

专栏作者:zch,经管专业研一在读,Python数据分析及可视化爱好者。公众号后台回复入群,拉你进技术群与大佬们近距离交流。
有的时候,我们需要对不同国家或地区的某项指标进行比较,可简单通过直方图加以比较。但直方图在视觉上并不能很好突出地区间的差异,因此考虑地理可视化,通过地图上位置(地理位置)和颜色(颜色深浅代表数值差异)两个元素加以体现。在本文案例中,基于第三方库pyecharts,对中国各省2010-2019年的GDP进行绘制。
我们先来看看最终效果:
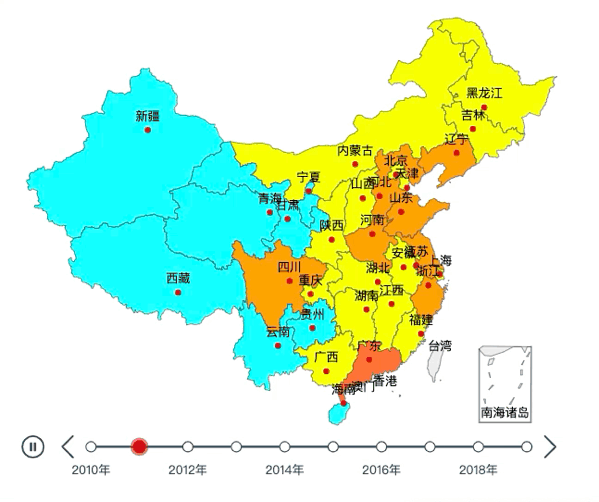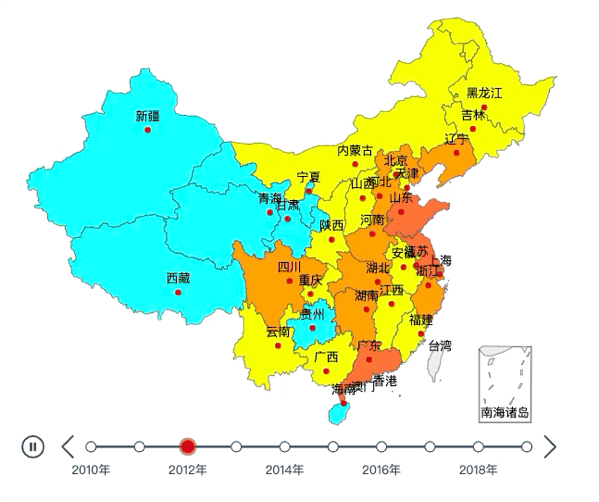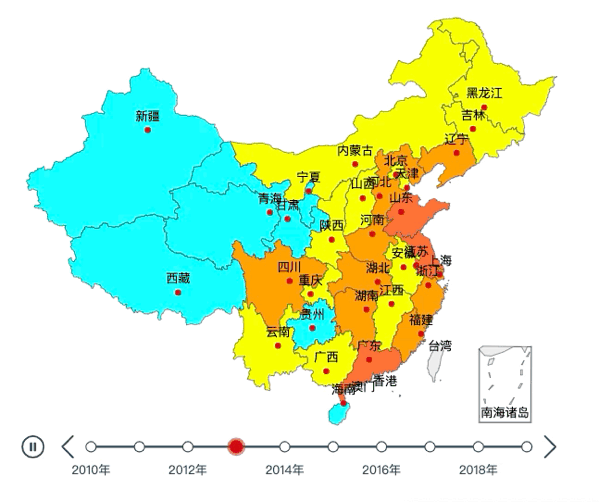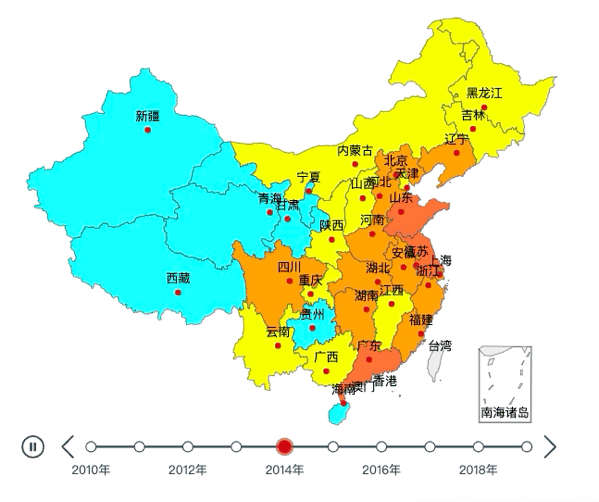
01
关于绘图数据
基于时间和截面两个维度,可把数据分为截面数据、时间序列及面板数据。在本文案例中,某一年各省的GDP属于截面数据,多年各省的GDP属于面板数据。因此,按照先易后难的原则,先对某一年各省的GDP进行地理可视化,再进一步构建for循环对多年各省的GDP进行可视化,形成最终的时间轮播图。
数据来源:本文案例使用的GDP数据来源于国家统计局官网,可在线下载到本地,保存为csv或excel格式,用pandas中的DataFrame进行读取。
02
地理可视化
一、全国各省单年GDP的可视化
在pyecharts中可使用Map类型实现地理可视化,其原理是通过不同颜色填充以展现不同的数据,options实现图表的调整及修饰。代码展示如下:
import pandas as pd
from pyecharts.charts import Map
import pyecharts.options as opts
frame = pd.read_csv('C:\\Users\\dell\\Desktop\\分省年度数据2.csv',encoding='GBK')
map = Map()
map.add("我国地区的GDP",frame[['地区','2019年']].values.tolist(),"china")
map.set_global_opts(visualmap_opts=opts.VisualMapOpts(min_=500,max_=12000))
