
背景
阿里云RDS FOR MySQL(MySQL5.7版本)数据库业务表每月新增数据量超过千万,随着数据量持续增加,我们业务出现大表慢查询,在业务高峰期主业务表的慢查询需要几十秒严重影响业务
方案概述
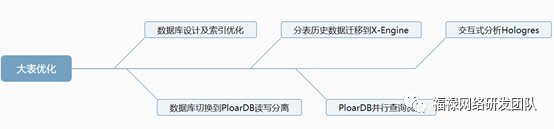
一、数据库设计及索引优化
MySQL数据库本身高度灵活,造成性能不足,严重依赖开发人员的表设计能力以及索引优化能力,在这里给几点优化建议
时间类型转化为时间戳格式,用int类型储存,建索引增加查询效率
建议字段定义not null,null值很难查询优化且占用额外的索引空间
使用TINYINT类型代替枚举ENUM
存储精确浮点数必须使用DECIMAL替代FLOAT和DOUBLE
字段长度严重根据业务需求来,不要设置过大
尽量不要使用TEXT类型,如必须使用建议将不常用的大字段拆分到其它表
MySQL对索引字段长度是有限制的, innodb引擎的每个索引列长度默认限制为767字节(bytes),所有组成索引列的长度和不能大于3072字节(mysql8.0单索引可以创建1024字符)
大表有DDL需求时请联系DBA
最左索引匹配规则
顾名思义就是最左优先,在创建组合索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。复合索引很重要的问题是如何安排列的顺序,比如where后面用到c1, c2 这两个字段,那么索引的顺序是(c1,c2)还是(c2,c1)呢,正确的做法是,重复值越少的越放前面,比如一个列 95%的值都不重复,那么一般可以将这个列放最前面
复合索引index(a,b,c)
where a=3 只使用了a
where a=3 and b=5 使用了a,b
where a=3 and b=5 and c=4 使用了a,b,c
where b=3 or where c=4 没有使用索引
where a=3 and c=4 仅使用了 a
where a=3 and b>10 and c=7 使用了a,b
where a=3 and b like ‘xx%’ and c=7 使用了a,b
其实相当于创建了多个索引:key(a)、key(a,b)、key(a,b,c)
