国内开源代码大模型
4月9日aiXcoder宣布正式开源其7B模型Base版,仅仅过去一个礼拜,aiXcoder-7B在软件源代码托管服务平台GitHub上的Star数已超过2k。同时跻身HuggingFace趋势榜单TOP30,令全球开发者瞩目。
背后团队
aiXcoder 团队来自北京大学软件工程研究所,2013就开始搞代码生成,他们不但是国际上最早将深度学习技术用于程序代码处理的团队,也是最早推出基于深度学习的编程产品的团队,从一开始他们就抓住并专注于代码大模型这个前沿赛道。
团队长期聚焦软件工程、系统软件、程序理解、程序生成、深度学习、可信人工智能等前沿领域,在多个国内外顶级会议与期刊发表相关论文100余篇,多篇被国际同行视为“首创成果”。
从学界最前沿的理论研究,到广泛应用部署的商业实践,aiXcoder致力于将前沿人工智能技术应用于软件工程,聚焦代码大模型的企业个性化落地技术,助力企业实现智能化开发,为未来商业落地打下坚实基础。
发展历史
2017年,aiXcoder最开始的雏形——aiXcoder1.0发布,提供代码自动补全与搜索功能。
2021年4月,团队推出完全自主知识产权的十亿级参数代码大模型aiXcoder L版,支持代码补全和自然语言推荐。这也是国内⾸个基于“⼤模型”的智能编程商⽤产品。
2022年6月再次推出了国内首个支持方法级代码生成的百亿级参数量模型aiXcoder XL版,同样具有完全自主知识产权。
2023年7月,aiXcoder团队推出聚焦企业适配的aiXcoder Europa,具有代码自动补全、代码自动生成、代码缺陷检测与修复、单元测试自动生成等功能。aiXcoder Europa可根据企业数据安全和算力要求,为企业提供私有化部署和个性化训练服务,有效降低代码大模型的应用成本,提升研发效率。
2024年4月9日,aiXcoder-7B Base版诞生。
有何能耐
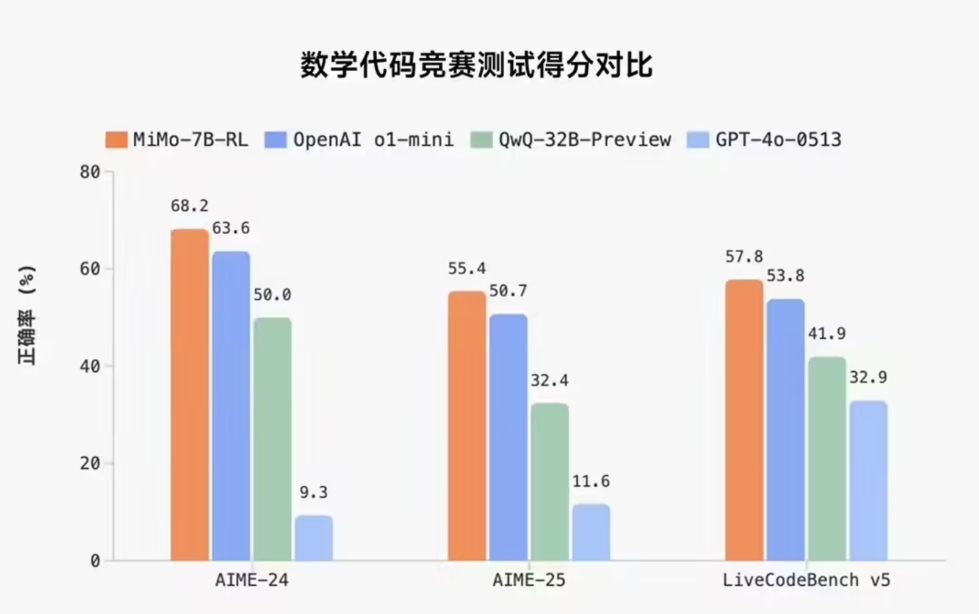
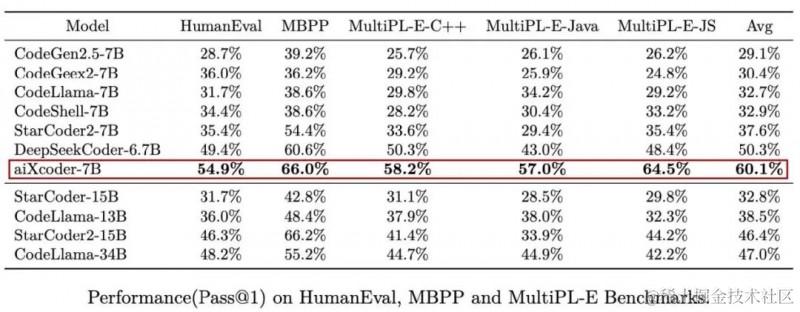
尽管aiXcoder只是一个7B大小的模型,但在HumanEval、MBPP和MultiPL-E等主流代码生成评测集上,它平均得分居然超过340亿参数的Codellama。要知道,后者来自Meta、基于Llama2,可是开源界最先进的AI编程大模型之作。
核心能力
