Python 报表自动化/袁佳林
这篇文章是『读者分享系列』第二篇,这一篇来自袁佳林同学,这是他在读完我的书以后做的第一个Python报表自动化项目,现在他把整体的思路以及实现代码分享出来,希望对你有帮助。
你还可以看『读者分享系列』的第一篇:Python中的这几种报错你遇到过吗?
1.案例场景
作为企业的数据统计岗,每天都需要做很多报表,日报、周报、季报、月报。如果我们能利用Python的数据分析功能把这些常规的流程标准化的报表自动化,那么我们将能有更多的时间集中于数据背后的业务发展及逻辑的分析上,这样才能被称为是企业的数据分析师,而不是简单的数据搬运工。下面我们通过一个简单的案例来看看Python报表自动化的建模过程。某银行贷款业务部门数据分析员每天需要根据系统生成的个人贷款客户信息表统计管辖区域内各经营单位的不同贷款产品今年的投放情况。源数据表格式及字段如下图所示;

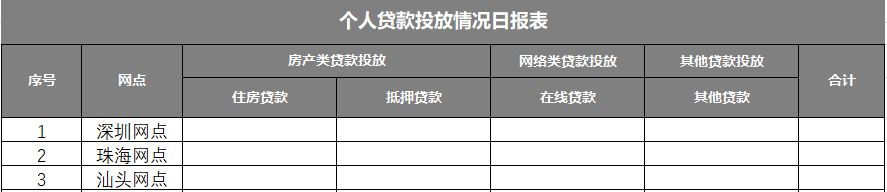
需要统计的数据报表如下图所示:
2.Excel制作过程
结合以上两张图,我们知道利用Excel的数据透视表功能就制作该报表:选中数据表中任意一个单元格,点击插入数据透视表,然后按以下步骤执行:
将合同生效日字段放在页区域(筛选今年)
将用途字段放在列区域。
将单位字段放在透视表的行区域。
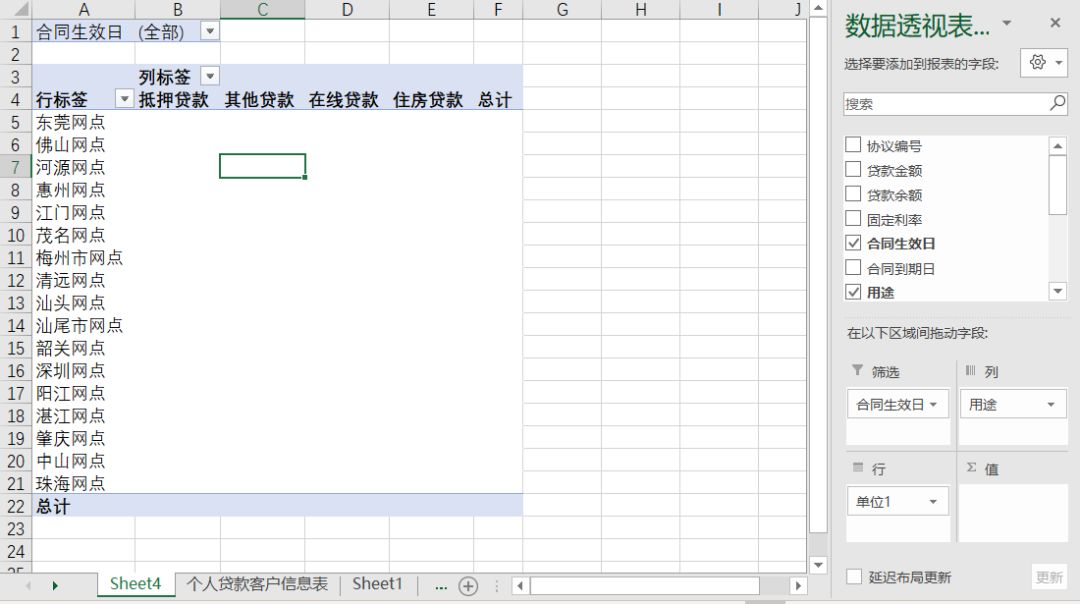
当处理到单位字段时我们会发现,表中每一笔贷款都有三家网点进行业绩分成。我们需要将分成比例也考虑进去。所以透视表中的行区域及值区域不能简单的放入单位1和贷款金额。此时大部分人都会想到先在数据源表格中添加三列按分成比例分成以后的贷款金额。
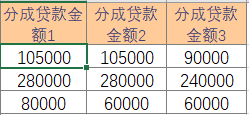
三个数值的计算方法分别为:
分成贷款金额1=贷款金额*分成比例1
分成贷款金额2=贷款金额*分成比例2
分成贷款金额3=贷款金额*分成比例3
然后将单位1及分成贷款金额1拖放到透视表的行区域及值区域。求出每个网点在分成金额1上的贷款投放,用同样的方法将各网点在分成贷款金额2及3的和。于是就会得到结构如下的三个数据透视表:
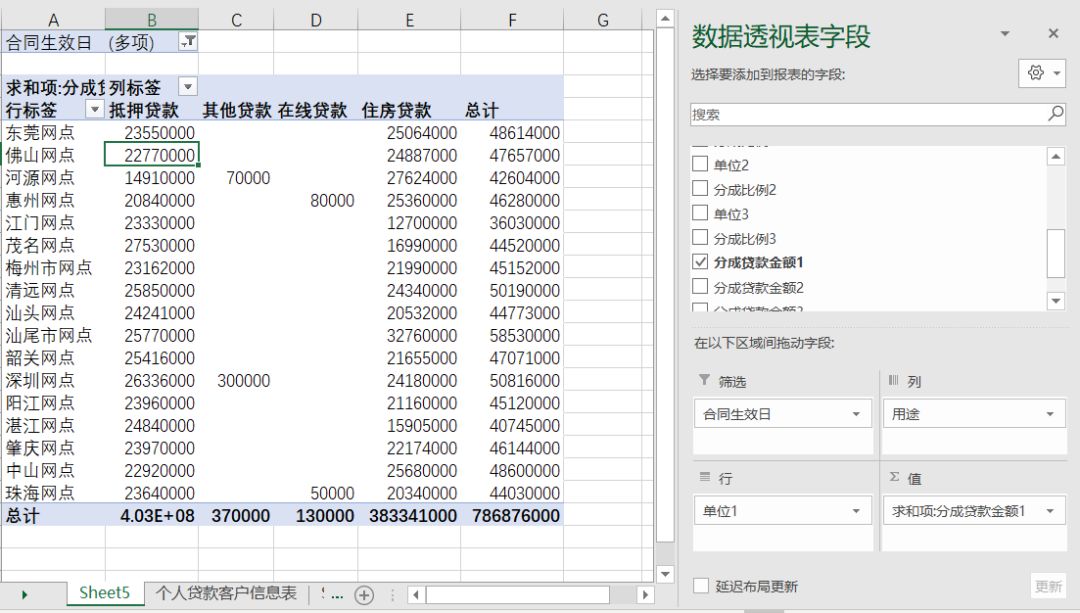
最后一步就是运用VlOOKUP将同一家网点的同种贷款金额整合相加到日报相对应的单元格里,实现最后的报表输出。
以上流程每天都需要进行重复:插入列、编写公式、做数据透视表、VLOOKUP,相信就算是熟悉Excel的人也需要华20到25分钟,而在操作过程中很容易因为疏忽而造成错误。如此循环往复,效率低下并且出错率高。而从操作上来讲,整个流程都是标准化的,因此我们可以考虑使用Python进行自动化设计。
3.Python优化报表制作过程