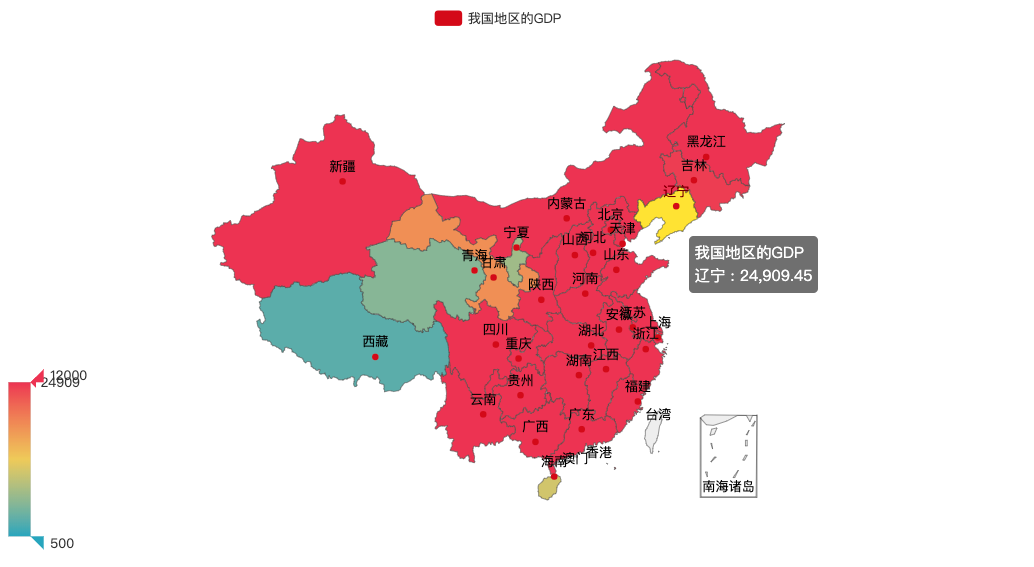
map.render("2019年全国各地区GDP.html")解析:add()来实现了数据的加载,在配置3个参数中——第1个是图的标题,第2个通过.values.tolist()加载要显示的数据,第3个"china"确保显示的地图类型是中国。有个细节需要注意,Map 使用的中国各省份需要将全部的省、市、自治区等去掉。set_global_opts()实现了用颜色标记数据的数值大小,参数min_和max_分别代表最小值和最大值。render()用于生成并保存图像。
效果如下:
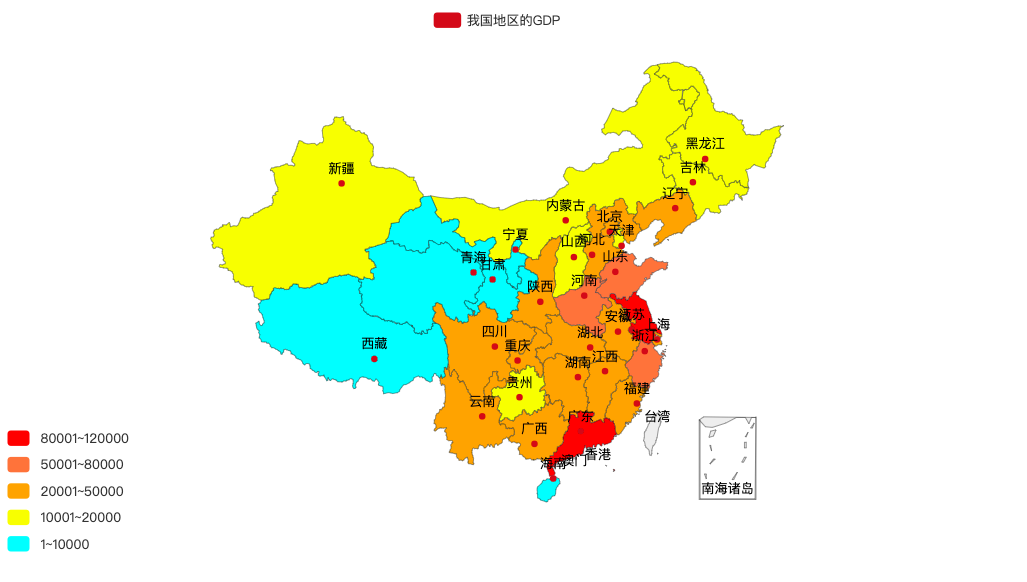
然而数据分布并不平均,可以通过is_piecewise 属性表述分段自定义不同的颜色区间:
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(
is_piecewise=True,
pieces=[
{"min":0,"max":10000,"label":"1~10000","color":"cyan"},
{"min":10001,"max":20000,"label":"10001~20000","color":"yellow"},
{"min":20001,"max":50000,"label":"20001~50000","color":"orange"},
{"min":50001,"max":80000,"label":"50001~80000","color":"coral"},
{"min":80001,"max":120000,"label":"80001~120000","color":"red"},
]
))效果如下:
二、全国各省多年GDP的可视化
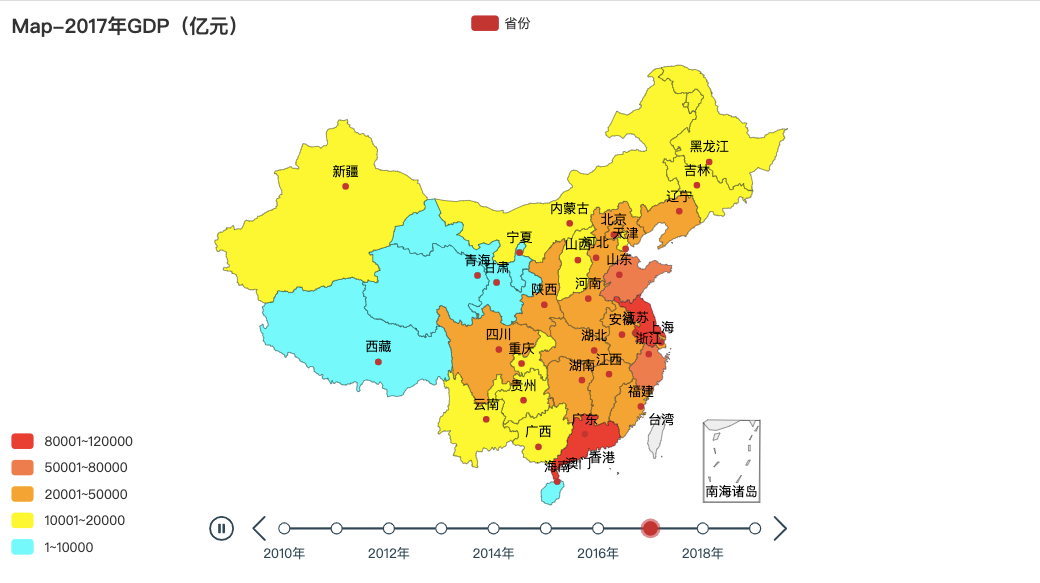
由于要绘制2010-2019年的GDP数据,可以考虑构建一个for循环,通过str(i)+"年"的形式访问数据表格中处于不同列的各年GDP数据。绘制轮播图可考虑调用Timeline,代码如下:
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Map, Timeline
