
Kafka 中的消息是以主题为基本单位进行归类的,各个主题在逻辑上相互独立。每个主题又可以分为一个或多个分区,分区的数量可以在主题创建的时候指定,也可以在之后修改。每条消息在发送的时候会根据分区规则被追加到指定的分区中,分区中的每条消息都会被分配一个唯一的序列号,也就是通常所说的偏移量(offset),具有4个分区的主题的逻辑结构见下图。
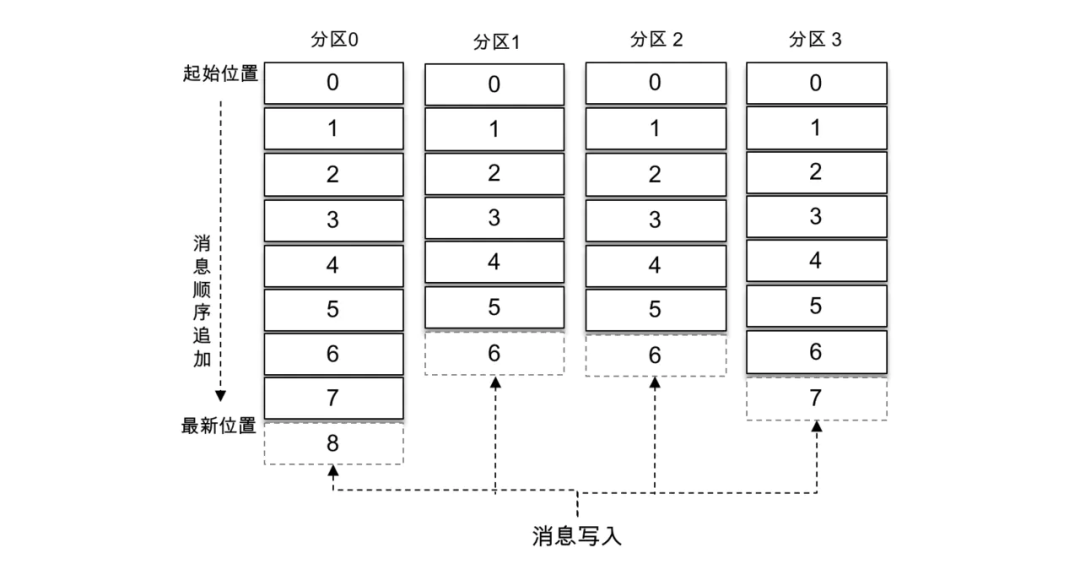
如果分区规则设置得合理,那么所有的消息可以均匀地分布到不同的分区中,这样就可以实现水平扩展。不考虑多副本的情况,一个分区对应一个日志(Log)。为了防止 Log 过大,Kafka 又引入了日志分段(LogSegment)的概念,将 Log 切分为多个 LogSegment,相当于一个巨型文件被平均分配为多个相对较小的文件,这样也便于消息的维护和清理。
事实上,Log 和 LogSegment 也不是纯粹物理意义上的概念,Log 在物理上只以文件夹的形式存储,而每个 LogSegment 对应于磁盘上的一个日志文件和两个索引文件,以及可能的其他文件(比如以“.txnindex”为后缀的事务索引文件)。下图描绘了主题、分区、副本、Log 以及 LogSegment 之间的关系。
接触过 Kafka 的老司机一般都知晓 Log 对应了一个命名形式为
向 Log 中追加消息时是顺序写入的,只有最后一个 LogSegment 才能执行写入操作,在此之前所有的 LogSegment 都不能写入数据。为了方便描述,我们将最后一个 LogSegment 称为“activeSegment”,即表示当前活跃的日志分段。随着消息的不断写入,当 activeSegment 满足一定的条件时,就需要创建新的 activeSegment,之后追加的消息将写入新的 activeSegment。
为了便于消息的检索,每个 LogSegment 中的日志文件(以“.log”为文件后缀)都有对应的两个索引文件:偏移量索引文件(以“.index”为文件后缀)和时间戳索引文件(以“.timeindex”为文件后缀)。每个 LogSegment 都有一个基准偏移量 baseOffset,用来表示当前 LogSegment 中第一条消息的 offset。偏移量是一个64位的长整型数,日志文件和两个索引文件都是根据基准偏移量(baseOffset)命名的,名称固定为20位数字,没有达到的位数则用0填充。比如第一个 LogSegment 的基准偏移量为0,对应的日志文件为00000000000000000000.log。
