
本文为系列专题【数据结构和算法:简单方法】的第 12 篇文章。
- 数据结构 | 顺序表
- 数据结构 | 链表
- 数据结构 | 栈
- 数据结构 | 队列
- 数据结构 | 双链表和循环链表
- 数据结构 | 二叉树的概念和原理
- 数据结构 | 二叉树的创建及遍历实现
- 数据结构 | 线索二叉树
- 数据结构 | 二叉堆
- 算法 | 顺序查找和二分查找
1. 是什么?
二叉查找树(Binary Search Tree)必须满足以下特点:
- 若左子树不为空,则左子树的所有结点值皆小于根结点值
- 若右子树不为空,则右子树的所有结点值皆大于根结点值
- 左右子树也是二叉排序树
如下图,是一颗二叉查找树:
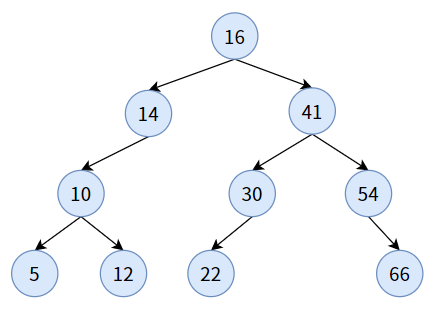
如果你对二叉查找树进行中序遍历,可以得到:5, 10, 12, 14, 16, 22, 30, 41, 54, 66。刚好是一个从小到大的有序序列,从这一点看,二叉查找树是可以进行排序的,所以这种树又叫二叉排序树(Binary Sort Tree)。
2. 查找
我们以上图为例,说明查找成功和失败两种过程。
先贴出代码:
int bst_search(BSTNode *root, int key, BSTNode **p, BSTNode *q)
{
if (root == NULL) { // 空树,查找失败
*p = q;
return 0;
}
if (key == root->data) { // 目标值相等根结点的值,查找成功
*p = root;
return 1;
} else if (key < root->data) { // 目标值小于根结点的值,递归进入左子树
return bst_search(root->left_child, key, p, root);
} else { // 目标值大于根结点的值,递归进入右子树
return bst_search(root->right_child, key, p, root);
}
}该方法中的三个指针的作用如下:
指针
root始终指向根结点, 标识了与目标值比较的结点;二级指针
p指向最终查找的结果。如果查找成功,则指向“指向‘找到的结点’的指针”;如果查找失败,则指向“指向‘上次最后一个访问的结点’的指针”。指针
q初始为空,以后始终指向上一个根结点。
下面是查找成功的过程动图:

下面是查找失败的过程动图:

请注意,以上过程成立的前提是:二叉树是一颗二叉排序树,必须满足二叉排序树的三个特点。
所以,二叉排序树的“排序”二字是为查找而服务的,上面两个动图足以说明,排序方便了查找,因为每次比较都在缩小范围。
二叉排序树和二分查找本质上做的事是一样的,比如以下几方面:
- 都是有序的。二分查找是全部有序,二叉排序数是局部有序。
- 都是将一组数划分成若干区域。二分查找通过三个标志位,二叉排序树通过树结构。
- 都是通过比较目标值和“区域分界点”的大小,从而确定目标值在哪个区域中。在二分查找中与中间标志位比较,在二叉查找树中与根结点比较。
我们在二分查找中说过:当涉及到频繁地插入和删除操作时,二分查找就不合适了。原因之一是二分查找要求元素是有序的(从小到大或从大到小),插入、删除破坏顺序后,需要额外精力维护有序状态。原因之二是二分查找使用顺序表实现,顺序表的插入和删除操作需要移动大量元素,也会影响效率。
但是二叉排序树是一个树,树结构通常使用链式结构来实现。链式结构对插入和删除操作很友好,也有利于我们维护二叉树的有序状态。
3. 创建和插入
现在给你一组没有顺序的数,比如 {16, 41, 14, 30, 10, 12, 54, 5, 22, 66},如何创建出一颗二叉查找树(BST)?这里为了方便起见,我们约定二叉查找树中没有重复值。
所谓创建,即向一个空树中不断插入结点,从而构成一个非空的二叉查找树。所以关键在于如何向一个二叉查找树中插入结点。
