
###1. count运算上的区别: 因为MyISAM缓存有表meta-data(行数等),因此在做COUNT(*)时对于一个结构很好的查询是不需要消耗多少资源的。而对于InnoDB来说,则没有这种缓存。
###2. 是否支持事务和崩溃后的安全恢复: MyISAM 强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但不提供事务支持。InnoDB 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
###3. 是否支持外键: MyISAM不支持,而InnoDB支持。
MyISAM:只支持表级锁,不支持行锁。用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁 (读取时对需要读到的所有表加锁,写入时则对表加排他锁;)
不支持事务
不支持外键
不支持崩溃后的安全恢复
在表有读取查询的同时,支持往表中插入新纪录
支持BLOB和TEXT的前500个字符索引,支持全文索引
支持延迟更新索引,极大地提升了写入性能
对于不会进行修改的表,支持 压缩表 ,极大地减少了磁盘空间的占用
- 计算机(Mysql)协调多个进程或线程并发访问某一表或某行数据的机制
表锁: 每次操作锁住整张表。开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
行锁: 每次操作锁住一行数据。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高;
- 支持行锁,采用MVCC来支持高并发,有可能死锁
- 支持事务
- 支持外键
- 支持崩溃后的安全恢复 不支持全文索引
###B-Tree索引:下图为B+Tree 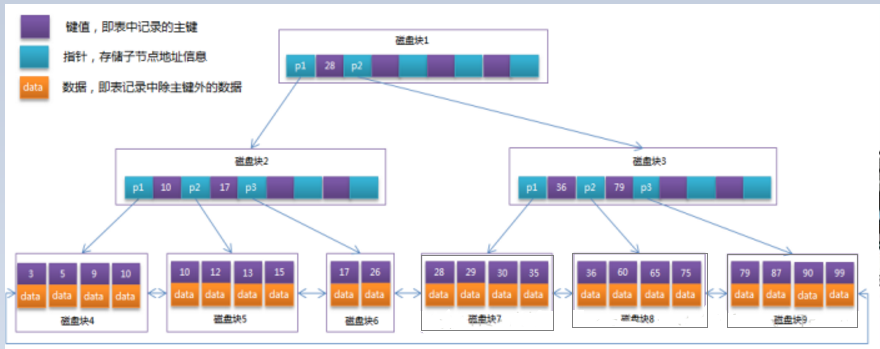
MyISAM: B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
InnoDB: 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引(非聚集索引),辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
限定数据的范围: 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内。;
读/写分离: 经典的数据库拆分方案,主库负责写,从库负责读;
缓存: 使用MySQL的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存;
垂直分区: 根据数据库里面数据表的相关性进行拆分。 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。 简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表
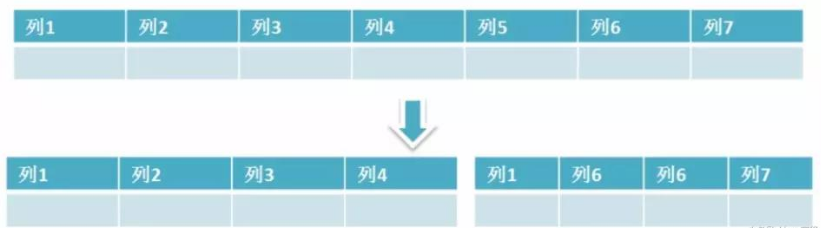
垂直拆分的优点: 可以使得行数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
- 水平分区: 保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。 水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。
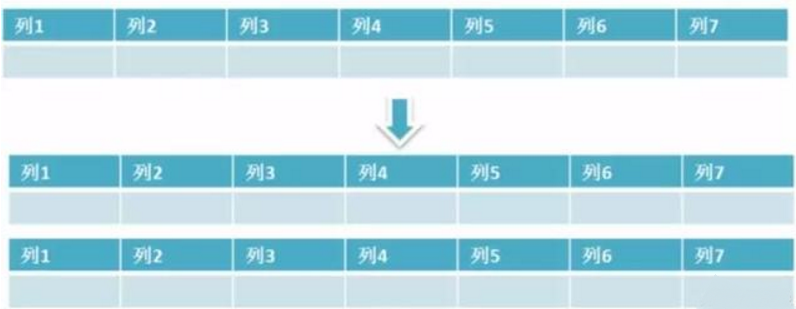
水品拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 水品拆分最好分库 。 水平拆分能够 支持非常大的数据量存储,应用端改造也少,但 分片事务难以解决 ,跨界点Join性能较差,逻辑复杂。














