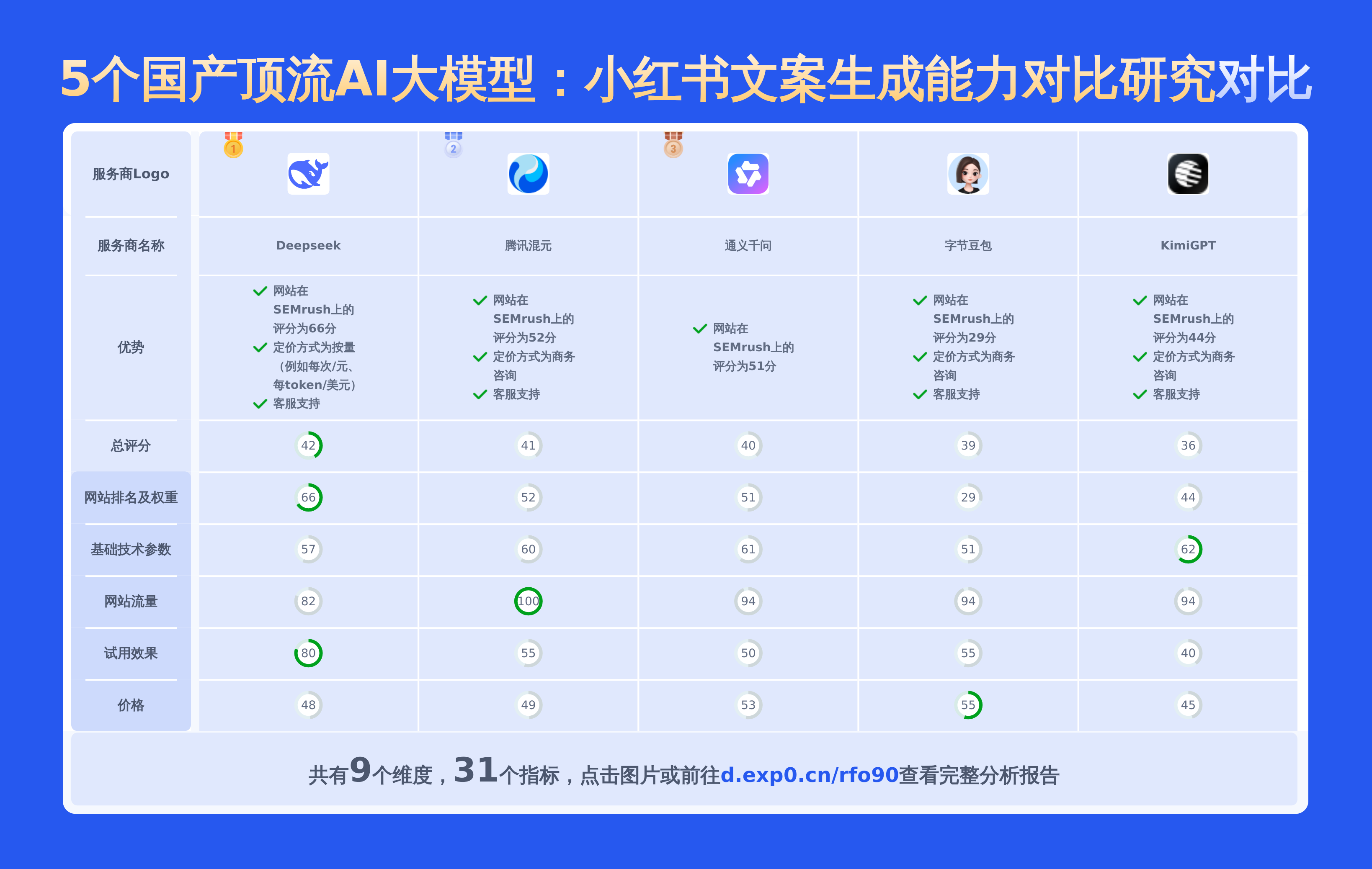
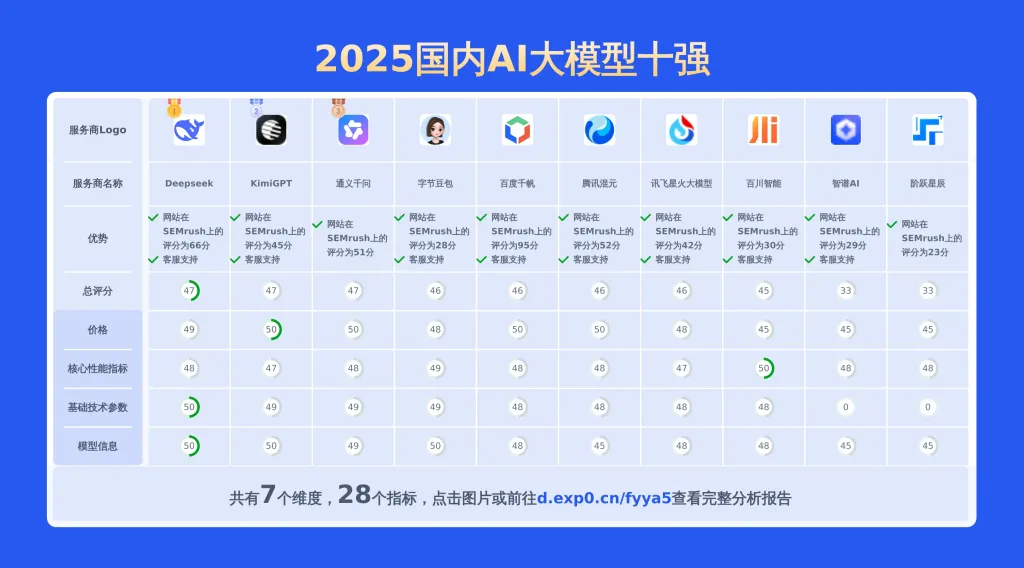
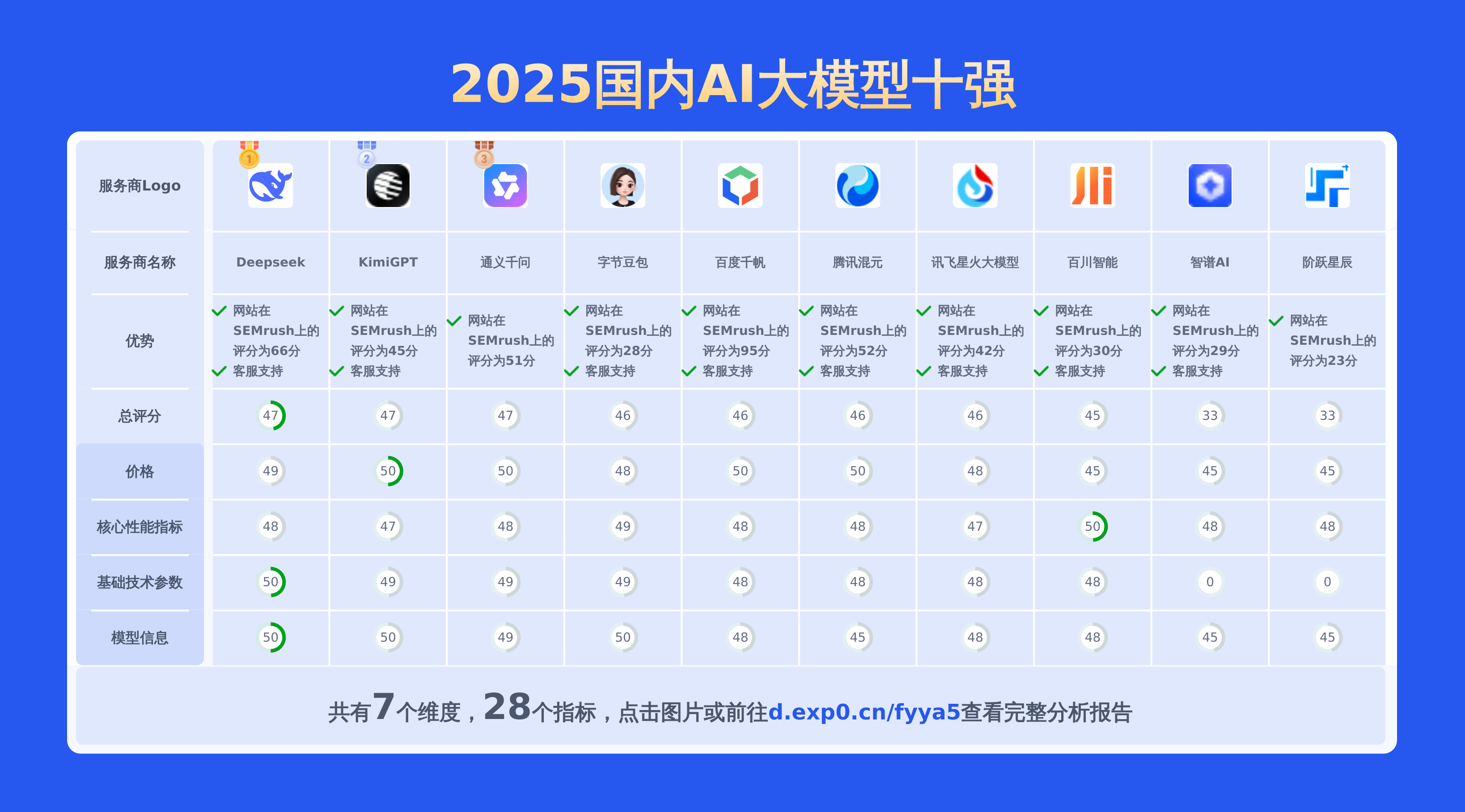
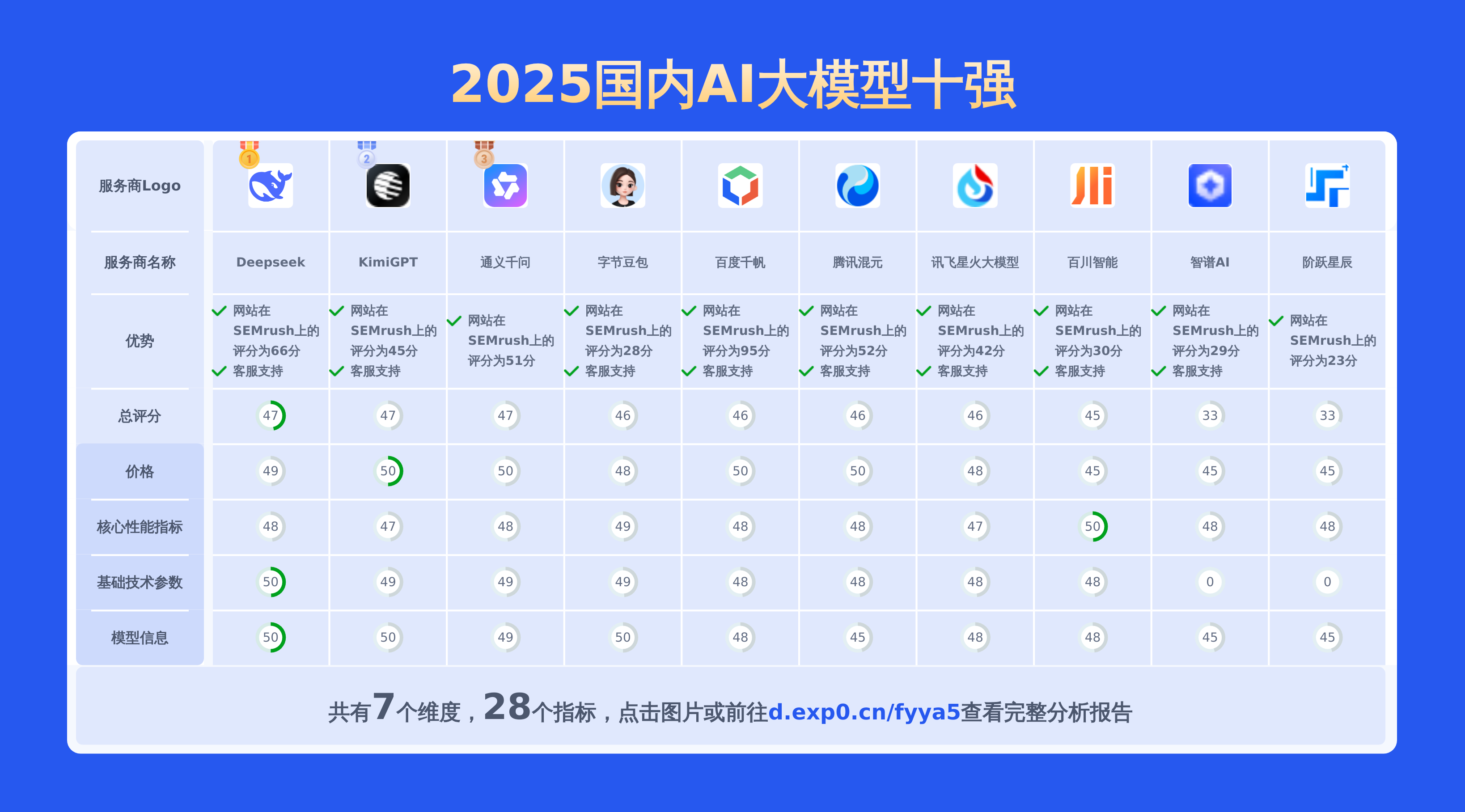
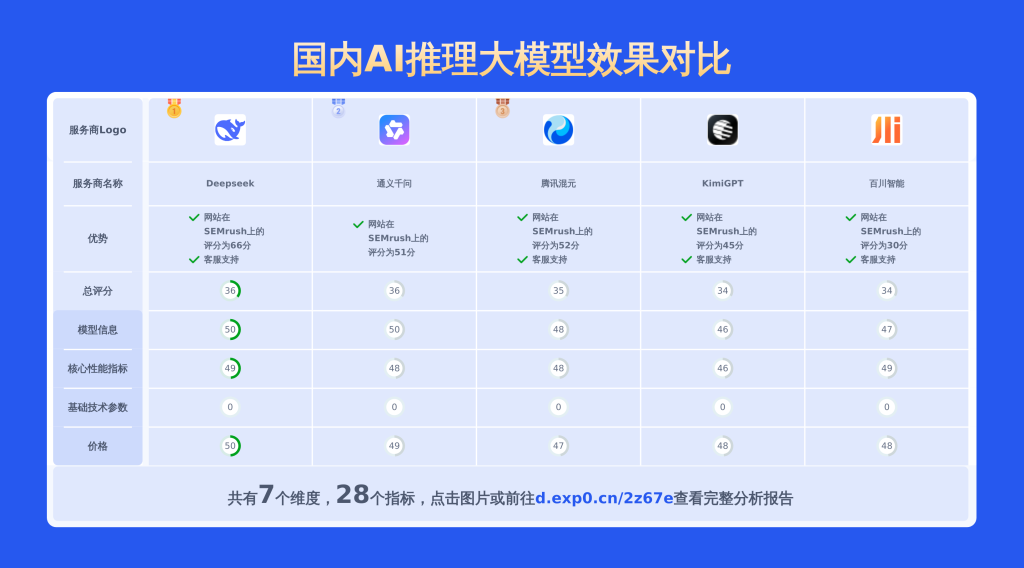
本文对国内大模型moonshot-v1-32k、通义千问-Max和Doubao 1.5 pro进行了全面对比,涵盖产品优势、模型信息、价格及技术参数等28项关键信息,数据均源自官网,旨在为用户提供精准详实的决策依据。
