一、前言
大家好,我是崔艳飞。工作中经常会遇到,需要把两张Excel或Csv数据表通过关键字段进行关联,匹配对应数据的情况,Excel虽有Vlookup函数可以处理,但数据量大时容易计算机无响应,可能出现数据丢失,处理速度较慢是软肋,而Python只需几行代码就能轻松实现,且处理速度快,详细如下。
二、项目目标
用Python实现两张Excel或Csv表数据关联处理。
三、项目准备
软件:PyCharm
需要的库:pandas
四、项目分析
1)如何读取要处理的Csv文件?
利用pandas库读取Csv文件。
2)如何读取要处理的Excel文件?
利用pandas库读取Excel文件。
3)如何通过关键字段关联匹配两张表中的数据?
利用merge()函数,通过关键字段,关联组合两张表中的数据。
4)如何保存结果?
利用to_csvl保存关联组合后的数据。
五、项目实现
1、第一步导入需要的库
import pandas as pd2、第二步读取要处理的Csv文件
# 读入表1
df1 = pd.read_csv('D:/a/1.csv', encoding='gbk')3、第三步读取要处理的Excel文件
# 读入表2
df2 = pd.read_excel('D:/a/2.xlsx', encoding='utf-8')4、第四步关联匹配数据,并保存结果文件
# 关联数据
data = df1.merge(df2, on='姓名',left_index=False, right_index=False, sort=False)
# 保存数据
data.to_csv('D:/a/result.csv', encoding='gbk',index=False)六、效果展示
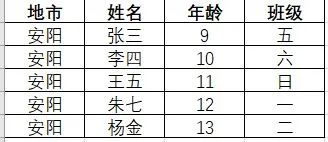
1、处理前表1数据:
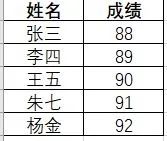
2、处理前表2数据:
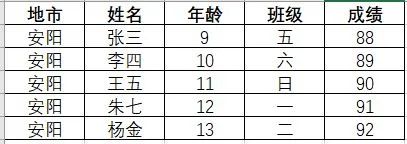
3、处理后的关联匹配数据:
七、总结
本文介绍了如何利用Python进行Excel和Csv间的数据关联处理,替代了Excel的Vlookup函数,由于不用显示源文件,节省了系统资源,处理效率更高,数据量越大,优势越明显,Python还有很多类似的函数,数据处理,唯快不破,有兴趣的同学可以研究下,有问题随时留言,一起讨论学习。
最后需要本文项目代码的小伙伴,请在公众号后台回复“Vlookup”关键字进行获取,如果在运行过程中有遇到任何问题,请随时留言或者加小编好友,小编看到会帮助大家解决bug噢!
**-----**------**-----**---**** End **-----**--------**-----**-****

往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/g9UDBMbV9gJI1JaAl7wkwg,如有侵权,请联系删除。