
APM简介
随着微服务架构的流行,一次请求往往需要涉及到多个服务,因此服务性能监控和排查就变得更复杂:
不同的服务可能由不同的团队开发、甚至可能使用不同的编程语言来实现 服务有可能布在了几千台服务器,横跨多个不同的数据中心 因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题,这就是APM系统,全称是(Application Performance Monitor,当然也有叫 Application Performance Management tools)
AMP最早是谷歌公开的论文提到的 Google Dapper。Dapper是Google生产环境下的分布式跟踪系统,自从Dapper发展成为一流的监控系统之后,给google的开发者和运维团队帮了大忙,所以谷歌公开论文分享了Dapper。
谷歌Dapper介绍
在google的首页页面,提交一个查询请求后,会经历什么:
•可能对上百台查询服务器发起了一个Web查询,每一个查询都有自己的Index•这个查询可能会被发送到多个的子系统,这些子系统分别用来处理广告、进行拼写检查或是查找一些像图片、视频或新闻这样的特殊结果•根据每个子系统的查询结果进行筛选,得到最终结果,最后汇总到页面上•总结一下:
一次全局搜索有可能调用上千台服务器,涉及各种服务。用户对搜索的耗时是很敏感的,而任何一个子系统的低效都导致导致最终的搜索耗时 如果一次查询耗时不正常,工程师怎么来排查到底是由哪个服务调用造成的?
•首先,这个工程师可能无法准确的定位到这次全局搜索是调用了哪些服务,因为新的服务、乃至服务上的某个片段,都有可能在任何时间上过线或修改过,有可能是面向用户功能,也有可能是一些例如针对性能或安全认证方面的功能改进•其次,你不能苛求这个工程师对所有参与这次全局搜索的服务都了如指掌,每一个服务都有可能是由不同的团队开发或维护的•再次,这些暴露出来的服务或服务器有可能同时还被其他客户端使用着,所以这次全局搜索的性能问题甚至有可能是由其他应用造成的
从上面可以看出Dapper需要:
无所不在的部署,无所不在的重要性不言而喻,因为在使用跟踪系统的进行监控时,即便只有一小部分没被监控到,那么人们对这个系统是不是值得信任都会产生巨大的质疑 持续的监控
Dapper的三个具体设计目标
性能消耗低
APM组件服务的影响应该做到足够小。服务调用埋点本身会带来性能损耗,这就需要调用跟踪的低损耗,实际中还会通过配置采样率的方式,选择一部分请求去分析请求路径。在一些高度优化过的服务,即使一点点损耗也会很容易察觉到,而且有可能迫使在线服务的部署团队不得不将跟踪系统关停。
应用透明,也就是代码的侵入性小
即也作为业务组件,应当尽可能少入侵或者无入侵其他业务系统,对于使用方透明,减少开发人员的负担。
对于应用的程序员来说,是不需要知道有跟踪系统这回事的。如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统也太脆弱了,往往由于跟踪系统在应用中植入代码的bug或疏忽导致应用出问题,这样才是无法满足对跟踪系统“无所不在的部署”这个需求。
可扩展性
一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性。能够支持的组件越多当然越好。或者提供便捷的插件开发API,对于一些没有监控到的组件,应用开发者也可以自行扩展。
