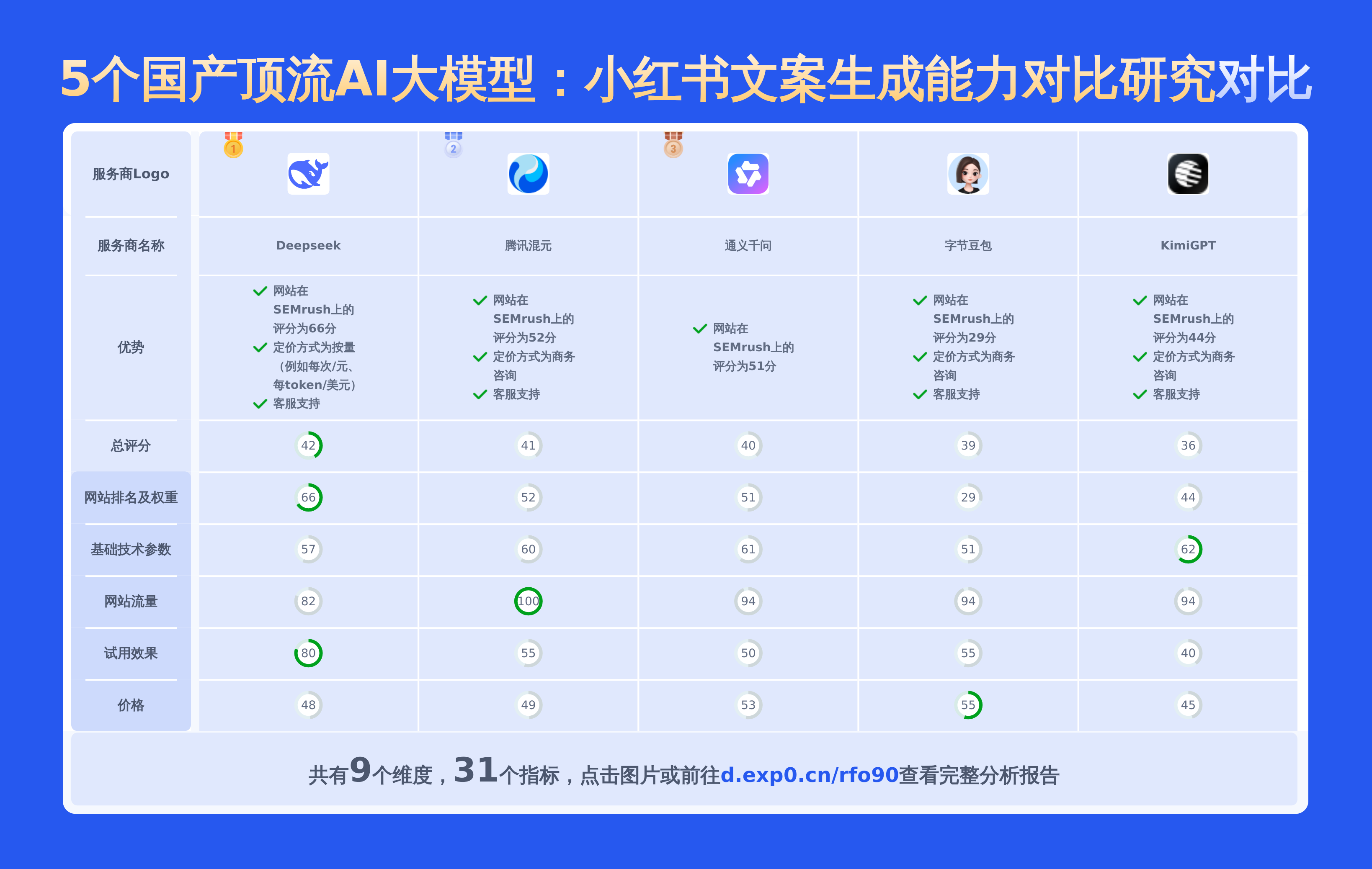
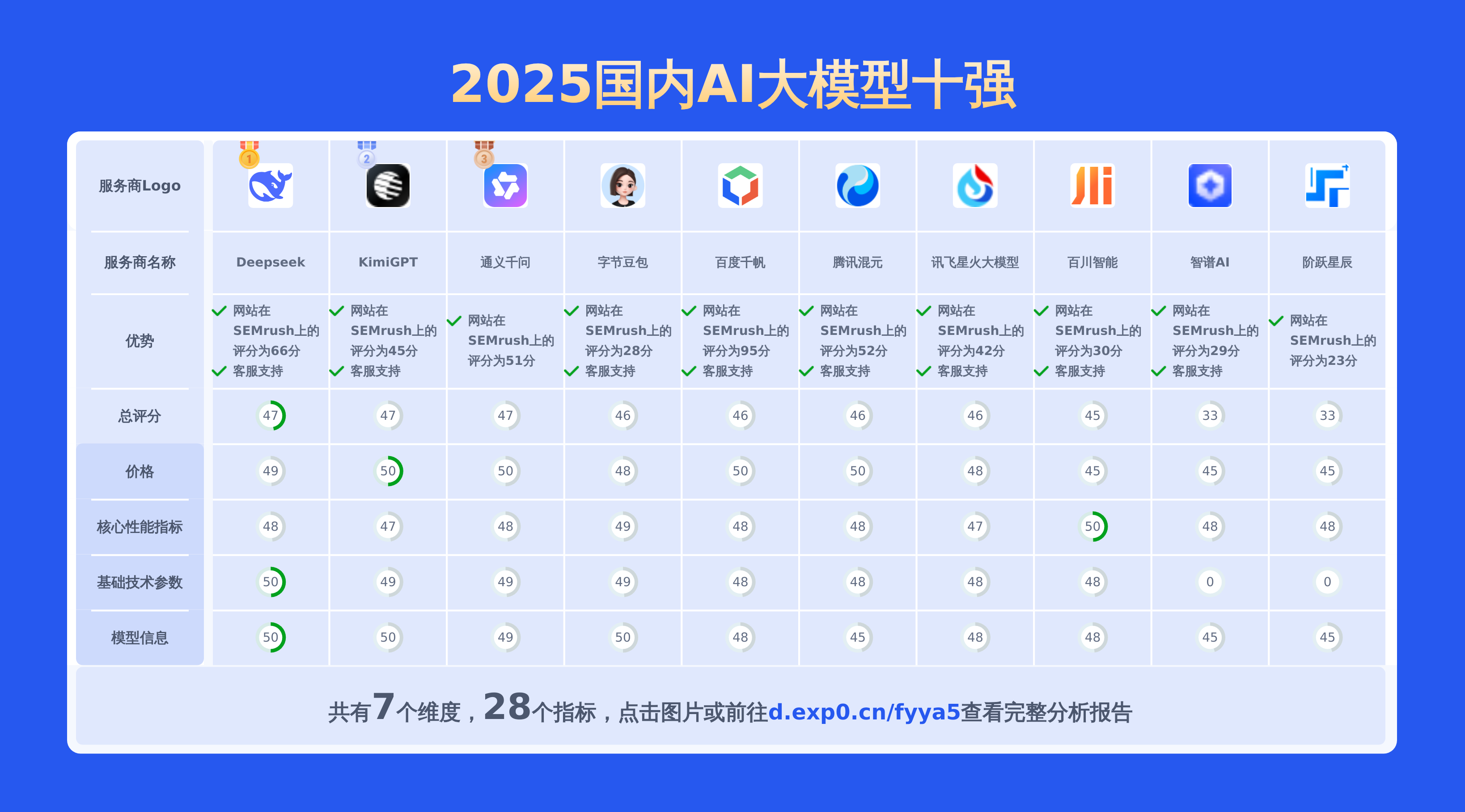
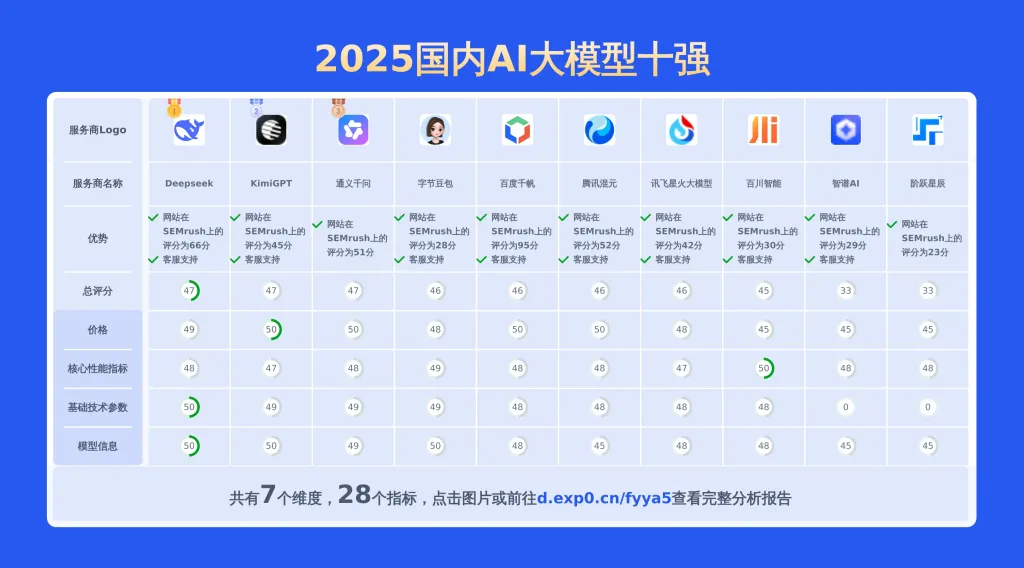
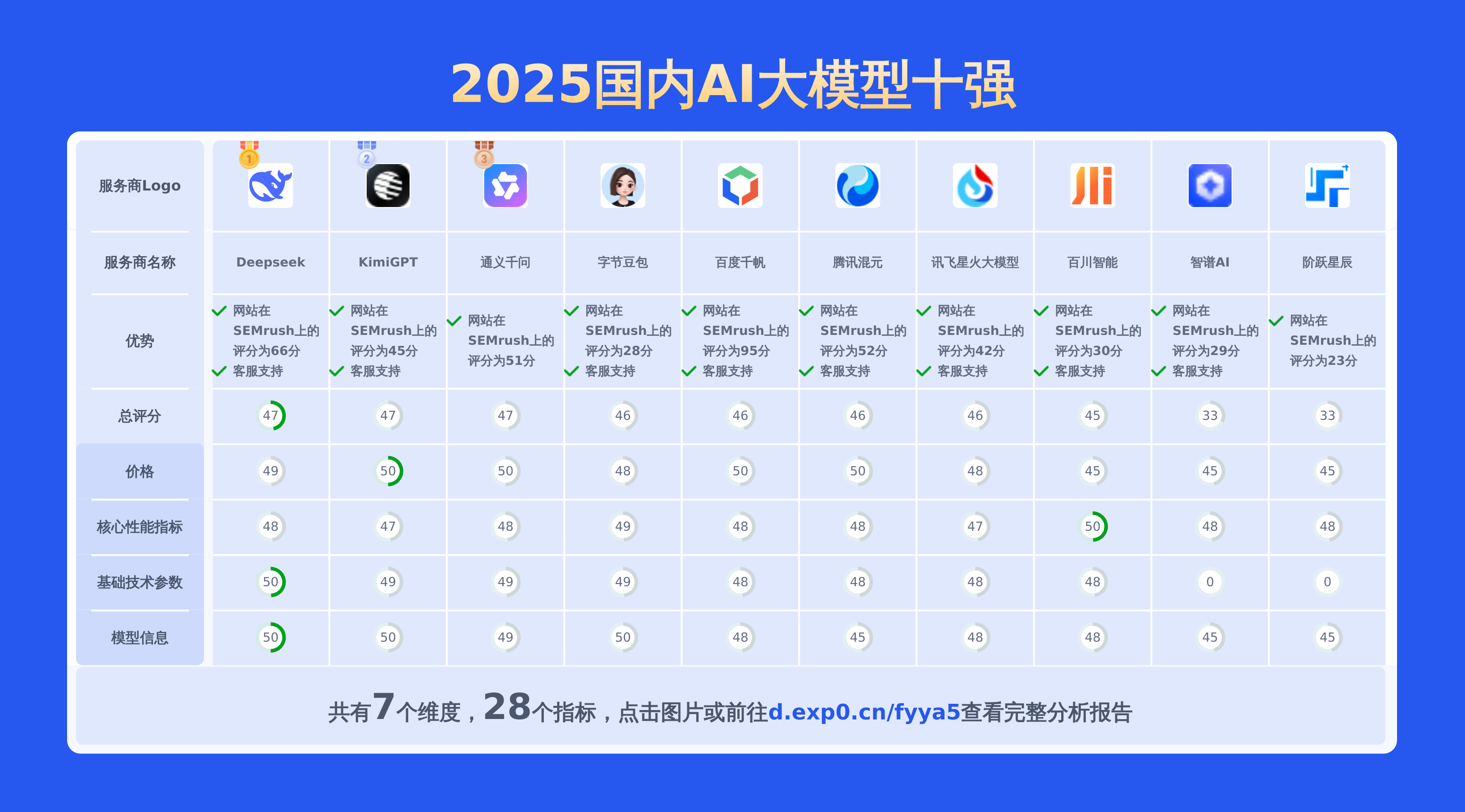
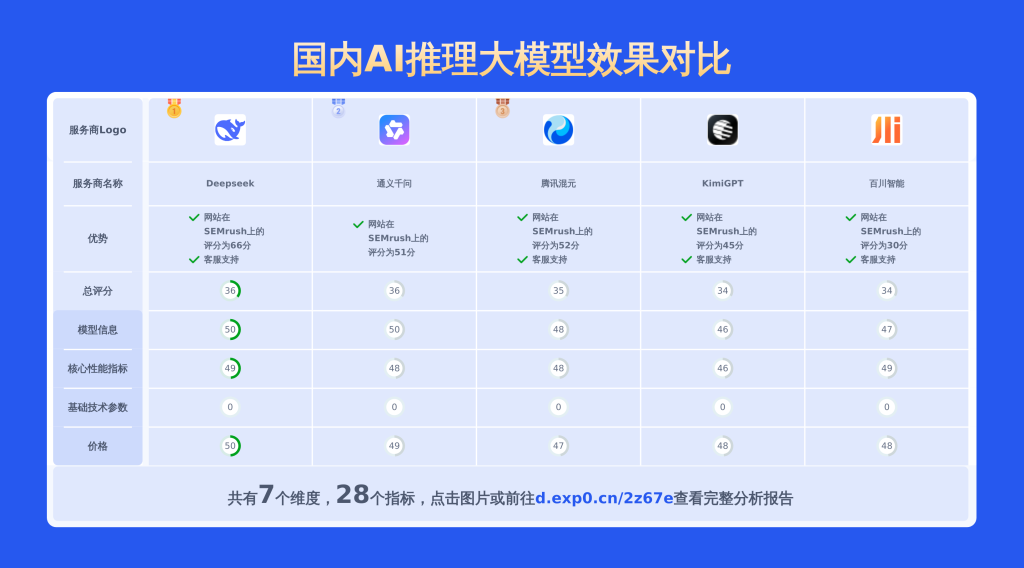
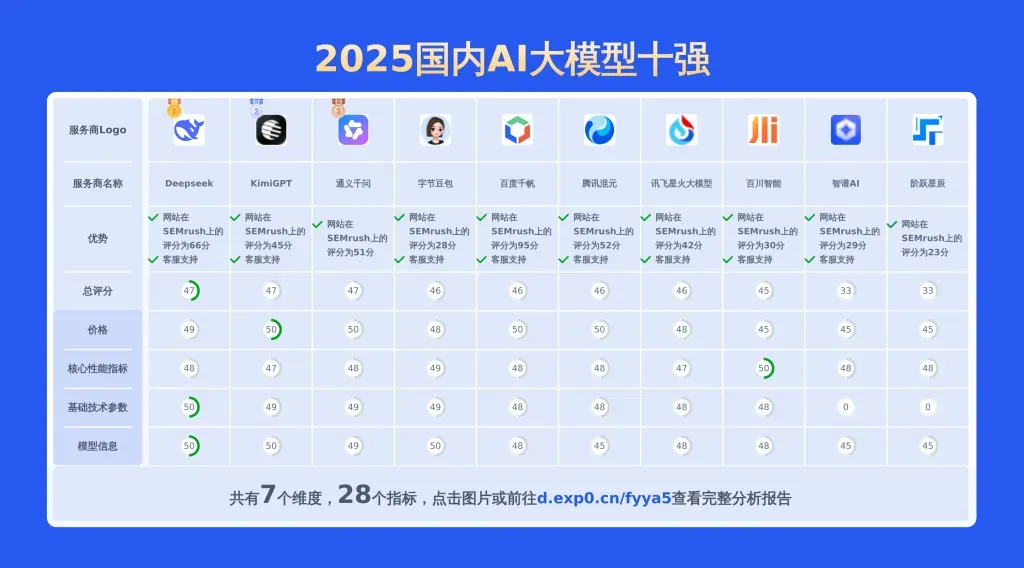
本文对国内大模型通义千问-Max和hunyuan lite进行了全面对比,涵盖产品优势、模型信息、价格及技术参数等28项关键信息,数据均源自官网,旨在为用户提供精准详实的决策依据。 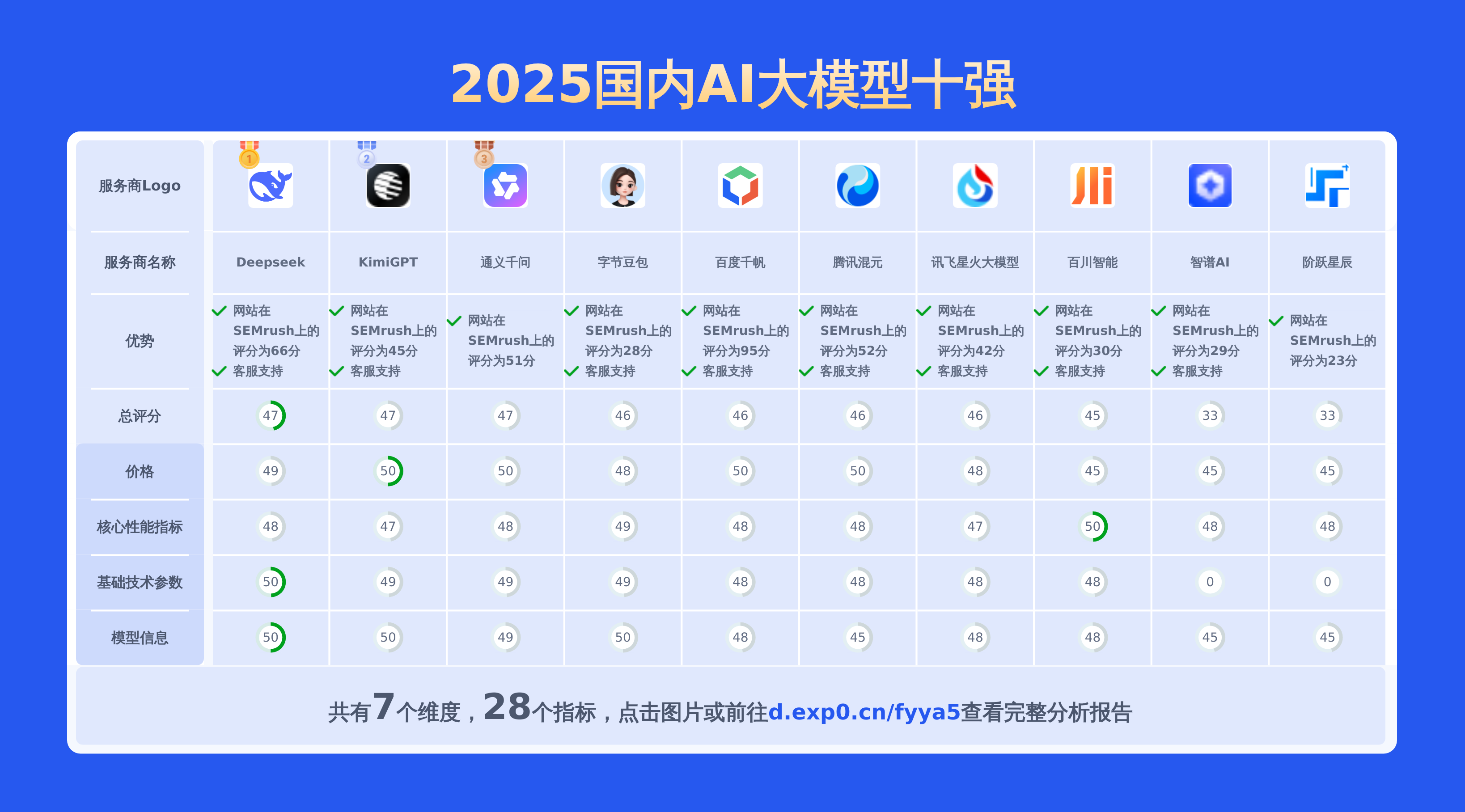
想了解比较报告的深度内容,点此查看完整报告