frame = pd.read_csv('C:\\Users\\dell\\Desktop\\分省年度数据2.csv',encoding='GBK')
tl = Timeline()
for i in range(2010, 2020):
map0 = (
Map()
.add("省份",frame[['地区',str(i)+'年']].values.tolist(), "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="Map-{}年GDP(亿元)".format(i)),
visualmap_opts=opts.VisualMapOpts(
is_piecewise=True,
pieces=[
{"min":0,"max":10000,"label":"1~10000","color":"cyan"},
{"min":10001,"max":20000,"label":"10001~20000","color":"yellow"},
{"min":20001,"max":50000,"label":"20001~50000","color":"orange"},
{"min":50001,"max":80000,"label":"50001~80000","color":"coral"},
{"min":80001,"max":120000,"label":"80001~12000","color":"red"},
] ),))
tl.add(map0, "{}年".format(i))
tl.render("2010~2019年全国各地区GDP.html")效果如下:
03
小结
本案例的实现并不复杂,在pyecharts官方的参考案例基础上稍加改动即可实现。作为一名初学者,模仿案例是提升功力的重要途径,通过模仿可以有效吃透代码要具体实现的功能,量变到质变,就能根据自己工作和学习的需要进行灵活应用。
**-----**------**-----**---**** End **-----**--------**-----**-****

往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/oNFkNMvsXJG77CS9B0bbKg,如有侵权,请联系删除。