数据的分析
数据的分析要快 ,分析的维度尽可能多。跟踪系统能提供足够快的信息反馈,就可以对生产环境下的异常状况做出快速反应。分析的全面,能够避免二次开发。
Dapper的分布式跟踪原理
基本方法
例如下图这样的调用关系:
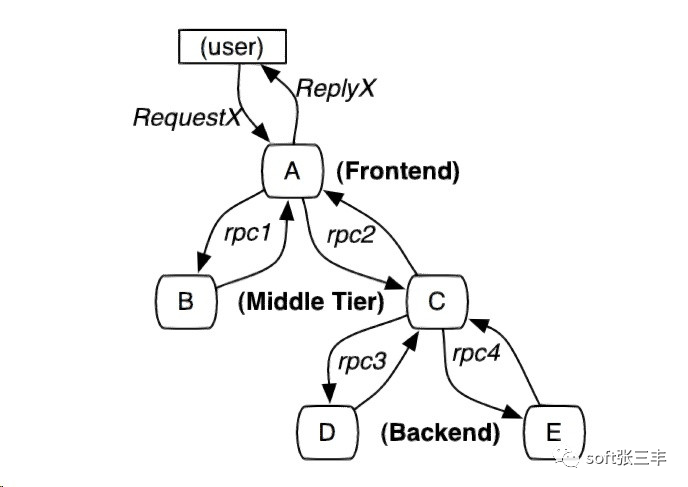
•黑盒方案:假定需要跟踪的除了上述信息之外没有额外的信息,这样使用统计回归技术来推断两者之间的关系。需要一些额外的数据来获得足够精度。•基于标注的方案:依赖于应用程序或中间件明确地标记一个全局ID,从而连接每一条记录和发起者的请求。缺点是有代码入侵。
跟踪树和span
在Dapper跟踪树结构中,树节点是整个架构的基本单元,而每一个节点又是对span的引用。节点之间的连线表示的span和它的父span直接的关系。虽然span在日志文件中只是简单的代表span的开始和结束时间,他们在整个树形结构中却是相对独立的。这里span是跟踪术结构的基本单元,也表示一小段的时间。下图是5个span在Dapper跟踪树种短暂的关联关系
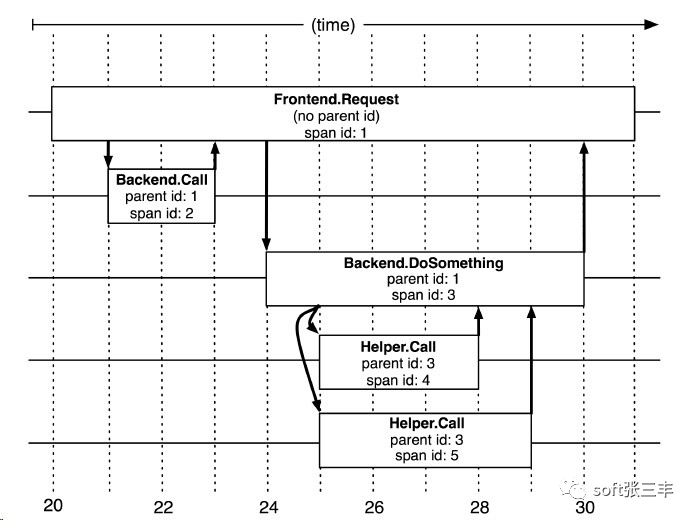
上图说明了span在一个大的跟踪过程中是什么样的。Dapper记录了span名称,以及每个span的ID和父ID,以重建在一次追踪过程中不同span之间的关系。如果一个span没有父ID被称为root span。所有span都挂在一个特定的跟踪上,也共用一个跟踪id(在图中未示出)。所有这些ID用全局唯一的64位整数标示。在一个典型的Dapper跟踪中,我们希望为每一个RPC对应到一个单一的span上,而且每一个额外的组件层都对应一个跟踪树型结构的层级。
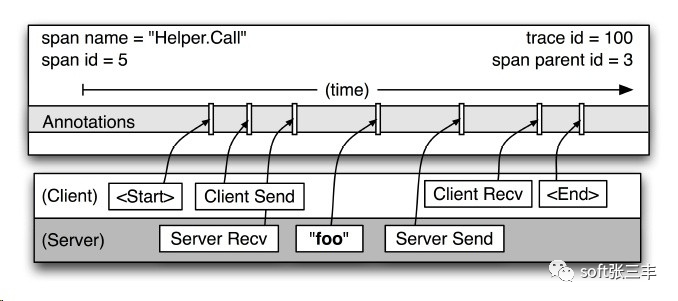
上图给出了一个更详细的典型的Dapper跟踪span的记录点的视图。在图中这种某个span表述了两个“Helper.Call”的RPC(分别为server端和client端)。span的开始时间和结束时间,以及任何RPC的时间信息都通过Dapper在RPC组件库的植入记录下来。如果应用程序开发者选择在跟踪中增加他们自己的注释(如图中“foo”的注释)(业务数据),这些信息也会和其他span信息一样记录下来。
埋点
1.追踪的上下文信息在ThreadLocal中进行存储。2.当计算过程是延迟调用的或是异步的,google通过通用的控制流来回调,确保所有的回调可以存储这次跟踪的上下文信息。当回调函数被触发时,这次跟踪的上下文会与适当的线程关联上。在这种方式下,Dapper可以使用trace ID和span ID来辅助构建异步调用的路径。3.google的所有进程通信是建立在一个RPC框架上。在RPC框架本身中来埋点从而定义所有span。4.dapper允许用户在Dapper跟踪的过程中添加额外的信息,以监控更高级别的系统行为,或帮助调试问题。我们允许用户通过一个简单的API定义带时间戳的Annotation,核心的示例代码如下图所示。5.dapper支持如下图的文本annotation也支持key-value映射的Annotation。如持续的计数器,二进制消息记录和在一个进程上跑着的任意的用户数据等。

跟踪收集
下图演示了Dapper收集管道:
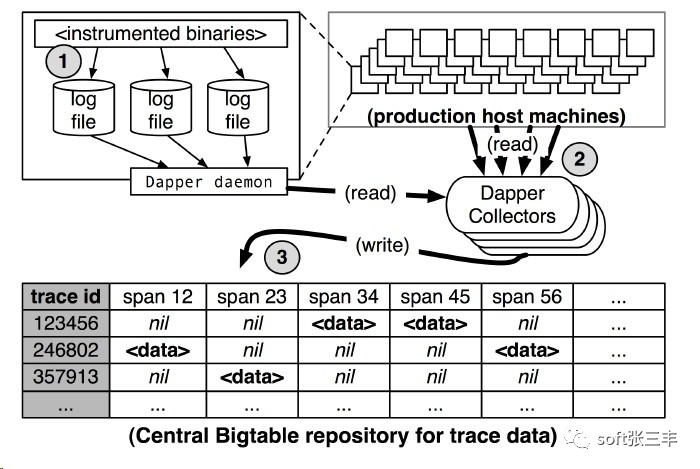
