Qwen-Max
当然,我可以帮你草拟一封工作汇报邮件。为了更好地定制内容,请先告诉我一些具体信息,比如你的职位、需要汇报的工作范围(项目进展、团队表现等)、接收邮件的人(直接上司还是整个团队)、以及任何特别想要强调的成绩或挑战。不过,如果你只需要一个通用模板,这里有一个例子供参考:
主题:[您的姓名] - [月份/周数] 工作总结与计划
尊敬的[收件人姓名/职位],
您好!
我是[部门名称][您的职位][您的姓名],在此向您汇报我/我们团队在[报告周期,如本周/本月]内的主要工作成果及下阶段的工作规划。
【一、已完成的工作】
- 项目A:
- 完成了...
- 达到了...目标
- 项目B:
- 实施了...
- 解决了...
【二、当前面临的问题】
- 在执行过程中遇到了...问题,目前采取了...措施来应对。
- 针对...方面的不足,正考虑通过...方式加以改进。
【三、下一步工作计划】
- 对于项目A,计划...
- 将启动新项目C,目标是...
- 计划参加...培训/会议以提升个人/团队能力。
【四、其他事项】
- [如果有其他重要事项需要提及]
最后,非常感谢领导对我们工作的支持和指导!如果对于以上内容有任何疑问或者建议,欢迎随时联系我。期待在未来能够继续得到您的宝贵意见和支持!
祝好,
[您的全名]
[您的职位]
[公司名称]
[联系电话]
[电子邮箱地址]
请根据实际情况调整上述模板中的具体内容。希望这个模板对你有所帮助!如果有更具体的细节需求,请告知我,以便提供更加个性化的帮助。
点击试用验证更多模型效果,您可以体验不同AI模型的强大能力。
根据文心一言 ERNIE 4.0 Turbo 和通义千问 Qwen-Max 在相同提示词下的生成效果对比,可以总结如下:
一、任务完成度
- 文心一言 ERNIE 4.0 Turbo:整体完成度较高,能准确理解任务并生成符合要求的内容。尤其在原创性问题(如诗歌创作)上表现突出,逻辑清晰,语言流畅,符合任务的主题和风格要求。
- 通义千问 Qwen-Max:任务完成度也不错,但部分生成内容(如诗歌)显得较为模板化,缺乏新意。整体逻辑性稍逊,特别是在复杂任务中可能偏离主题。
二、语言自然度和创意性
- 文心一言:语言更自然,表达更贴近人类习惯,创意性较强,尤其在需要发挥想象力的任务中(如诗歌、故事创作)能生成更具感染力的内容。
- 通义千问:语言流畅,但有时显得生硬,创意性稍显不足,生成的诗歌或故事可能更依赖常见句式,缺乏个性化表达。
三、细节处理和逻辑性
- 文心一言:细节处理更细腻,逻辑性更强,能更好地保持上下文连贯性,尤其在需要推理或复杂分析的任务中表现更好。
- 通义千问:细节处理稍弱,逻辑性在复杂任务中可能出现断层,部分生成内容显得不够深入或跑题。
四、其他关键要求
- 两模型均能满足基本的任务要求(如字数、格式),但文心一言在个性化输出和深度理解任务意图方面更占优势。
总结
文心一言 ERNIE 4.0 Turbo 在语言自然度、创意性和逻辑性上优于通义千问 Qwen-Max,尤其适合需要深度思考和原创性的任务。通义千问 Qwen-Max 则更适合简单、格式化的任务,但在复杂场景中表现稍显不足。若需更高生成质量,文心一言是更优选择。
如果开发者想要从更多维度来挑选合适的API服务商,例如基础技术参数、服务稳定性、互联网口碑等,可以自行挑选几家心仪的服务商,制作一份详细的比较报告,将它们的各项数据进行完整对比,从而帮助开发者找到最适合自身企业的API服务商。