代码生成与补全的卓越性能
aiXcoder-7B模型在HumanEval、MBPP和MultiPL-E等主流评测集上的表现超越了参数规模更大的模型,这得益于其深度学习架构和大规模的训练数据。它能够生成和补全包括方法块、条件判断、循环处理、异常捕捉等多种代码结构,大大提升了代码编写的效率。
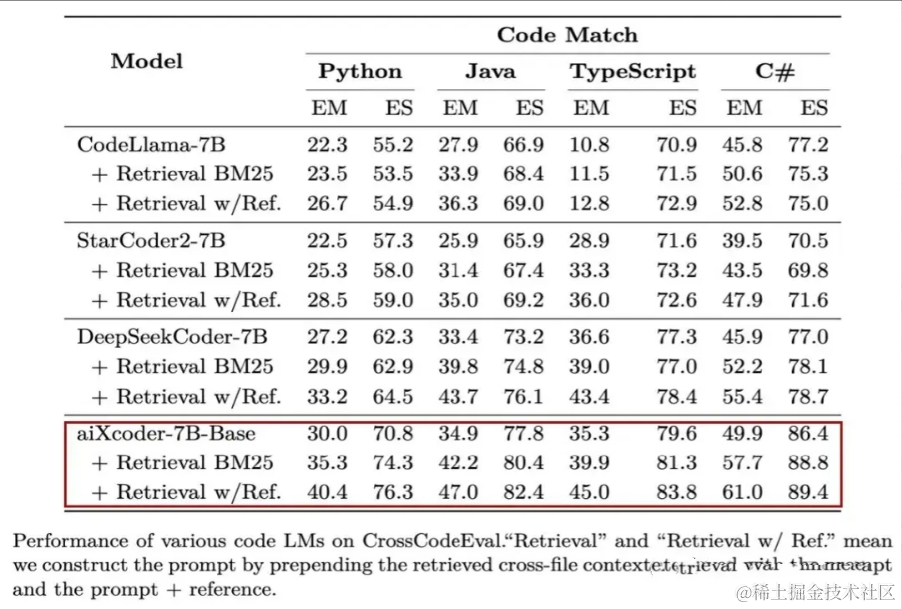
测试显示,在贴近真实开发场景的评测集CrossCodeEval上,aiXcoder-7B一举拿下了同级别模型的最好效果:
企业级场景的深度定制与私有化部署
aiXcoder-7B模型支持企业根据自身的软件开发框架和API库进行个性化训练,确保模型能够理解并适应企业特定的代码规范和业务逻辑。同时,模型的私有化部署能力,让企业能够在本地安全地使用模型,保护了企业的核心知识产权。
跨文件的智能分析与补全
aiXcoder-7B模型不仅理解单个文件的上下文,还能跨多个文件进行智能分析,这对于大型软件项目尤为重要。模型能够识别项目中不同文件的关联,生成和补全代码时考虑到整个项目的结构,提高了代码的一致性和可维护性。
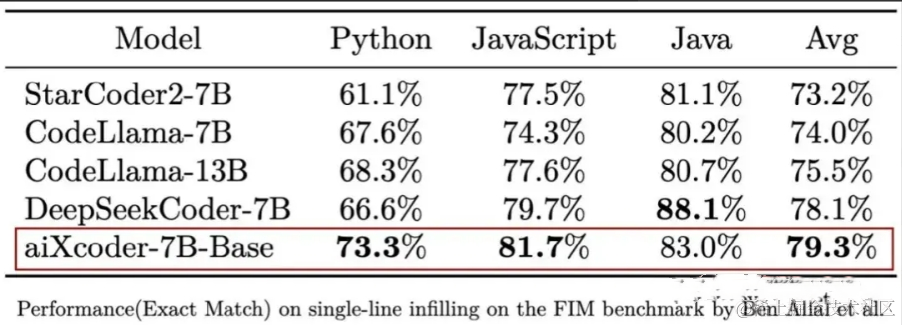
测试显示,aiXcoder-7B Base版结合单文件上下文的代码补全能力超越StarCoder2、CodeLlama等一众模型,在Python、JS和Java语言上综合得分最高。
持续的技术创新与优化
aiXcoder团队在模型训练中采用了创新的方法,如将代码的抽象语法树结构融入预训练过程,显著提升了模型对代码语义和逻辑的理解能力。此外,团队还构建了大规模的优质代码语料库,通过精心的数据预处理,确保了模型训练的质量和效果。
应用案例
金融行业代码生成应用
以正在进行数智化转型的某行业头部券商为例,该企业采用了aiXcoder的大模型解决方案,在本地环境私有化部署代码大模型,并结合企业自身领域知识进行个性化训练。结果显示,在业务逻辑代码上,代码生成占比提升了2倍,显著提高了开发效率。
跨文件动态规划状态类补全
在另一个案例中,aiXcoder-7B模型展现了其跨文件分析的能力。面对需要在树结构上应用动态规划的复杂任务,模型准确识别了不同文件间的逻辑关系,并给出了正确的预测结果,展现了其在处理复杂编程问题上的实力。
技术细节
训练数据的构建与优化