二、数据库切换到PloarDB读写分离
PolarDB是阿里云自研的下一代关系型云数据库,100%兼容MySQL存储容量最高可达100 TB,单库最多可扩展到16个节点,适用于企业多样化的数据库应用场景。PolarDB采用存储和计算分离的架构,所有计算节点共享一份数据,提供分钟级的配置升降级、秒级的故障恢复、全局数据一致性和免费的数据备份容灾服务。
集群架构,计算与存储分离
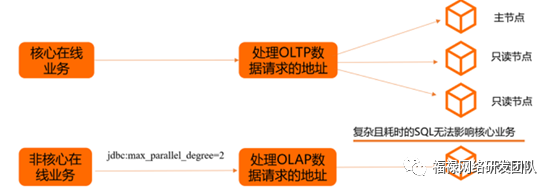
PolarDB采用多节点集群的架构,集群中有一个Writer节点(主节点)和多个Reader节点(只读节点),各节点通过分布式文件系统(PolarFileSystem)共享底层的存储(PolarStore)读写分离
当应用程序使用集群地址时,PolarDB通过内部的代理层(Proxy)对外提供服务,应用程序的请求都先经过代理,然后才访问到数据库节点。代理层不仅可以做安全认证和保护,还可以解析SQL,把写操作(例如事务、UPDATE、INSERT、DELETE、DDL等)发送到主节点,把读操作(例如SELECT)均衡地分发到多个只读节点,实现自动的读写分离。对于应用程序来说,就像使用一个单点的数据库一样简单。
在离线混合场景:不同业务用不同的连接地址,使用不同的数据节点,避免相互影响
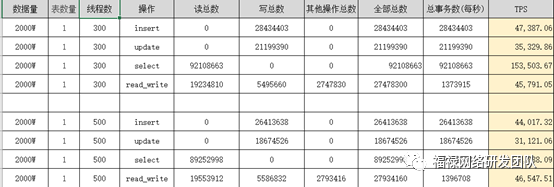
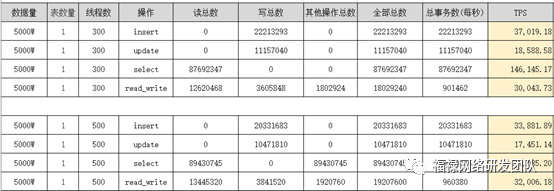
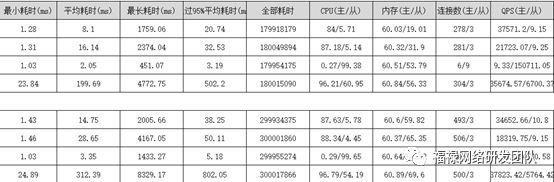
Sysbench性能压测报告:
- PloarDB 4核16G 2台
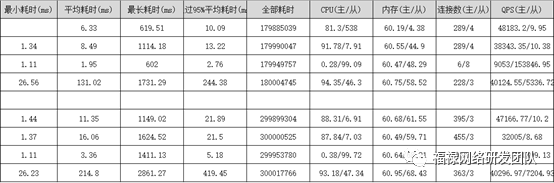
- PloarDB 8核32G 2台
三、分表历史数据迁移到MySQL8.0 X-Engine存储引擎
分表业务表保留3个月数据(这个根据公司需求来),历史数据按月分表到历史库X-Engine存储引擎表, 为什么要选用X-Engine存储引擎表,它有什么优点?
节约成本, X-Engine的存储成本约为InnoDB的一半