所谓插入,即不断比较待插入结点和树中结点的值,使其插到合适的位置,怎么找到“合适的位置”呢?方法前面已经给出,即 bst_search。
如果我们在二叉查找树中查找待插入值,一定会查找失败,即 bst_search 一定返回 0,所以bst_search 方法中的 p 指针最终指向的是最后一个访问的根结点,这个根结点的左孩子或右孩子即是“合适的位置”。
下面是创建(插入)的过程动图,和查找失败的过程动图非常相似:

插入一个结点的代码如下,可以看出,和 bst_search 的代码很相似:
int insert_bst_node(BSTNode **p_root, int key)
{
BSTNode *p;
if (bst_search(*p_root, key, &p, NULL) == 0) { // 没有查找到 key
BSTNode *new = create_bst_node(key); // 创建新结点
if (p == NULL) { // 空树,新节点直接作为根结点
*p_root = new;
return 1;
}
if (key < p->data) { // 插入值小于 p 的值,插入到左子树
p->left_child = new;
return 1;
}
if (key > p->data) { // 插入值大于 p 的值,插入到右子树
p->right_child = new;
return 1;
}
}
return 0; // 插入失败
}那么,创建操作用一个 for 循环就搞定了:
void create_bst(BSTNode **root, int *array, int length)
{
// 循环向空二叉查找树中插入若干结点
for (int i = 0; i < length; i++) {
insert_bst_node(root, array[i]);
}
}4. 删除
至此,我们已经介绍过好几种数据结构了,每种都涉及到增加(插入)和删除操作。就像加法和减法一样,插入和删除操作可以看作是一对“反操作”。这意味着,它们在原理、代码上有相似之处,能够做到触类旁通。但这不是绝对了,必须具体问题结合具体环境进行具体分析。比如删除二叉查找树中的某个结点,可能会破坏二叉查找树的结构,破坏其顺序,所以我们就需要分情况讨论。
【情况一】
待删除的结点没有孩子,即删除叶子结点。这是最简单的情况,因为删除叶子不会破坏剩下的结构,也不会破坏剩下的结点的顺序。
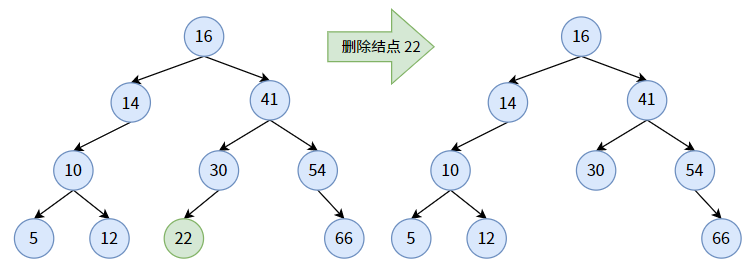
【情况二】
待删除的结点只有左子树或者右子树。这种情况也好做,将其左子树或右子树移动到删除结点处即可。由于二叉查找树使用了链式结构,所以删除操作的代价很小,只需要改变指针的指向。
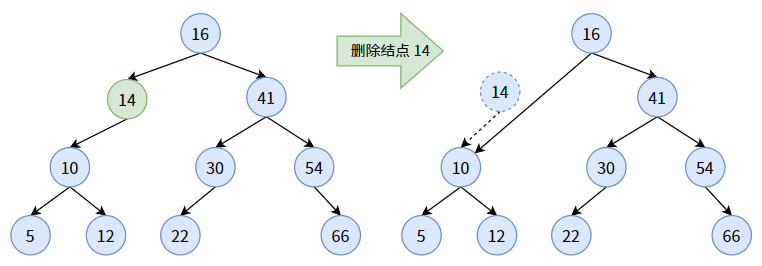
【情况三】
待删除的结点既有左子树又有右子树。这种情况比较复杂,因为删除结点后,剩下了该结点的左子树和右子树“在风中飘荡”,一方面我们要维持树结构,另一方面我们要维持二叉查找树的结点大小顺序,所以删除结点会涉及到整个树结构的调整,即将“剩下的”左子树和右子树重新插到树结构中去。下面是过程:

从上图过程就可以看出,这有点太过打动干戈了。我们先是改变 结点 16 的右孩子指针,然后删除 结点 41,并将其右子树“摘出来”,然后把剩下的右子树中的所有结点重新插入到二叉查找树中。这样确实挺累人的。
不妨换一种思路:
我们将 32 赋值给结点 41,然后删除结点 32,同样能够达到删除结点 41 的效果。这种方式大大简化了操作,不需要移动甚至改变树的结构,代价较小。我称这种方式为——狸猫换太子。
那么为什么偏偏是把结点 32 赋值给待删除结点 41 呢?前面说过,二叉查找树的中序遍历是一个有序序列,这也是为什么叫它二叉排序树的原因。结点 32 刚好是结点 41 在中序遍历序列下的直接前驱结点,所以,将 32 赋值给结点 41 后,并不会影响二叉查找树的“左子树值小于根结点,右子树值大于根结点”的定义。