想了解比较报告的深度内容,点此查看完整报告
moonshot-v1-32k
Moonshot-v1-32k是Moonshot AI推出的一款千亿参数的语言模型,支持32K上下文窗口,特别适合长文本的理解和内容生成场景。它具备优秀的语义理解、指令遵循和文本生成能力,能够根据用户输入生成相应的文本输出,广泛应用于内容创作、代码生成、文本摘要等领域。
通义千问-Max
通义千问-Max,即Qwen2.5-Max,是阿里云通义千问旗舰版模型,于2025年1月29日正式发布。该模型预训练数据超过20万亿tokens,在多项公开主流模型评测基准上录得高分,位列全球第七名,是非推理类的中国大模型冠军。它展现出极强劲的综合性能,特别是在数学和编程等单项能力上排名第一。
Doubao 1.5 pro 256k
Doubao 1.5 pro 256k 是字节跳动推出的豆包大模型的升级版本,基于稀疏 MoE 架构,性能杠杆达 7 倍,仅用稠密模型七分之一的参数量就超越了 Llama-3.1-405B 等大模型的性能。它支持 256k 上下文窗口的推理,输出长度最大支持 12k tokens,在推理和创作任务中表现出色。该模型在多模态任务上也有显著提升,视觉推理和文档识别能力增强,可处理复杂场景下的图像和文档,为用户提供更自然、更丰富的交互体验。