aiXcoder-7B模型的训练数据量达到了1.2T Unique Tokens,这一庞大的数据集经过了严格的语法分析和静态分析,排除了常见的Bug和代码缺陷,确保了模型训练的高质量。
预训练方法的创新
aiXcoder团队在预训练方法上进行了创新,将代码的抽象语法树结构融入到预训练过程中,这一方法有效地提升了模型对代码结构特征的捕捉能力,从而生成更高质量的代码。
模型的个性化训练技术
aiXcoder-7B模型的个性化训练技术是其另一大亮点。通过构建企业专属的数据集和测评集,结合企业代码特征和员工编程习惯,模型能够更好地适应企业的开发环境,实现更高效的个性化应用。
总结
在科技的璀璨星河中,每一次技术的突破都如同新星的诞生,照亮了未来的无限可能。随着代码大模型的能力日益增强,它们在解决复杂编程问题上的卓越表现,不仅在提高软件开发的效率和质量上发挥着重要作用,在推动编程自动化的浪潮中扮演着关键角色,更激发了程序员们的创新潜能,让他们能够将更多的精力投入到探索和创造中。
aiXcoder-7B模型的出现,预示着软件开发领域将迎来一场新的革命。随着技术的不断进步,aiXcoder-7B将成为软件开发领域中的“新质生产力”,帮助企业实现智能化开发,推动技术行业的生态发展。
随着代码大模型不断发展,不仅加速了软件开发自动化的进程,更在重塑技术行业的生态,引领着未来发展的趋势:加快实现软件开发自动化。这既是行业大势所趋,更是发展的必然选择。荣幸的是,我们正站在这个转折点面前,见证着这一趋势的兴起和实现。
作为一名IT技术人员,我对代码大模型的未来发展充满期待。它不仅解决了当前软件开发中的多个痛点,更为大家展示了一个全新的编程未来。模型的不断开源和企业级特性,将推动整个行业向更高效、更智能的方向发展。对于热爱编程的人来说,不仅仅是一个工具,更是一个能够激发创新、提升生产力的伙伴。让我们一起期待并拥抱这场由AI引领的编程革命吧!
开源地址
https://github.com/aixcoder-plugin/aiXcoder-7B
https://gitee.com/aixcoder-model/aixcoder-7b
https://www.gitlink.org.cn/aixcoder/aixcoder-7b-model
感兴趣的小伙伴可自行体验,也可以等我后续的测试分享,让我们一起支持国产开源大模型吧!
作者:京东零售 刘邓忠
来源:京东云开发者社区