X-Engine分层存储提高QPS, 采用层次化的存储结构,将热数据与冷数据分别存放在不同的层次中,并默认对冷数据所在层次进行压缩
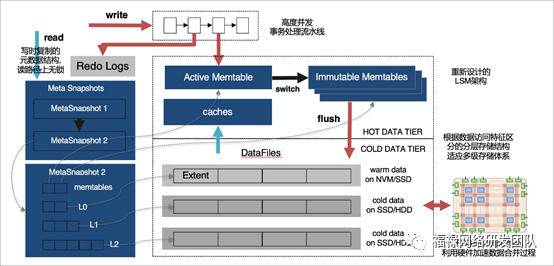
X-Engine是阿里云数据库产品事业部自研的联机事务处理OLTP(On-Line Transaction Processing)数据库存储引擎。
X-Engine存储引擎不仅可以无缝对接兼容MySQL(得益于MySQL Pluginable Storage Engine特性),同时X-Engine使用分层存储架构。因为目标是面向大规模的海量数据存储,提供高并发事务处理能力和降低存储成本,在大部分大数据量场景下,数据被访问的机会是不均等的,访问频繁的热数据实际上占比很少,X-Engine根据数据访问频度的不同将数据划分为多个层次,针对每个层次数据的访问特点,设计对应的存储结构,写入合适的存储设备
X-Engine使用了LSM-Tree作为分层存储的架构基础,并进行了重新设计:
热数据层和数据更新使用内存存储,通过内存数据库技术(Lock-Free index structure/append only)提高事务处理的性能。
流水线事务处理机制,把事务处理的几个阶段并行起来,极大提升了吞吐。
访问频度低的数据逐渐淘汰或是合并到持久化的存储层次中,并结合多层次的存储设备(NVM/SSD/HDD)进行存储。
对性能影响比较大的Compaction过程做了大量优化:
拆分数据存储粒度,利用数据更新热点较为集中的特征,尽可能的在合并过程中复用数据。
精细化控制LSM的形状,减少I/O和计算代价,有效缓解了合并过程中的空间增大。
同时使用更细粒度的访问控制和缓存机制,优化读的性能。
四、阿里云PloarDB MySQL8.0版本并行查询
分表之后我们的数据量依然很大,并没有完全解决我们的慢查询问题,只是降低了我们业务表的体量,这部分慢查询我们需要用到PolarDB的并行查询优化
PolarDB MySQL 8.0重磅推出并行查询框架,当您的查询数据量到达一定阈值,就会自动启动并行查询框架,从而使查询耗时指数级下降