所以,如何找到待删除结点在中序序列下的直接前驱是关键。
在中序遍历序列下,根结点的直接前驱是其左子树中最右最下的那个结点,如上例中结点 41 的直接前驱是结点 32.
到此,如何写代码就很清晰了。
一、先递归地找到待删除结点:
/**
* @description: 删除目标值结点
* @param {BSTNode**} 二级指针,指向 指向树根结点的指针 的指针
* @param {int} key 目标值
* @return {int} 删除成功返回1;否则返回0
*/
int delete_bst_node(BSTNode **p_root, int key)
{
if (*p_root == NULL) {
return 0;
}
if (key == (*p_root)->data) { // 找到要删除的目标值 key
rebuild_bst_after_delete(p_root);
} else if (key < (*p_root)->data) { // 目标值小于根结点,递归进入左子树
return delete_bst_node(&(*p_root)->left_child, key);
} else { // 目标值大于右子树,递归进入右子树
return delete_bst_node(&(*p_root)->right_child, key);
}
}可以看出,这段代码和删除操作的代码没有太大区别,本质仍是查找。
二、找到待删除结点后,将结点删除,然后调整以维持二叉查找树的结构:
/**
* @description: 删除某个结点后重新调整二叉查找树
* @param {BSTNode**} p_node 指向待删除结点的二级指针
* @return {int} 成功返回1;失败返回0
*/
int rebuild_bst_after_delete(BSTNode **p_node)
{
BSTNode *prev, *tmp;
tmp = *p_node;
if ((*p_node)->left_child == NULL) { // 左子树为空,重接右子树
*p_node = (*p_node)->right_child;
free(tmp);
return 1;
}
if ((*p_node)->right_child == NULL) { // 右子树为空,重接左子树
*p_node = (*p_node)->left_child;
free(tmp);
return 1;
}
// 左右子树均不为空
if ((*p_node)->left_child != NULL && (*p_node)->right_child != NULL) {
prev = (*p_node)->left_child;
while (prev->right_child != NULL) { // 找到待删除结点的直接前驱
tmp = prev;
prev = prev->right_child;
}
(*p_node)->data = prev->data; // 赋值
if (tmp != *p_node) { // 待删除结点有子孙结点
tmp->right_child = prev->left_child;
} else { // 待删除结点只有两个孩子结点,没有子孙结点
tmp->left_child = prev->left_child;
}
free(prev);
return 1;
}
return 0;
}以上就是二叉查找树的基本原理及实现
如有错误,还请指正。
如果觉得写的不错,可以点个赞和关注。后续会有更多数据结构和算法相关文章。 微信扫描下方二维码,一起学习更多计算机基础知识。











