作者:恒小发
链接:https://www.zhihu.com/question/19719997/answer/574410444
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
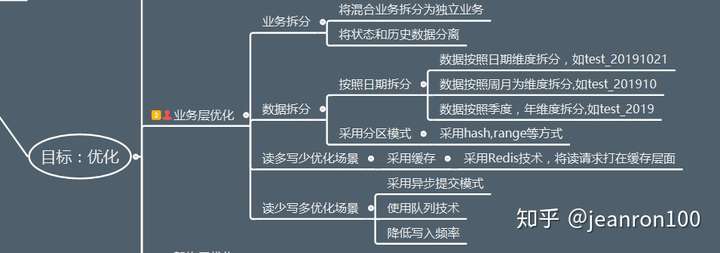
分表
我们前面有提到过对于mysql,其数据文件是以文件形式存储在磁盘上的。当一个数据文件过大时,操作系统对大文件的操作就会比较麻烦耗时,且有的操作系统就不支持大文件,这个时候就必须分表了。另外对于mysql常用的存储引擎是Innodb,它的底层数据结构是B+树。当其数据文件过大的时候,查询一个节点可能会查询很多层次,而这必定会导致多次IO操作进行装载进内存,肯定会耗时的。除此之外还有Innodb对于B+树的锁机制。对每个节点进行加锁,那么当更改表结构的时候,这时候就会树进行加锁,当表文件大的时候,这可以认为是不可实现的。所以综上我们就必须进行分表与分库的操作。
如何进行分库分表,目前互联网上有许多的版本,比较知名的一些方案:阿里的TDDL,DRDS和cobar,京东金融的sharding-jdbc;民间组织的MyCAT;360的Atlas;美团的zebra;其他比如网易,58,京东等公司都有自研的中间件。
这么多的分库分表中间件方案归总起来,就两类:client模式和proxy模式。
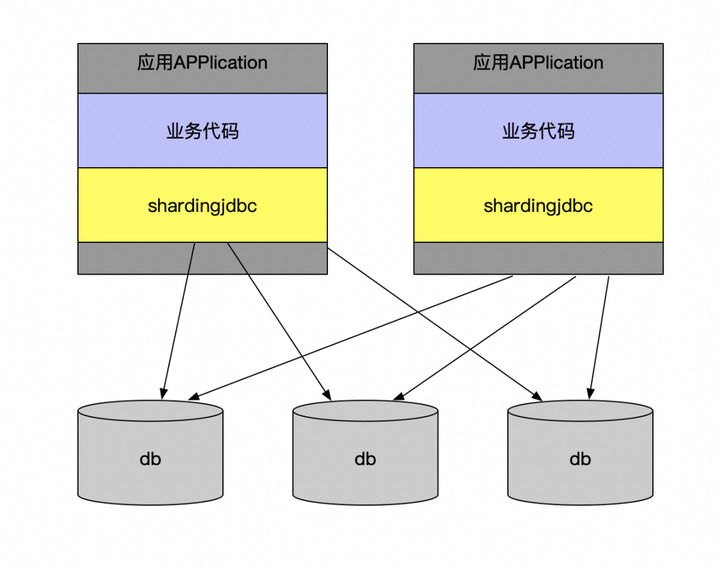
client模式
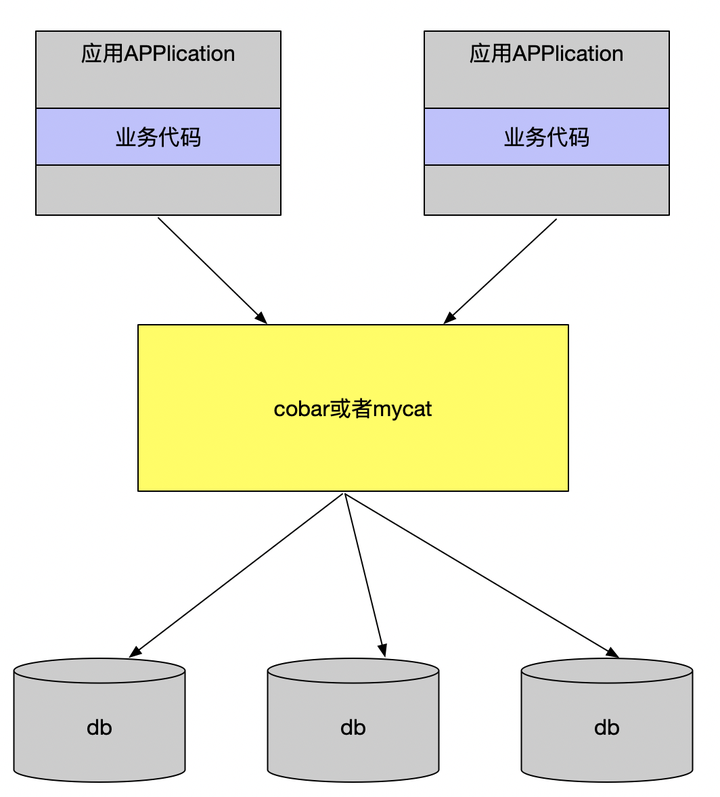
proxy模式
无论是client模式,还是proxy模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。个人比较倾向于采用client模式,它架构简单,性能损耗也比较小,运维成本低。
如何对业务类型进行分库分表。分库分表最重要的一步,即sharding column的选取,sharding column选择的好坏将直接决定整个分库分表方案最终是否成功。而sharding column的选取跟业务强相关。在我们的项目场景中,sharding column无疑最好的选择是业务编号。通过业务编号,将客户不同的绑定签约业务保存到不同的表里面去,根据业务编号路由到相应的表中进行查询,达到进一步优化sql的目的。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
作者:zhuqz
链接:https://www.zhihu.com/question/19719997/answer/81930332
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
很多人第一反应是各种切分;我给的顺序是:
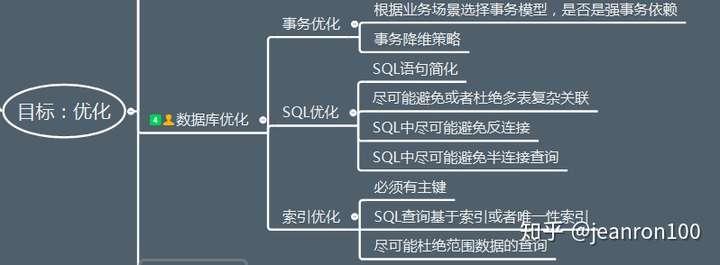
第一优化你的sql和索引;
第二加缓存,memcached,redis;
第三以上都做了后,还是慢,就做主从复制或主主复制,读写分离,可以在应用层做,效率高,也可以用三方工具,第三方工具推荐360的atlas,其它的要么效率不高,要么没人维护;