此外,Doubao 1.5 pro 256k 在知识、代码、推理、中文等多个测评基准上表现优于 GPT-4o 和 Claude 3.5 Sonnet。
AI大模型多维度对比分析
1.基础参数对比
| --- |
|---|
各AI大模型侧重不同,moonshot-v1-32k适合文本代码处理、单轮对话;通义千问-Max支持跨模态关联推理,适合文档理解与搜索;Doubao 1.5 pro 256k则在文本处理上具有更长上下文长度优势。综合考虑模型特性和需求场景选择合适的模型。
2.API模型价格对比
| --- |
|---|
| 有效期:180天 |
| 有效期:百炼开通后180天内 |
在AI大模型对比中,moonshot-v1-32k、通义千问-Max和Doubao 1.5 pro 256k均提供免费试用额度,价格相对接近。其中,通义千问-Max的输入价格最低,性价比较高。moonshot-v1-32k和Doubao 1.5 pro 256k的输出价格较高。建议根据输入需求、价格敏感度和预算,合理选择模型,以获得最佳性能和成本效益。
3.核心性能指标对比
| --- |
|---|
各AI大模型在可用性、并发限制和生成速度方面表现不同。moonshot-v1-32k以高速度和丰富训练数据为优势,适合需要快速响应和大数据训练的应用场景;通义千问-Max以其卓越的并发和生成速度,适合高频、高负载的查询处理;Doubao 1.5 pro 256k则以高可用性和适中的并发限制,适合稳定性要求高的应用。