通过以上分析,我们知道问题的难点在于处理分成比例。存在多个分成比例产生了很多重复性的工作。由于每笔贷款的三个分成比例都是对同一个贷款金额进行分成,我们可以将贷款金额分别与分成单位1、2、3及分成比例1、2、3组成三张分表,然后将分表纵向追加。这样计算分成贷款金额时就只需要将新表的贷款金额及合并成一列的分成比例进行相乘。得出每个分成比例对于的分成贷款金额,最后将分成贷款金额按照单位及用途进行数据透视。
3.1加载数据表
数据加载过程比较简单,使用read_excel()进行设置即可,这里不在赘述。仅提出以下建议,供大家参考,
利用read_excel()的usecols参数对表列进行指定,排除不必要的干扰列。
养成数据加载以后,使用head()进行预览的习惯。
养成使用shape及info()了解表格的基本情况的习惯。
import pandas as pd
from datetime import datetime # 因为后面需要处理到日期筛选,所以需要将datetime类从datetime模块中加载进来
data=pd.read_excel(r"E:\个人贷款客户信息表.xlsx",usecols=[1,4,6,7,8,9,10,11,12]) # 假设个人贷款客户信息表放在本地E盘
data.shape
---
(50585, 9)
以上为导入个人贷款信息表格代码,由于个人贷款客户信息表为工作簿第一张工作表,因此缺省sheet_name参数。
通过指定导入例的方法将与计算无关的“协议编号”,“贷款余额”,“固定利率”,“合同到期日”去除。
#查看data表的基本信息
data.info()
---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50585 entries, 0 to 50584
Data columns (total 9 columns):
贷款金额 50585 non-null int64
合同生效日 50585 non-null datetime64[ns]
用途 50585 non-null object
单位1 50585 non-null object
分成比例1 50585 non-null int64
单位2 16418 non-null object
分成比例2 16418 non-null float64
单位3 958 non-null object
分成比例3 958 non-null float64
dtypes: datetime64[ns](1), float64(2), int64(2), object(4)
memory usage: 3.5+ MB
接下来预览一下data表的数据,默认显示前5行
data.head() 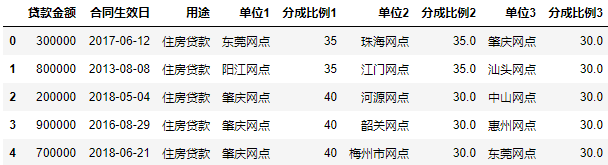
3.2日期筛选
个人贷款信息表包含该银行所有的历史数据,而我们每日的报表只需要统计当年的投放情况。所以计算投放金额前,我们需要将合同生效日期不符合要求的贷款记录排除掉。这里我们通过判断日期是否为2019年(大于2018-12-31)返回TRUE/FALSE进行选择判断。这种利用判断条件来选择数据的方式叫布尔索引。
