
数据库系统设计:分区
术语澄清
分区 (partition),对应 MongoDB、ES 中的 shard,HBase 的 Region,Bigtable 的 tablet,Cassandra 的 vnode,Couchbase 的 vBucket。但分区 (partitioning) 是最普遍的。
定义
每条数据(或每条记录,每行或每个文档)属于且仅属于某特定分区。每个分区都能视为一个完整小型数据库,虽然数据库可能存在跨分区操作。
目的
提高可扩展性。不同分区可放在一个无共享集群的不同节点。这样的一个大数据集可分散在更多磁盘,查询负载也随之分布到更多处理器。
单分区查询时,每个节点对自己所在分区查询可独立执行查询操作,添加更多节点就能提高查询吞吐量。大型复杂查询尽管比较困难,但也可能做到跨节点的并行处理。
分区数据库在 20 世纪 80 年代由 Teradata 和 NonStop SQL 等产品率先推出,最近因 NoSQL 和基于 Hadoop 的数据仓库重新被关注。有些系统是为事务处理而设计,有些系统则用于分析:这种差异会影响系统的运作方式,但是分区的基本原理均适用于这两种工作方式。
在本章中,我们将首先介绍分割大型数据集的不同方法,并观察索引如何与分区配合。然后讨论 rebalancing,若想添加、删除集群中的节点,则必须进行再 rebalancing。最后,概述 DB 如何将请求路由到正确的分区并执行查询。
1 分区与复制
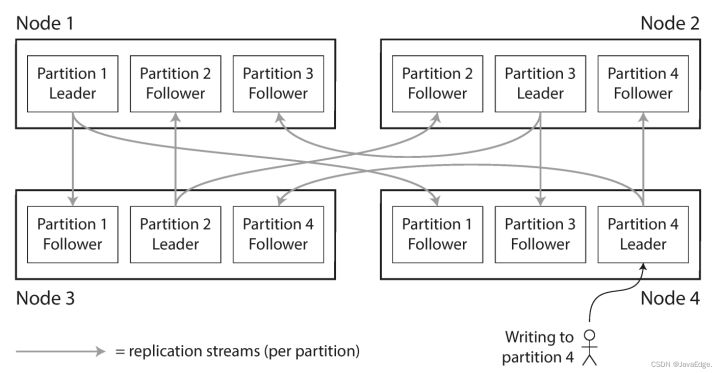
分区一般和复制搭配使用,即每个分区的多个节点都有副本。这意味着,某条记录属于特定的分区,而同样内容会存储在不同的节点上,以提高系统容错性。
一个节点可能存储多个分区。如图 - 1 所示,主从复制模型和分区组合时数据的分布情况。每个分区都有自己的主副本,如被分配给某节点,而从库副本被分配给其他节点。一个节点可能是某些分区的主副本,同时也是其他分区的从副本。
上一个文章讨论的复制相关所有内容同样适用于分区数据的复制。考虑到分区方案的选择通常独立于复制,为简单起见,本文忽略复制相关内容。
2 KV 数据的分区
海量数据想切分,如何决定在哪些节点上存储哪些记录?
分区的主要目标:将数据和查询负载均匀分布在各节点。若每个节点平均分担数据和负载,则理论上 10 个节点能处理 10 倍的数据量和 10 倍于单节点的读写吞吐量(暂忽略复制)。
但若分区不均,则会导致某些分区节点比其他分区有更多数据量或查询负载,即倾斜,这会导致分区效率下降很多。极端情况下,所有负载可能压在一个分区节点,其余 9 个节点空闲,系统瓶颈落在这最忙的节点。这时的高负载分区即是系统热点。
2.1 避免热点
最简单的,将记录随机分配给所有节点。这能在所有节点比较均匀分布数据,但缺点是:试图读取特定数据时,不知道保存在哪个节点,必须并行查询所有节点。
可以优化该方案。假设数据是简单的 KV 数据模型,即总能通过 K 访问记录。如在一本百科全书,可通过标题查找一个条目;而所有条目按字母序排序,因此能快速找到目标条目。
2.2 根据 K 的范围分区(Key Range 分区策略)
一种分区方案,为每个分区指定一块连续的 K 范围(以 min 和 max 指示),如纸质百科全书的卷(图 - 2)。若知道 K 区间的边界,就能轻松确定哪个分区包含这些 K。若你还知道分区所在的节点,则可直接请求相应节点(就像从书架上选取正确书籍)。
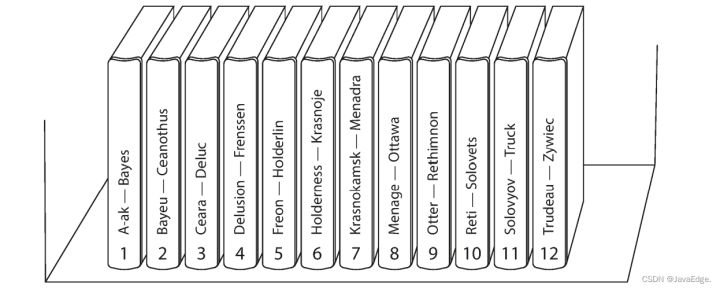
K 的区间不一定要均匀分布,因为数据本身可能就不均匀。如图 - 2 中,1 卷包含 A、B 开头的单词,但 12 卷则包含 T、U、V、X、Y 和 Z 开头单词。若只是简单规定每个卷包含两个字母,可能导致一些卷比其他卷大。为更均匀分布数据,分区的边界应适配数据本身的分布特征。
分区边界可由管理员手动确定或由 DB 自动选择。Bigtable 及其开源版本 HBase 和 2.4 版本之前的 MongoDB 都采用该分区策略。
每个分区中,可按 K 排序保存。范围扫描就很简单,将 K 作为联合索引来处理,从而在一次查询中获取多个相关记录。假设有个程序存储网络传感器的数据,K 是测量的时间戳(年月日 - 时分秒)。范围扫描此时很有用,可快速获取某月内的所有数据。
缺点