总结
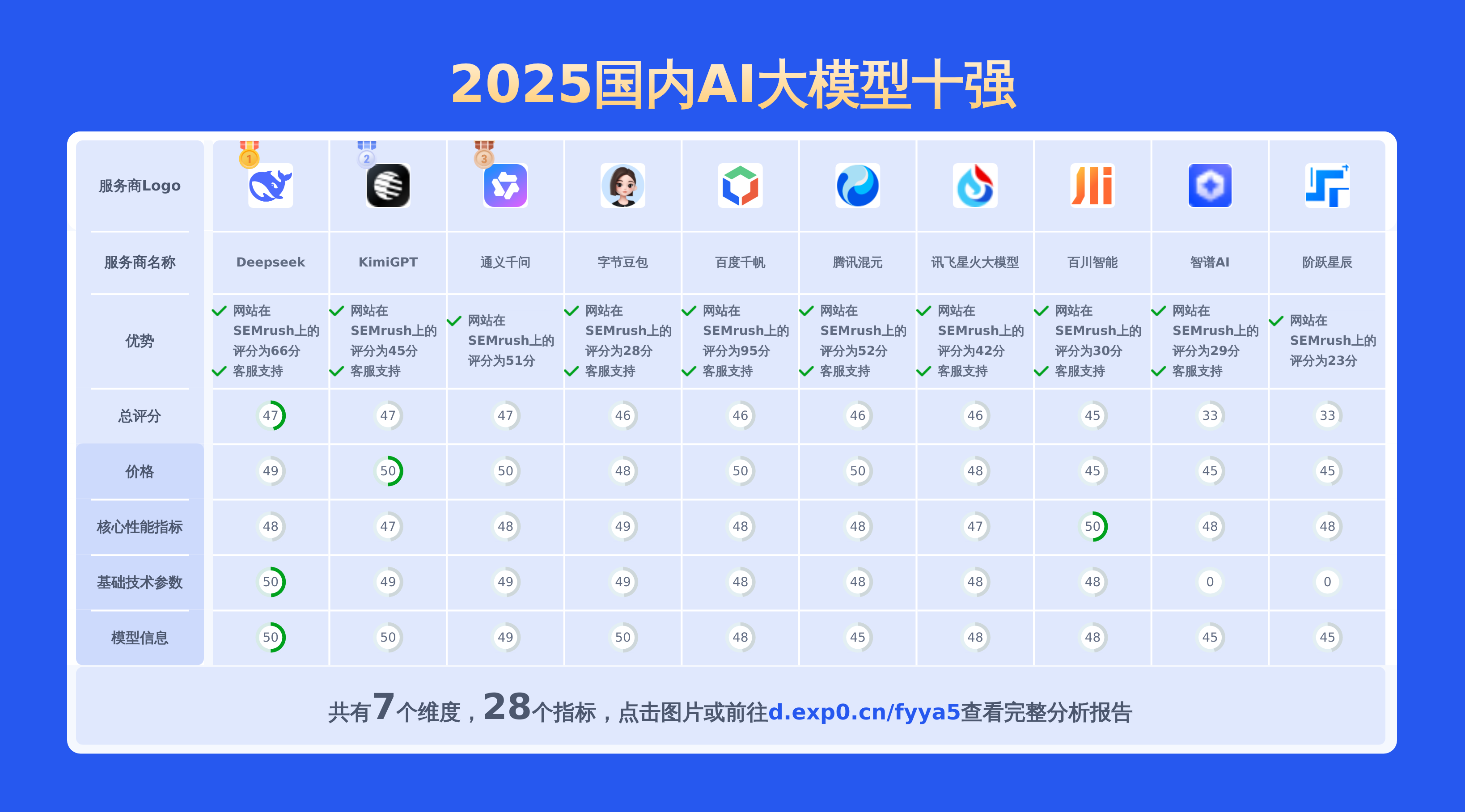
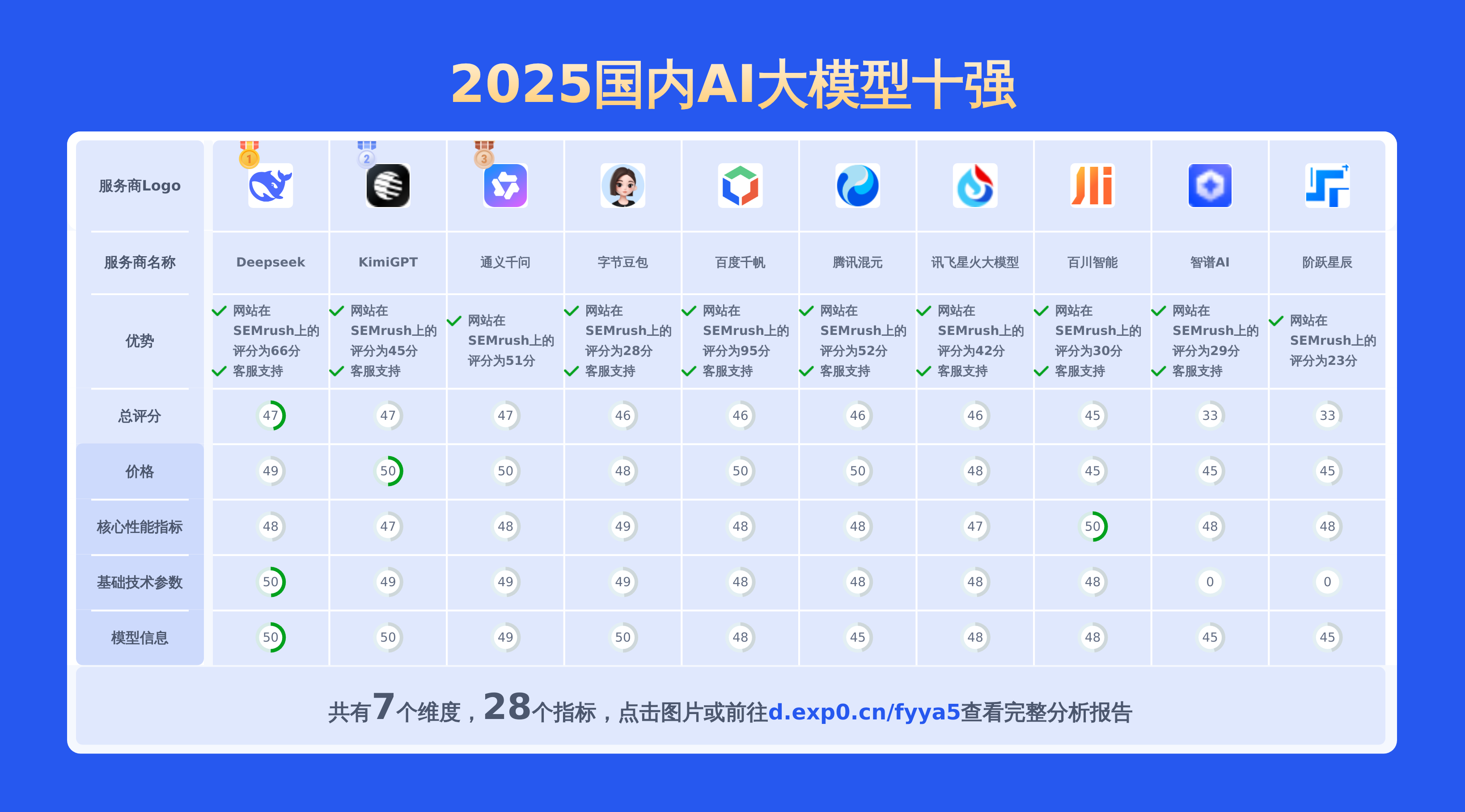
上面重点对比了moonshot-v1-32k、通义千问-Max以及doubao 1.5 pro,从API价格对比,通义千问-Max的输入价格最低,性价比较高。若要查看其他2025国内AI大模型对比情况包括百川智能,讯飞星火大模型,阶跃星辰,百度千帆,智谱AI,Deepseek,通义千问,KimiGPT,腾讯混元,字节豆包等主流供应商。请点此查看完整报告或可以自己选择期望的服务商制作比较报告