这里解释一下import datetime和from datetime import datetime的区别。datetime 是模块,而datetime模块里面还包含一个datetime类。通过from datetime import datetime能从datetime模块直接导入datetime类。如果导入import datetime ,则在定义时间时,需要使用datetime.datetime()格式。
data=data[data["合同生效日"]>datetime(2018,12,31)]
data.shape #经过对日期的过滤,输出了1673行,9列
---
(1673, 9)
对日期列进行观察,可以看到合同生效日都是2019年的日期了。
data.head() 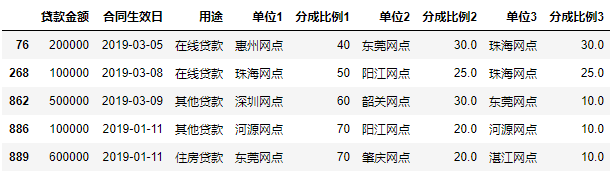
3.3数据表拆分
下一步,我们需要处理分成比例问题了。此案例的重点也是在这里。按照 1.3节 Python优化报表制作过程中的分析,我们需要先将贷款金额分别与分成单位1、2、3及分成比例1、2、3组成三张分表。数据表的拆分代码很简单。直接用普通索引将需要的列传导给分表就可以了。
data1=data[["用途","贷款金额","单位1","分成比例1"]]
data2=data[["用途","贷款金额","单位2","分成比例2"]]
data3=data[["用途","贷款金额","单位3","分成比例3"]]
对data1表进行预览
data1.head()
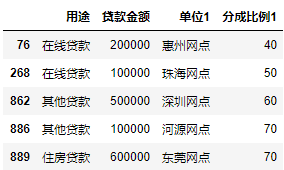
对data2表进行预览
data2.head()
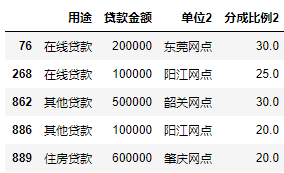
对data3表进行预览
data3.head()
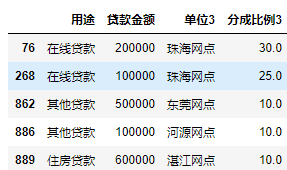
3.4数据追加合并
接下来我们需求是将三个分离的表进行纵向的拼接。在我们的例子中,需要将三个表的单位及分成比例字段追加在同一列。但是目前三个新表中的单位及分成比例字段名字是不一致的,不能直接追加。所以我们需要先将分表的名字统一。
3.4.1重命名列索引
在Python中重命名,使用rename()函数。并使用键值对的方式对columns参数进行赋值。将各分表的单位字段统一命名为单位,分成比例字段统一命名为分成比例。
data1=data1.rename(columns={"单位1":"单位","分成比例1":"分成比例"})
data2=data2.rename(columns={"单位2":"单位","分成比例2":"分成比例"})