通义千问-Max
通义千问-Max,即Qwen2.5-Max,是阿里云通义千问旗舰版模型,于2025年1月29日正式发布。该模型预训练数据超过20万亿tokens,在多项公开主流模型评测基准上录得高分,位列全球第七名,是非推理类的中国大模型冠军。它展现出极强劲的综合性能,特别是在数学和编程等单项能力上排名第一。
hunyuan lite
Hunyuan Lite 是腾讯混元大模型的轻量级版本,于2024年10月30日推出。它采用混合专家模型(MoE)结构,支持250K的上下文窗口,最大输入为250k Token,最大输出为6k Token。在中文NLP、英文NLP、代码、数学等多项评测集上表现优异,领先众多开源模型。Hunyuan Lite 适用于对效果、推理性能、成本控制相对平衡的需求场景,能够满足绝大部分用户的日常使用需求。
AI大模型多维度对比分析
1.基础参数对比
| API模型名称 | 输入方式 | 输出方式 | 上下文长度(Token) | 上下文理解 | 文档理解 | 是否支持流式输出 | 是否支持联网搜索 | 是否开源 | 多模态支持 |
|---|---|---|---|---|---|---|---|---|---|
| 通义千问-Max | 文本/图片/视频链接 | 文本 | 32k | ✅ | ⚪ | ✅ | ✅ | ❌ | ✅ |
| hunyuan lite | 文本 | 文本 | 256K | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
通义千问-Max和hunyan lite在AI模型中各有特色。通义千问-Max支持多模态输入和流式输出,上文长度较短但支持联网搜索,适应于需要实时响应的场景。hunyan lite上文长度更长,文档理解能力更强,适应于复杂文本处理和长文本需求。总体来看,根据场景需求和上下文处理能力选择合适的模型。