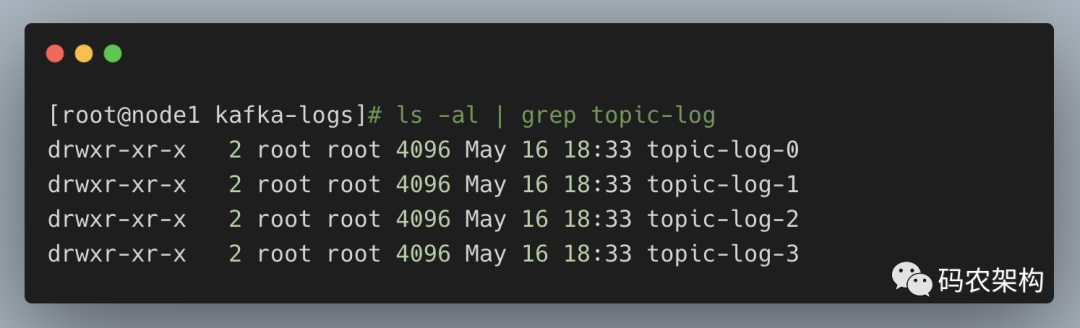
举例说明,向主题topic-log中发送一定量的消息,某一时刻topic-log-0目录中的布局如下所示。
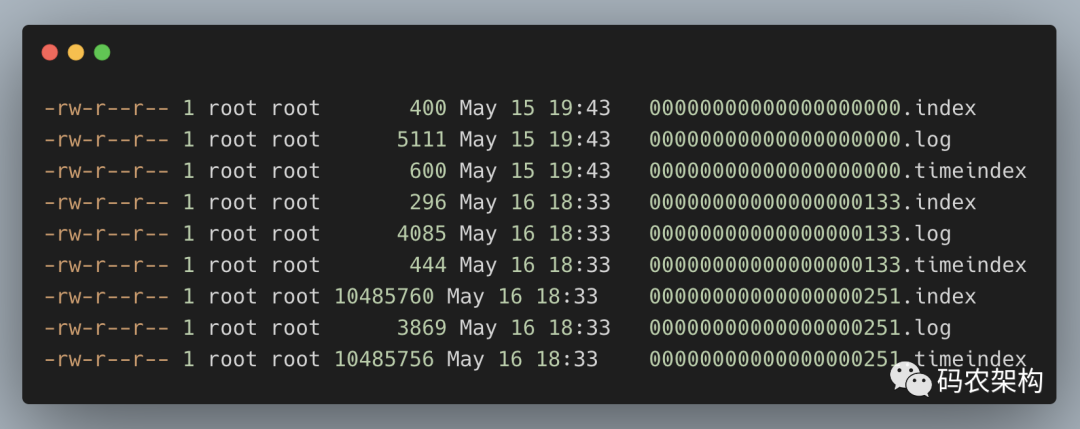
示例中第2个 LogSegment 对应的基准位移是133,也说明了该 LogSegment 中的第一条消息的偏移量为133,同时可以反映出第一个 LogSegment 中共有133条消息(偏移量从0至132的消息)。
注意每个 LogSegment 中不只包含“.log”、“.index”、“.timeindex”这3种文件,还可能包含“.deleted”、“.cleaned”、“.swap”等临时文件,以及可能的“.snapshot”、“.txnindex”、“leader-epoch-checkpoint”等文件。
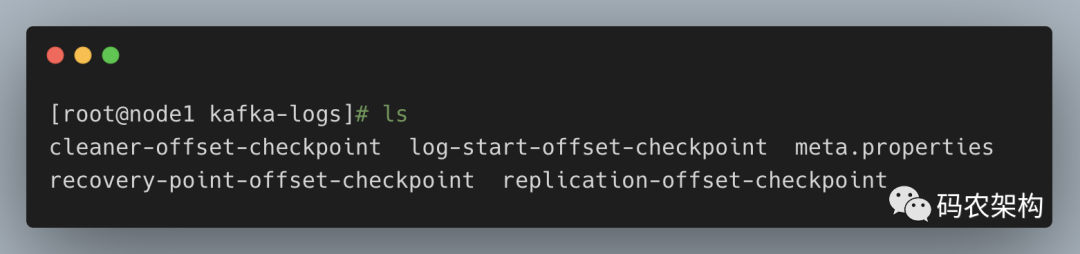
从更加宏观的视角上看,Kafka 中的文件不只上面提及的这些文件,比如还有一些检查点文件,当一个 Kafka 服务第一次启动的时候,默认的根目录下就会创建以下5个文件:
消费者提交的位移是保存在 Kafka 内部的主题__consumer_offsets中的,初始情况下这个主题并不存在,当第一次有消费者消费消息时会自动创建这个主题。
在某一时刻,Kafka 中的文件目录布局如上图所示。每一个根目录都会包含最基本的4个检查点文件(xxx-checkpoint)和 meta.properties 文件。在创建主题的时候,如果当前 broker 中不止配置了一个根目录,那么会挑选分区数最少的那个根目录来完成本次创建任务。
- END -

本文分享自微信公众号 - 码农架构(iByteCoding)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