某些访问模式会导致热点。 若 K 是时间戳,则分区对应于一个时间范围,如每天一个分区。 测量数据从传感器写入 DB 时,所有写入操作都集中在同一分区(即当天的分区),导致该分区在写入时处于高负载,而其他分区始终空闲。
为避免该问题,需要使用时间戳之外的内容作为 K 的第一项。 可考虑每个时间戳前添加传感器名称,这样首先按传感器名称,再按时间进行分区。假设多个传感器同时运行,则写入负载最终会均匀分布在多个节点。 当想要获取一个时间范围内、多个传感器的数据,可根据传感器名称,各自执行单独的范围查询。
2.3 根据键的 Hash 分区
由于数据倾斜和热点问题,许多分布式系统采用基于 K 散列函数来分区。
好的散列函数可处理倾斜数据并使其均匀分布。
数据分区目的的 hash 函数无需健壮的加密能力,如 Cassandra 和 MongoDB 使用 MD5。许多编程语言也有内置的简单哈希函数(主要用于哈希表),但可能不适合分区:如 Java 的 Object.hashCode (),同一 K 可能在不同进程中有不同哈希值。
确定合适的 hash 函数后,就能为每个分区分配一个 hash 范围(而不是直接就是 K 的范围),每个 K 通过 hash 散列落在不同分区,如图 - 3:
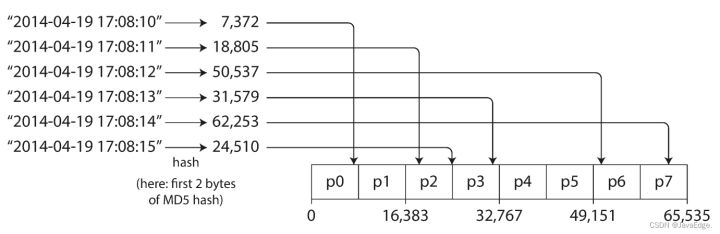
这种方案擅长在分区之间均匀分配 K。分区边界可以是均匀间隔,也可以是伪随机选择(也称为一致性哈希)。
一致性哈希
一种平均分配自己负载的方法,最初用于内容分发网络(CDN)等互联网缓存系统。 采用随机选择的分区边界来规避中央控制或分布式共识。此处的一致性与副本一致性或 ACID 一致性无任何关联 ,它只描述了数据动态平衡的一种方法。
正如 “分区再平衡” 中所见,这种特殊分区方法对于 DB 实际上效果并非很好,所以目前很少使用(虽然某些 DB 的文档仍会使用一致性哈希说法,但其实不准确)。 因为有可能产生混淆,所以最好避免使用一致性哈希这个术语,而只是把它称为 散列分区(hash partitioning)。
但通过 hash 分区,失去高效的执行范围查询的能力:即使相邻的 K,经过 hash 后也会分散在不同分区。MongoDB 中,若使用 hash 分区,则范围查询都必须发送到所有分区。而 Couchbase 或 Voldemort 干脆直接不支持 K 的范围查询。
Cassandra 在两种分区策略之间采取折中。 Cassandra 的表可使用由多个列组成的复合主键。键中只有第一部分可用于 hash 分区,而其他列则被用作 Casssandra 的 SSTables 中排序数据的联合索引。尽管不支持复合主键的第一列的范围查询,但若第一列已指定固定值,则可对其他列执行高效的范围查询。
联合索引为一对多关系提供一个优雅的数据模型。如社交网站,一个用户可能发布很多消息更新。若更新的 K 被设置为 (user_id,update_timestamp),则能高效检索某用户在某时间段内,按时间戳排序的所有更新。不同用户可存储在不同分区,但对某一用户,消息会按时间戳顺序存储在同一分区。
2.4 负载偏斜与热点消除
hash 分区可减少热点,但无法完全避免:极端情况下,所有读 / 写操作都是针对同一 K,则所有请求都会被路由到同一分区。
这种负载也许不常见,但也并非不可能:如社交网站,一个坐拥百万粉丝的大 V 用户,发布一些热点事件时,可能引发一场访问风暴。导致同一个 K 的大量写操作(K 可能是大 V 的用户 ID 或人们正在评论的事件 ID)。此时,hash 策略不起任何作用,因为两个相同 ID 的 hash 值仍相同。
如今,大多数据系统仍无法自动消除这种高度偏斜的负载,只能通过应用层来减少倾斜。如某 K 被确认为热点,简单方法是在 K 的开始或结尾添加一个随机数。只要一个两位数的十进制随机数就能将主键分散为 100 种不同的 K,从而存储在不同分区。
但之后的任何读取都要做额外工作,必须从所有 100 个 K 分布中读取数据然后合并。因此通常只对少量热点 K 附加随机数才有意义;而对写吞吐量低的大多数 K,这些都是不必要开销。此外,还需额外元数据来标记哪些 K 进行了特殊处理。
感兴趣的小伙伴可以在3A云服务器上部署环境自己进行测试,也许将来某天,数据系统将能自动检测和处理负载倾斜情况;但当下,仍需你自己来综合权衡策略。