2.API模型价格对比
| API模型名称 | 免费试用额度 | 输入价格(缓存命中) | 输入价格(缓存未命中) | 输出价格 |
|---|---|---|---|---|
| 通义千问-Max | 赠送100万Token额度 | |||
| 有效期:百炼开通后180天内 | ¥0.0024/千Token (¥2.40/1M Tokens) | ¥0.0024/千Token (¥2.40/1M Tokens) | ¥0.0096/千Token (¥9.60/1M Tokens) | |
| hunyuan lite | 10万tokens 的免费额度(有效期12个月) | ¥0.005/千Token (¥5.00/1M Tokens) | ¥0.005/千Token (¥5.00/1M Tokens) | ¥0.015/千Token (¥15.00/1M Tokens) |
通义千问-Max和hunyuan lite均提供免费试用额度,通义千问-Max在输入和输出价格上均较低,具有成本优势。hunyuan lite虽然价格稍高,但免费额度有效期长达12个月。建议对成本敏感的用户选择通义千问-Max,而对长期稳定性有要求的用户可选择hunyuan lite。
3.核心性能指标对比
| API模型名称 | API可用性(近90天) | 并发数限制 | 生成速度(字/秒) | 训练数据量(参数) |
|---|---|---|---|---|
| 通义千问-Max | ⚪ | 1200 Tokens/分钟 | 约1200字/秒 | 超过20万亿Token数据 |
| hunyuan lite | 0.9986 | 输入4000 Tokens/分钟,输出不超过 2000 Tokens/分钟 | 短文本生成(≤50字):220-260字/秒 | |
| 中长文本生成(50-200字):180-220字/秒 | ||||
| 复杂逻辑输出(带格式):120-160字/秒 | 0.01万亿Token数据 |
在对比分析中,通义千问-Max以高生成速度和超大规模的训练数据量在大规模文本生成中占优势;而Hunyuan Lite在不同文本长度和逻辑输出中表现均衡,尤其在短文本生成中速度突出。建议在需要快速生成简短文本时选择Hunyuan Lite,在处理长文本和大规模数据时优选通义千问-Max。
总结
上面重点对比了通义千问-Max和hunyuan lite,若要查看其他2025国内AI大模型对比情况包括百川智能,讯飞星火大模型,阶跃星辰,百度千帆,智谱AI,Deepseek,通义千问,KimiGPT,腾讯混元,字节豆包等主流供应商。请点此查看完整报告或可以自己选择期望的服务商制作比较报告