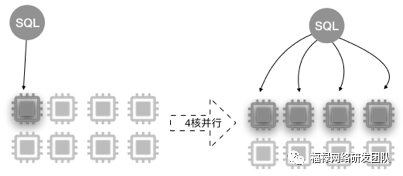
在存储层将数据分片到不同的线程上,多个线程并行计算,将结果流水线汇总到总线程,最后总线程做些简单归并返回给用户,提高查询效率。
并行查询(Parallel Query)利用多核CPU的并行处理能力,以8核32 GB配置为例,示意图如下所示。
并行查询适用于大部分SELECT语句,例如大表查询、多表连接查询、计算量较大的查询。对于非常短的查询,效果不太显著。
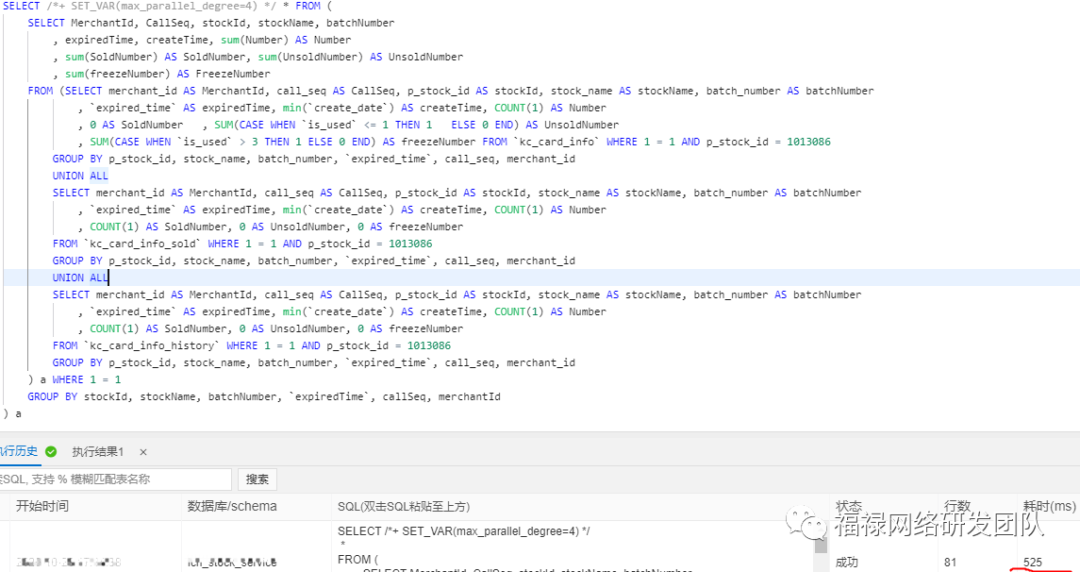
并行查询用法,使用Hint语法可以对单个语句进行控制,例如系统默认关闭并行查询情况下,但需要对某个高频的慢SQL查询进行加速,此时就可以使用Hint对特定SQL进行加速。
SELECT /+PARALLEL(x)/ … FROM …; – x >0
SELECT /+ SET_VAR(max_parallel_degree=n) / * FROM … // n > 0
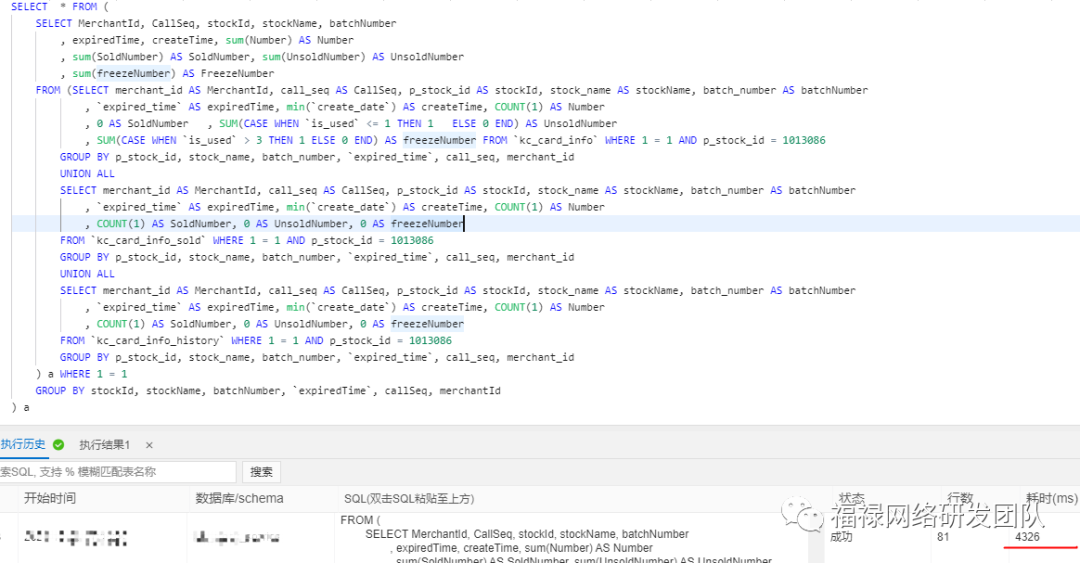
查询测试:数据库配置 16核32G 单表数据量超3千万
没加并行查询之前是4326ms,加了之后是525ms,性能提升8.24倍
五、交互式分析Hologre
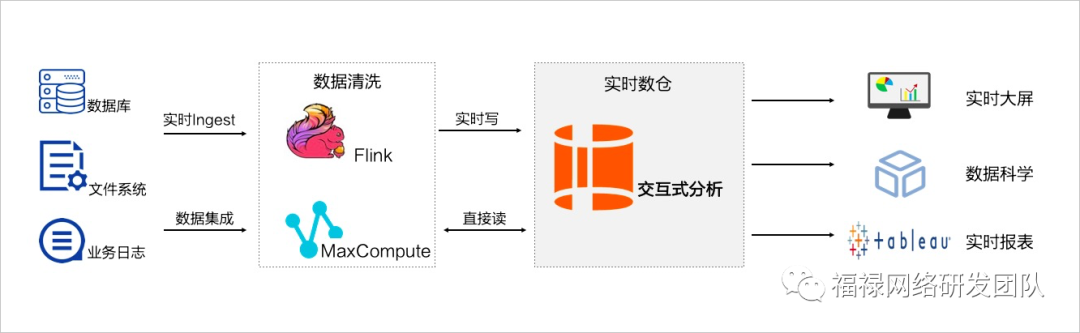
大表慢查询我们虽然用并行查询优化提升了效率,但是一些特定的需求实时报表、实时大屏我们还是无法实现,只能依赖大数据去处理。
这里推荐大家阿里云的交互式分析Hologre(
https://help.aliyun.com/product/113622.html)
六、后记
千万级大表优化是根据业务场景,以成本为代价优化的,不是一上来就数据库水平切分扩展,这样会给运维和业务带来巨大挑战,很多时候效果不一定好,我们的数据库设计、索引优化、分表策略是否做到位了,应该根据业务需求选择合适的技术去实现。
点个“在看”支持一下👇
本文分享自微信公众号 - 测试开发社区(TestDevHome)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