data3=data3.rename(columns={"单位3":"单位","分成比例3":"分成比例"})
预览data3表
data3.head()
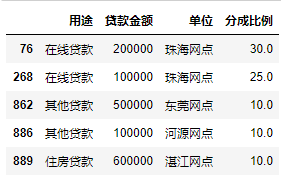
3.4.2纵向拼接分表
通过以上重命名操作,三个分表列名已经一致,这时我们可以将三个表格纵向追加起来。纵向追加使用concat()函数,并使用参数ignore_index重置行索引。
data4=pd.concat([data1,data2,data3],ignore_index=True)
预览合并后的表
data4.head()
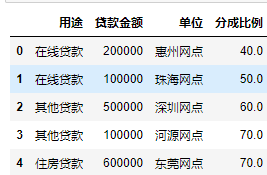
3.5数据分组/透视
3.5.1空值处理
此时利用info()返回的数据可以判断data4是否存在空值。从以下运行结果来看,data4数据表格共5019行,贷款金额及贷款用途都含有5019行非空值,说明者两列都没有空值出现。而单位及分成比例只有2041行数据为非空。其他行为空值。根据业务逻辑可知,如果单位列数据为空,则一定不存在分成比例,即:分成比例也为空。那么该条记录就是无效的。因此可以直接将其删除。使用dropna()函数进行空值处理。
data4.info()
---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5019 entries, 0 to 5018
Data columns (total 4 columns):
用途 5019 non-null object
贷款金额 5019 non-null int64
单位 2041 non-null object
分成比例 2041 non-null float64
dtypes: float64(1), int64(1), object(2)
memory usage: 156.9+ KB
对空值进行删除
data4=data4.dropna() # 此处对不设置 how="all",因为此场景中只要出现空值,就将记录删除。从以下输出结果可知存在空值的记录已经被删除。
查看删除后表的信息
data4.info()
---
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2041 entries, 0 to 3365
Data columns (total 4 columns):
用途 2041 non-null object
贷款金额 2041 non-null int64
单位 2041 non-null object
分成比例 2041 non-null float64
dtypes: float64(1), int64(1), object(2)
memory usage: 79.7+ KB
3.5.2插入新列