由上图可知,Dapper的跟踪记录和收集管道的过程分为三个阶段: span数据写入本地日志文件中。然后Dapper的守护进程和收集组件把这些数据从生产环境的主机中拉出来 写到Dapper的Bigtable仓库中。一次跟踪被设计成Bigtable中的一行,每一列相当于一个span。Bigtable的支持稀疏表格布局正适合这种情况,因为每一次跟踪可以有任意多个span。Dapper还提供了一个API来简化访问我们仓库中的跟踪数据。Google的开发人员用这个API,以构建通用和特定应用程序的分析工具。
APM组件选型
市面上的全链路监控理论模型大多都是借鉴Google Dapper论文,重点关注以下三种APM组件:
•Zipkin:由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。•Pinpoint:一款对Java编写的大规模分布式系统的APM工具,由韩国人开源的分布式跟踪组件。•Skywalking:国产的优秀APM组件,是一个对JAVA分布式应用程序集群的业务运行情况进行追踪、告警和分析的系统。
对比项
主要对比项:
探针的性能
主要是agent对服务的吞吐量、CPU和内存的影响。微服务的规模和动态性使得数据收集的成本大幅度提高。
collector的可扩展性
能够水平扩展以便支持大规模服务器集群。
全面的调用链路数据分析
提供代码级别的可见性以便轻松定位失败点和瓶颈。
对于开发透明,容易开关
添加新功能而无需修改代码,容易启用或者禁用。
完整的调用链应用拓扑
自动检测应用拓扑,帮助你搞清楚应用的架构
如何采集数据
APM是通过采集探针采集应用数据的。采集探针是通过字节码增强技术进行埋点,生成调用数据。调用数据被采集代理ICAgent所获取并处理,然后上报并呈现在界面中。关系如下图所示:
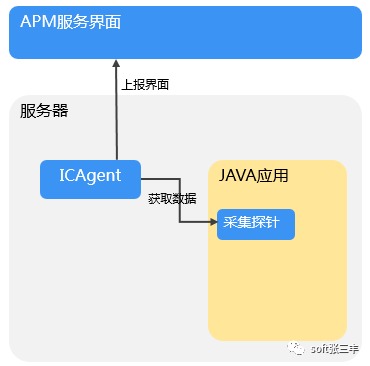
采集哪些数据
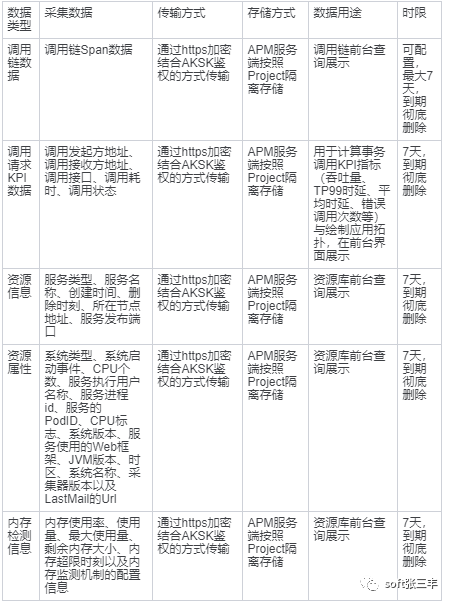
APM仅采集应用的业务调用链数据、资源信息、资源属性、内存检测信息、调用请求的KPI数据,不涉及个人隐私数据。所采集的数据仅用于APM性能分析和故障诊断,不会用于其他商业目的。下表为数据采集范围和用途。
行业分析
目前APM市场在海外主要有两类的核心企业。一类是四大传统IT巨头(IBM、HP、CATechnologies、BMC),另一类是ITOM市场新创企业,包括Dynatrace、NewRelic、AppDynamics、Splunk等。随着市场成熟度的不断提高,APM市场的市场格局与ITOM整体的市场格局一样,呈现初创企业加速发展,开始占据市场主导的市场趋势。
根据调查数据显示,NewRelic、AppDynamics以及Dynatrace作为新创企业依旧保持在APM市场的领导者象限,这三家公司是当前全球APM市场的标杆企业。
在国内,博睿、听云、OneAPM、云智慧在国内市场的占用额较大
面试题积累 https://www.cnblogs.com/skyme/p/13212296.html
微服务微信交流群添加微信,备注微服务进群交流

本文分享自微信公众号 - soft张三丰(aguzhangsanfeng)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。