第四如果以上都做了还是慢,不要想着去做切分,mysql自带分区表,先试试这个,对你的应用是透明的,无需更改代码,但是sql语句是需要针对分区表做优化的,sql条件中要带上分区条件的列,从而使查询定位到少量的分区上,否则就会扫描全部分区,另外分区表还有一些坑,在这里就不多说了;
第五如果以上都做了,那就先做垂直拆分,其实就是根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统;
第六才是水平切分,针对数据量大的表,这一步最麻烦,最能考验技术水平,要选择一个合理的sharding key,为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表;
mysql数据库一般都是按照这个步骤去演化的,成本也是由低到高;
有人也许要说第一步优化sql和索引这还用说吗?的确,大家都知道,但是很多情况下,这一步做的并不到位,甚至有的只做了根据sql去建索引,根本没对sql优化(中枪了没?),除了最简单的增删改查外,想实现一个查询,可以写出很多种查询语句,不同的语句,根据你选择的引擎、表中数据的分布情况、索引情况、数据库优化策略、查询中的锁策略等因素,最终查询的效率相差很大;优化要从整体去考虑,有时你优化一条语句后,其它查询反而效率被降低了,所以要取一个平衡点;即使精通mysql的话,除了纯技术面优化,还要根据业务面去优化sql语句,这样才能达到最优效果;你敢说你的sql和索引已经是最优了吗?
再说一下不同引擎的优化,myisam读的效果好,写的效率差,这和它数据存储格式,索引的指针和锁的策略有关的,它的数据是顺序存储的(innodb数据存储方式是聚簇索引),他的索引btree上的节点是一个指向数据物理位置的指针,所以查找起来很快,(innodb索引节点存的则是数据的主键,所以需要根据主键二次查找);myisam锁是表锁,只有读读之间是并发的,写写之间和读写之间(读和插入之间是可以并发的,去设置concurrent_insert参数,定期执行表优化操作,更新操作就没有办法了)是串行的,所以写起来慢,并且默认的写优先级比读优先级高,高到写操作来了后,可以马上插入到读操作前面去,如果批量写,会导致读请求饿死,所以要设置读写优先级或设置多少写操作后执行读操作的策略;myisam不要使用查询时间太长的sql,如果策略使用不当,也会导致写饿死,所以尽量去拆分查询效率低的sql,
innodb一般都是行锁,这个一般指的是sql用到索引的时候,行锁是加在索引上的,不是加在数据记录上的,如果sql没有用到索引,仍然会锁定表,mysql的读写之间是可以并发的,普通的select是不需要锁的,当查询的记录遇到锁时,用的是一致性的非锁定快照读,也就是根据数据库隔离级别策略,会去读被锁定行的快照,其它更新或加锁读语句用的是当前读,读取原始行;因为普通读与写不冲突,所以innodb不会出现读写饿死的情况,又因为在使用索引的时候用的是行锁,锁的粒度小,竞争相同锁的情况就少,就增加了并发处理,所以并发读写的效率还是很优秀的,问题在于索引查询后的根据主键的二次查找导致效率低;
ps:很奇怪,为什innodb的索引叶子节点存的是主键而不是像mysism一样存数据的物理地址指针吗?如果存的是物理地址指针不就不需要二次查找了吗,这也是我开始的疑惑,根据mysism和innodb数据存储方式的差异去想,你就会明白了,我就不费口舌了!