接下来一步是计算分成贷款金额,即:我们需要插入一列,使其等于贷款金额列剩余分成比例。注意到分成比例并非百分比格式,我们需要将其转化为百分比(除以100)。插入新列可以使用insert()函数,也可以直接以索引的方式进行。为了演示,我们分别选择不同的方法插入百分比列及分成贷款金额列。
- 使用insert()插入百分比列
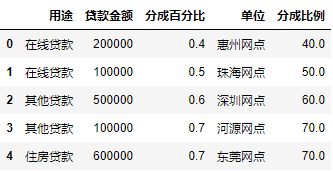
data4.insert(2,"分成百分比",data4["分成比例"]/100)
对插入数据后的表进行预览
data4.head()
- 使用普通索引方式插入分成贷款金额列
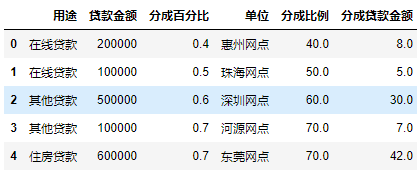
data4["分成贷款金额"]=data4["贷款金额"]*data4["分成百分比"]/10000 # 除以10000,将结果单位换算为万元
对插入数据后的表进行预览
data4.head()
3.5.3数据透视
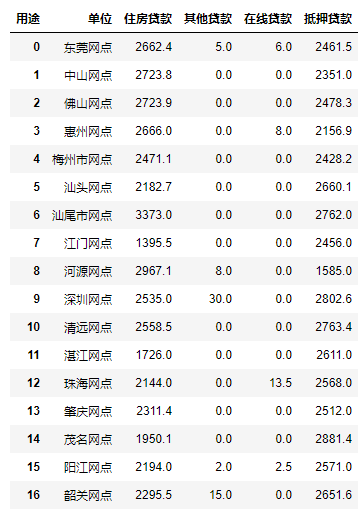
至此,数据清洗过程基本上已经完成了,接下来只需要对数据进行分组透视啦。这里还是遵循排除干扰的原则,先使用普通索引的方式提取需要用到的列,排除不必要的干扰。然后使用pivot_table()设置相关参数进行透视。
data5=data4[["单位","用途","分成贷款金额"]]
pd.pivot_table(data5,values="分成贷款金额",columns="用途",index="单位",aggfunc='sum').fillna(0).reset_index() #将无投放数据的地方填充为0
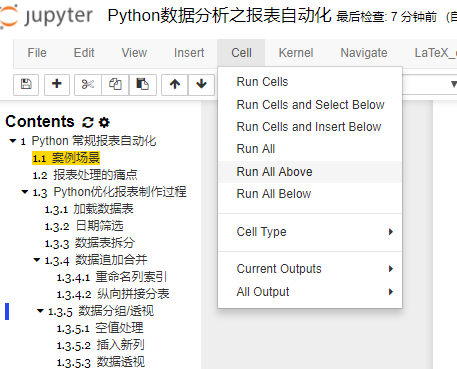
至此,我们的任务就完成了。至于结果输出部分,我们可以选择直接复制黏贴到结果表上。当然也可以使用to_excel()将输出结果保存为excel文件。甚至我们还可以导入xlrd模块,直接对我们的日报表进行修改输出。这里就不多做演示了,请读者们自己动起手来。模型建立好以后,我们只需要将最新的个人贷款客户信息表放置在E盘,覆盖旧的数据文件。然后按下图所示点击 Run All 执行以上代码就可以一键完成我们每天需要的日报了。
其实以上模型处理除了可以计算年累计投放数据以外,我们还可以通过修改日期筛选的范围。一键统计每日、每周或者每季度的报表。
需要本篇数据集的可以去本书github里面随书数据集里面下载。github地址:https://github.com/junhongzhang/Excel-Python-DA
**-----**------**-----**---**** End **-----**--------**-----**-****
往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/z-Gh7cfj6OzM4RscAioYzg,如有侵权,请联系删除。