所以innodb为了避免二次查找可以使用索引覆盖技术,无法使用索引覆盖的,再延伸一下就是基于索引覆盖实现延迟关联;不知道什么是索引覆盖的,建议你无论如何都要弄清楚它是怎么回事!
尽你所能去优化你的sql吧!说它成本低,却又是一项费时费力的活,需要在技术与业务都熟悉的情况下,用心去优化才能做到最优,优化后的效果也是立竿见影的!
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
从一开始脑海里开始也是火光四现,到不断的自我批评,后来也参考了一些团队的经验,我整理了下面的大纲内容。 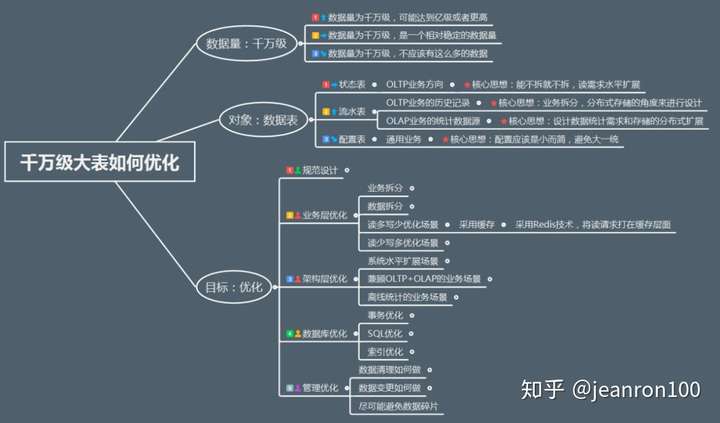 既然要吃透这个问题,我们势必要回到本源,我把这个问题分为三部分:
既然要吃透这个问题,我们势必要回到本源,我把这个问题分为三部分:
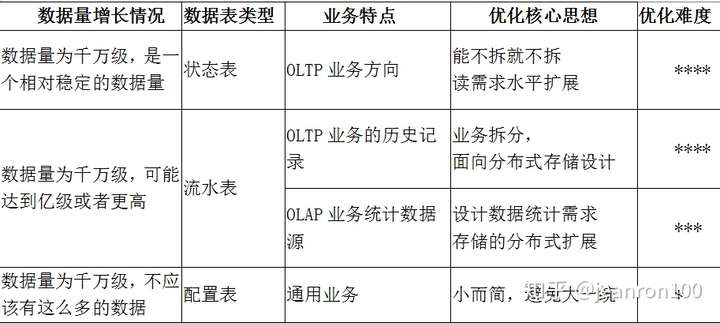
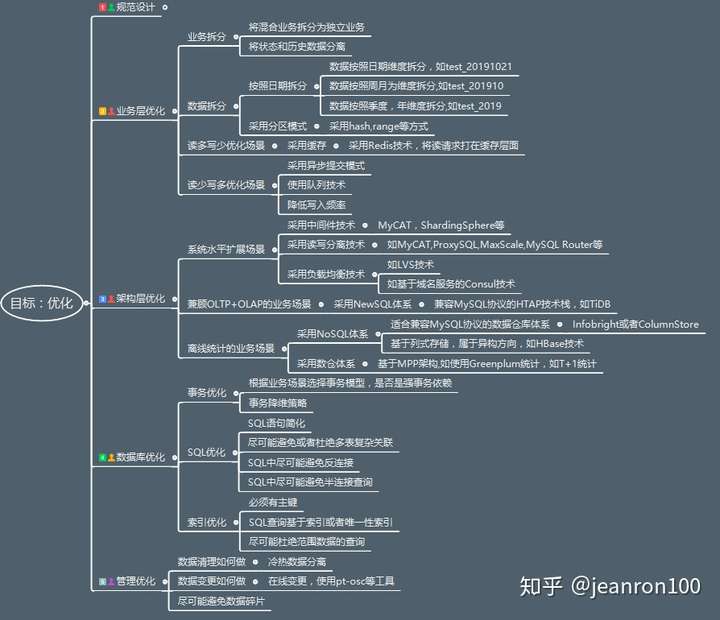
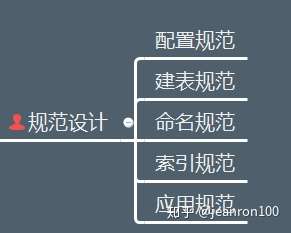
千万级”,“大表”,“优化”,
也分别对应我们在图中标识的
“数据量”,“对象”和“目标”。